









Para permitir que os desenvolvedores implantem cargas de trabalho de IA/ML em clusters TKG 2, como administrador do vSphere, você configura o ambiente do Supervisor para oferecer suporte ao hardware de GPU NVIDIA.
Etapa 1 do administrador: analisar os requisitos do sistema
| Requisito | Descrição |
|---|---|
| vSphere 8 infraestrutura |
hosts vCenter Server e ESXi |
| Licença de gerenciamento de carga de trabalho |
vSphere Namespaces e Supervisor |
| TKR Ubuntu OVA | |
| Driver de host NVIDIA vGPU |
Faça download do VIB do site do NGC. Para obter mais informações, consulte a documentação do driver de software vGPU. |
| NVIDIA License Server para vGPU |
FQDN fornecido pela sua organização |
Etapa 2 do administrador: instalar o dispositivo de GPU NVIDIA compatível em ESXi hosts
Para implantar cargas de trabalho de IA/ML no TKG, instale um ou mais dispositivos de GPU NVIDIA compatíveis em cada ESXi host que compreende o vCenter Cluster em que o Gerenciamento de carga de trabalho (Workload Management) será ativado.
Para visualizar os dispositivos de GPU NVIDIA compatíveis, consulte o VMwareGuia de Compatibilidade.
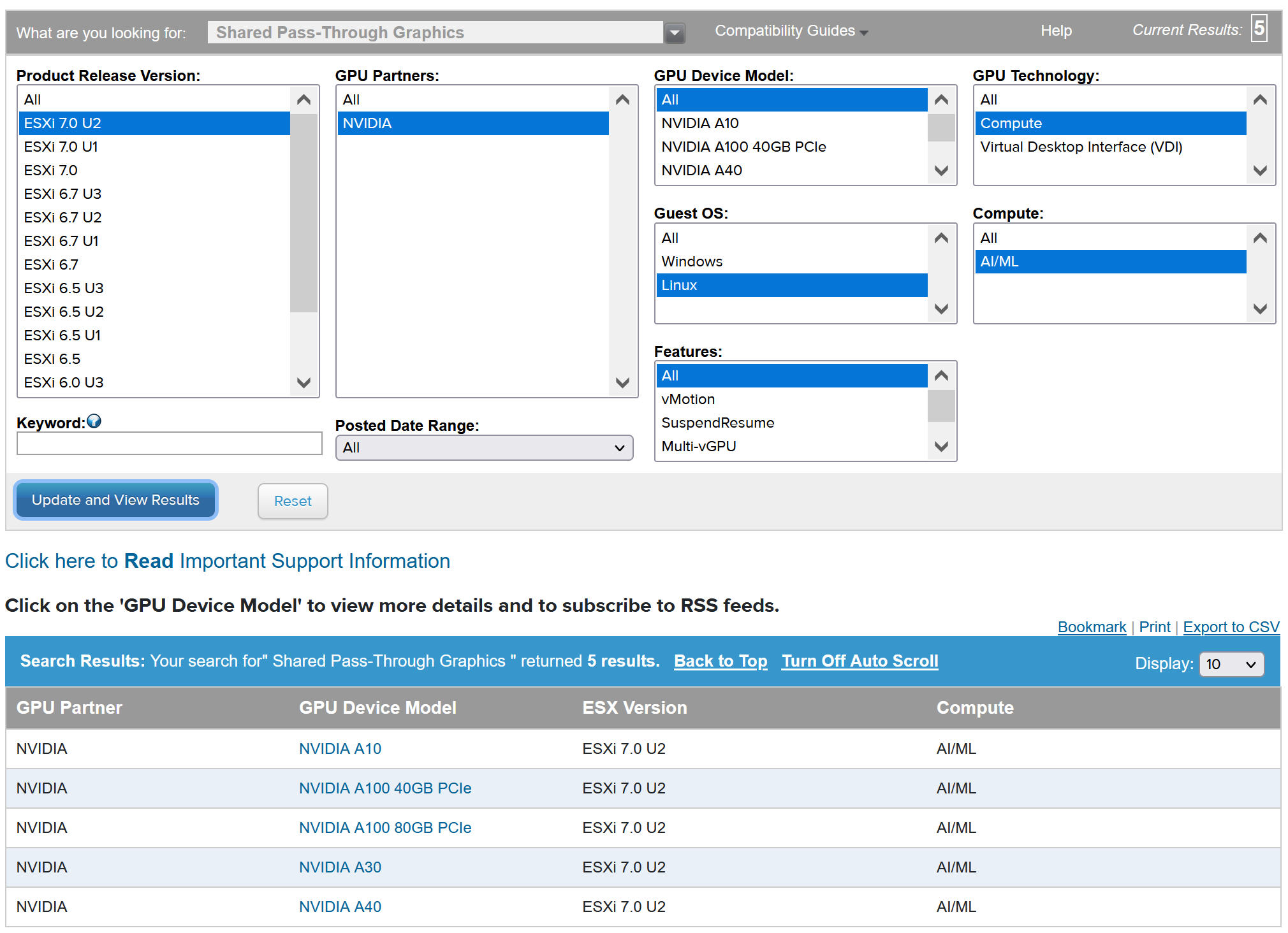
O dispositivo de GPU NVIDA deve oferecer suporte aos perfis de vGPU do NVIDIA AI Enterprise (NVAIE) mais recentes. Consulte a documentação GPUs compatíveis com o software GPU virtual NVIDIA para obter orientação.
Por exemplo, o seguinte host ESXi tem dois dispositivos NVIDIA GPU A100 instalados nele.
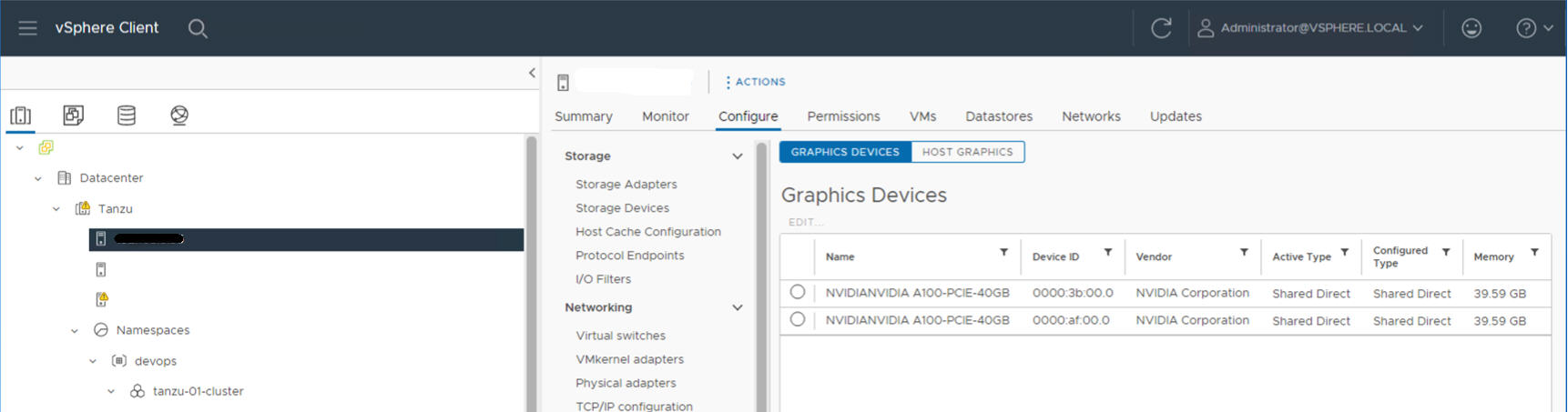
Etapa 3 do administrador: configurar cada host ESXi para operações de vGPU
Configure cada host ESXi para vGPU ativando o Shared Direct e o SR-IOV.
