









Você pode monitorar o status do cluster usando a interface do usuário de gerenciamento do dispositivo do VMware Cloud Director.
Procedimento
- Faça login como root na interface do usuário de gerenciamento do dispositivo em https://primary_eth1_ip_address:5480.
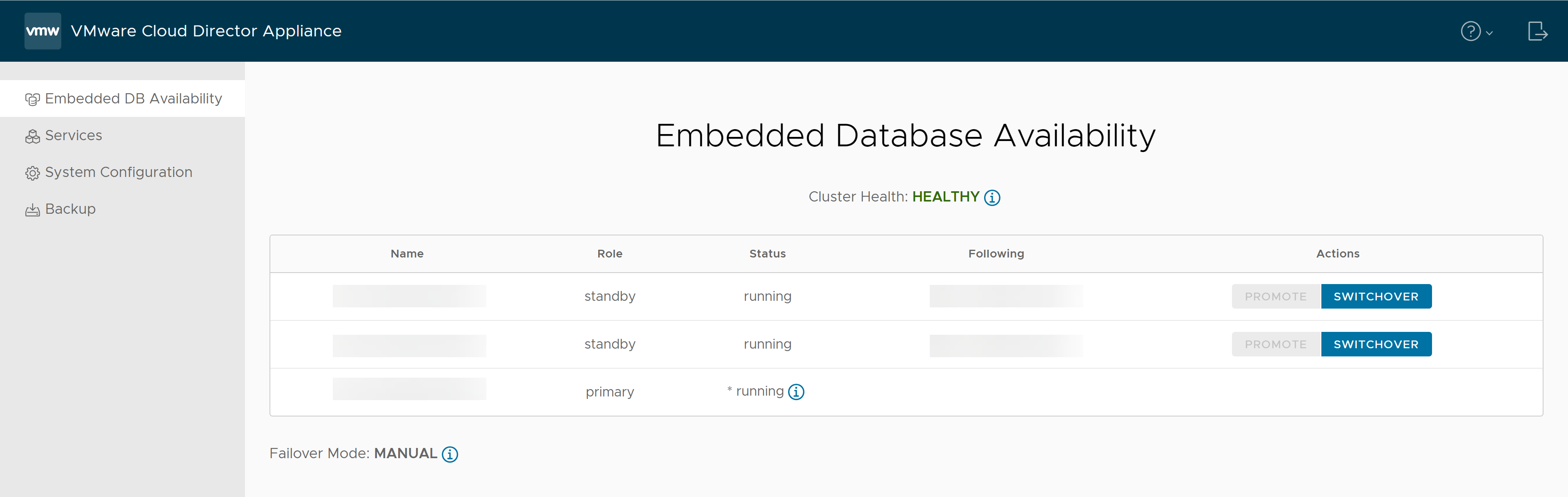
- No painel esquerdo, selecione Disponibilidade do Banco de Dados Incorporado.
Você pode exibir os nomes DNS curtos dos nós, suas funções, seu status, o nome do respectivo nó upstream, ou seja, o nó primário atual, bem como as ações disponíveis nos nós.
Na coluna Seguintes, um ponto de interrogação (?) na frente do nome do host indica que o nó primário atual está inacessível. Um sinal de exclamação (!) na frente do nome do host indica que os metadados do nó primário atual não estão atualizados e podem estar incorretos ou que o nó não está conectado ao nó primário atual. O problema poderá ocorrer se você reiniciar o nó após um tempo de inatividade prolongado. Se o nó não puder se conectar ao nó principal, você deverá cancelar o registro dele e substituí-lo por um novo em espera.
- Visualize a integridade do cluster.
Status de Integridade do Cluster Descrição Healthy O cluster está em um estado íntegro. A célula primária e ambas as células de espera estão online e operacionais.
A interface do usuário e a API do VMware Cloud Director estão funcionais.
Degraded O cluster está em um estado degradado. As células primária e uma das células de espera estão online e operacionais, mas a outra célula de espera não está funcional. O banco de dados primário está funcionando nesse estado, mas, se houver outra falha de banco de dados de qualquer uma das células operacionais, o primário não se tornará não funcional. A célula de espera não funcional deve ser substituída por uma nova célula de espera em funcionamento o mais rápido possível para restaurar o cluster para um estado
Healthy.A interface do usuário e a API do VMware Cloud Director estão funcionais.
No_Active_Primary Não há banco de dados primário operacional. Se houver duas células de espera operacionais, uma delas deverá ser promovida para se tornar a nova célula primária. Se o ambiente não tiver duas células de espera operacionais, você deverá diagnosticar o problema e corrigir a situação manualmente.
A interface do usuário e a API do VMware Cloud Director estão não estão disponíveis.
Read_Only_Primary Existe um banco de dados primário online, mas ele é
Read_Onlyporque o ambiente não tem uma célula de espera operacional. Duas novas células de espera devem ser implantadas.A interface do usuário e a API do VMware Cloud Director estão não estão disponíveis.
Critical_Problem O cluster está em um estado inconsistente. Por exemplo, mais de uma célula primária está online ou uma célula de espera está seguindo a célula primária errada. Você deve diagnosticar o problema e corrigir a situação manualmente.
Esse estado pode afetar a disponibilidade da interface do usuário e da API do VMware Cloud Director.
SSH_Problem O problema do SSH indica que o usuário postgres não pode se conectar aos seus nós de banco de dados peer via SSH. Você deve corrigir esse problema crítico o mais rápido possível. Consulte A integridade do seu cluster do VMware Cloud Director indica um problema de SSH.
A UI e a API do VMware Cloud Director podem não estar totalmente funcionais.
- Visualize o modo de failover do dispositivo.
Modo de failover Descrição Automático Se ocorrer uma falha no banco de dados primário, o VMware Cloud Director acionará automaticamente um failover de banco de dados. Manual Se ocorrer uma falha no banco de dados primário, você deverá iniciar um failover de banco de dados usando a interface do usuário de gerenciamento de dispositivo do VMware Cloud Director ou a API de failover. Indeterminado O modo de failover não é consistente em todos os nós do cluster. Você deve diagnosticar o problema e corrigir a situação. Usando a API do dispositivo do VMware Cloud Director, redefina o FailoverModecomoManualouAutomatic. Consulte as informações do Modo de Failover no Referência de esquemas de API do dispositivo do VMware Cloud Director.