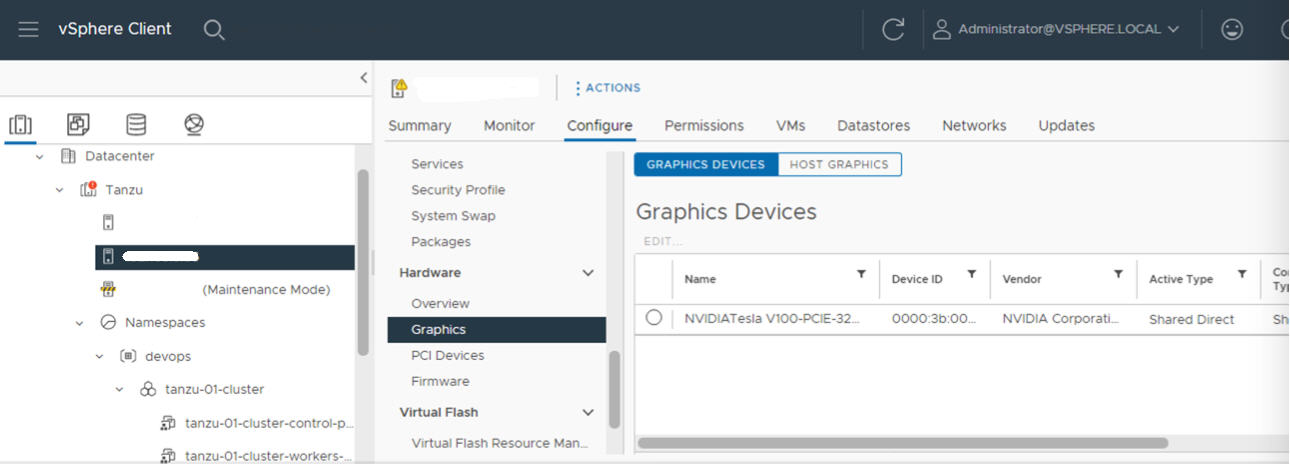
Ativar o Shared Direct em cada ESXi Host
Para que a funcionalidade da NVIDIA vGPU seja desbloqueada, ative o modo Shared Direct em cada host ESXi que compreende o vCenter Cluster em que o Workload Management será ativado.
- Faça logon no vCenter Server usando o vSphere Client.
- Selecione um host ESXi no cluster vCenter.
- Selecione .
- Selecione o dispositivo acelerador de GPU NVIDIA.
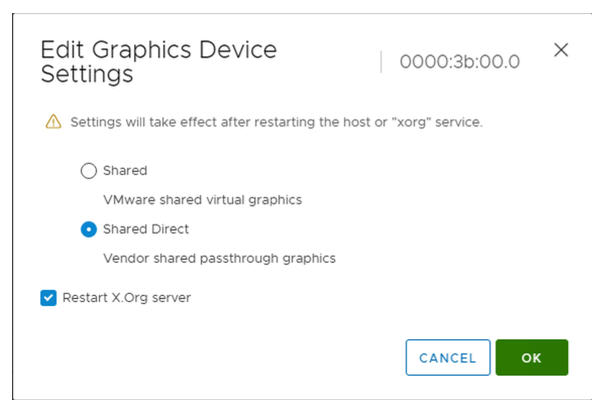
- Edite as configurações do dispositivo gráfico.
- Selecione Shared Direct.
- Selecione o servidor Reiniciar X.Org (Restart X.Org).
- Clique em OK para salvar a configuração.
- Clique com o botão direito do mouse no host ESXi e coloque-o no modo de manutenção.
- Reinicie o host.
- Quando o host estiver em execução novamente, retire-o do modo de manutenção.
- Repita esse processo para cada host ESXi no cluster vCenter em que o Gerenciamento de carga de trabalho (Workload Management) será ativado.
Ativar BIOS SR-IOV para dispositivos NVIDIA GPU A30 e A100
Se estiver usando os dispositivos de GPU NVIDIA A30 ou A100, que são necessários para a GPU de várias instâncias (modo MIG), você deve habilitar o SR-IOV no o host ESXi. Se o SR-IOV não estiver ativado, as VMs de nó de cluster Tanzu Kubernetes não poderão ser iniciadas. Se isso ocorrer, você verá a seguinte mensagem de erro no painel Tarefas recentes do vCenter Server em que o Gerenciamento de carga de trabalho está ativado.
Could not initialize plugin libnvidia-vgx.so for vGPU nvidia_aXXX-xx. Failed to start the virtual machine. Module DevicePowerOn power on failed.
Para habilitar o SR-IOV, faça login no host ESXi usando o console da web. Selecione . Selecione o dispositivo GPU NVIDIA e clique em Configurar SR-IOV (Configure SR-IOV). A partir daqui, você pode ativar o SR-IOV. Para obter orientações adicionais, consulte Virtualização de E/S de raiz única (SR-IOV) na documentação do vSphere.
vGPU com Dynamic DirectPath IO
- Faça login no vCenter Server usando o vSphere Client.
- Selecione o host ESXi de destino no cluster vCenter.
- Selecione .
- Selecione a guia Todos os dispositivos PCI.
- Selecione o dispositivo acelerador de GPU NVIDIA de destino.
- Clique em Alternar passagem (Toggle Passthrough).
- Clique com o botão direito do mouse no host ESXi e coloque-o no modo de manutenção.
- Reinicie o host.
- Quando o host estiver em execução novamente, retire-o do modo de manutenção.
Etapa 4 do administrador: Instalar o driver do NVIDIA Host Manager em cada host ESXi
Para executar VMs de nó de cluster Tanzu Kubernetes com aceleração gráfica NVIDIA vGPU, instale o driver do gerenciador de host NVIDIA em cada host ESXi que compreende o vCenter Cluster em que o Gerenciamento de carga de trabalho será ativado.
Os componentes do driver do gerenciador de host NVIDIA vGPU são empacotados em um pacote de instalação vSphere (VIB). O NVAIE VIB é fornecido a você por sua organização por meio do programa de licenciamento NVIDIA GRID. A VMware não fornece VIBs NVAIE nem as disponibiliza para download. Como parte do programa de licenciamento da NVIDIA, sua organização configura um servidor de licenciamento. Consulte o Guia de início rápido do software GPU virtual da NVIDIA para obter mais informações.
esxcli system maintenanceMode set --enable true esxcli software vib install -v ftp://server.domain.example.com/nvidia/signed/NVIDIA_bootbank_NVIDIA-VMware_ESXi_7.0_Host_Driver_460.73.02-1OEM.700.0.0.15525992.vib esxcli system maintenanceMode set --enable false /etc/init.d/xorg restart
Etapa 5 do administrador: verificar se os hosts do ESXi estão prontos para operações da NVIDIA vGPU
- SSH no host ESXi, entre no modo shell e execute o comando
nvidia-smi. A NVIDIA System Management Interface é um utilitário de linha de comando fornecido pelo gerenciador de host NVIDA vGPU. A execução desse comando retorna as GPUs e os drivers no host. - Execute o seguinte comando para verificar se o driver NVIDIA está instalado corretamente:
esxcli software vib list | grep NVIDA. - Verifique se o host está configurado com GPU compartilhada direta e se o SR-IOV está ativado (se você estiver usando dispositivos NVIDIA A30 ou A100).
- Usando o vSphere Client, no host ESXi configurado para GPU, crie uma nova máquina virtual com um dispositivo PCI incluído. O perfil NVIDIA vGPU deve aparecer e ser selecionável.
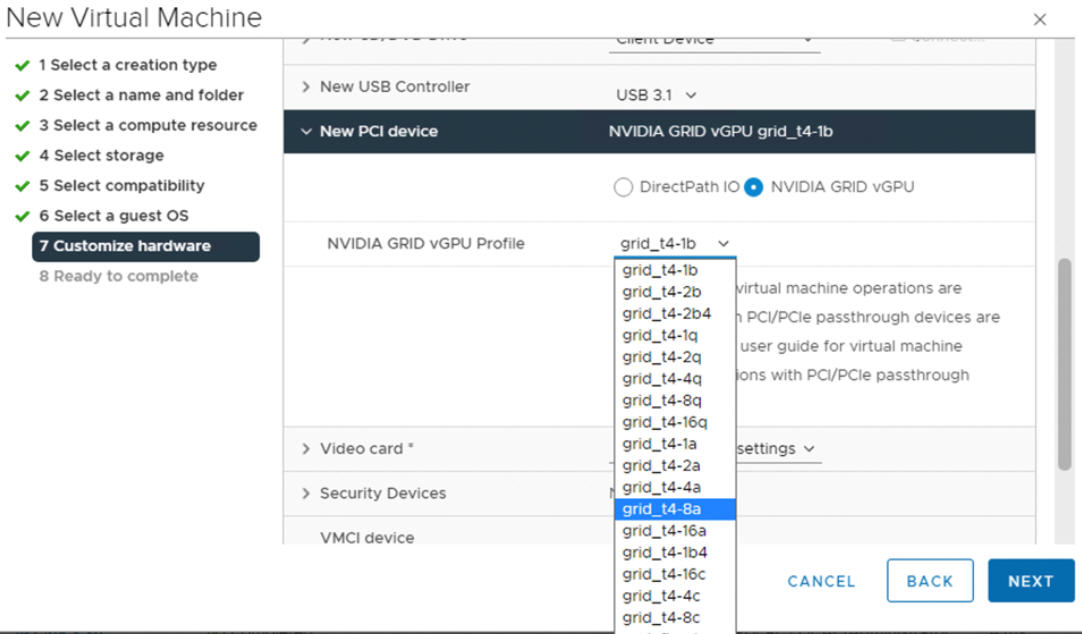
Etapa 6 do administrador: ativar o gerenciamento de carga de trabalho
Etapa 7 do administrador: Criar ou atualizar uma biblioteca de conteúdo com um TKR Ubuntu
A NVIDIA vGPU requer o sistema operacional Ubuntu. Não é possível usar a edição PhotonOS de uma versão Tanzu Kubernetes para clusters de vGPU.
VMware fornece edições do Ubuntu de Tanzu Kubernetes versões. A partir do vSphere 8, a edição do Ubuntu é especificada usando uma anotação no YAML do cluster.
Etapa 8 do administrador: criar uma classe de VM personalizada com o perfil de vGPU
A próxima etapa é criar uma classe de VM personalizada com um perfil de vGPU. O sistema usará essa definição de classe ao criar os nós de cluster Tanzu Kubernetes.
- Faça login no vCenter Server usando o vSphere Client.
- Selecione Gerenciamento de carga de trabalho.
- Selecione Serviços.
- Selecione Classes de VMs.
- Clique em Criar classe de VM.
- Na guia Configuração, configure a Classe de VM personalizada.
Campo de Configuração Descrição Nome Digite um nome autodescritivo para a classe de VM personalizada, como vmclass-vgpu-1. Contagem de vCPU 2 Reserva de recursos de CPU Opcional, OK para deixar em branco Memória 80 GB, por exemplo Reserva de recursos de memória 100% (obrigatório quando dispositivos PCI são configurados em uma classe de VM) Dispositivos PCI Sim Observação: A seleção de Sim para dispositivos PCI informa ao sistema que você está usando um dispositivo GPU e altera a configuração da Classe da VM para oferecer suporte à configuração da vGPU.Por exemplo:
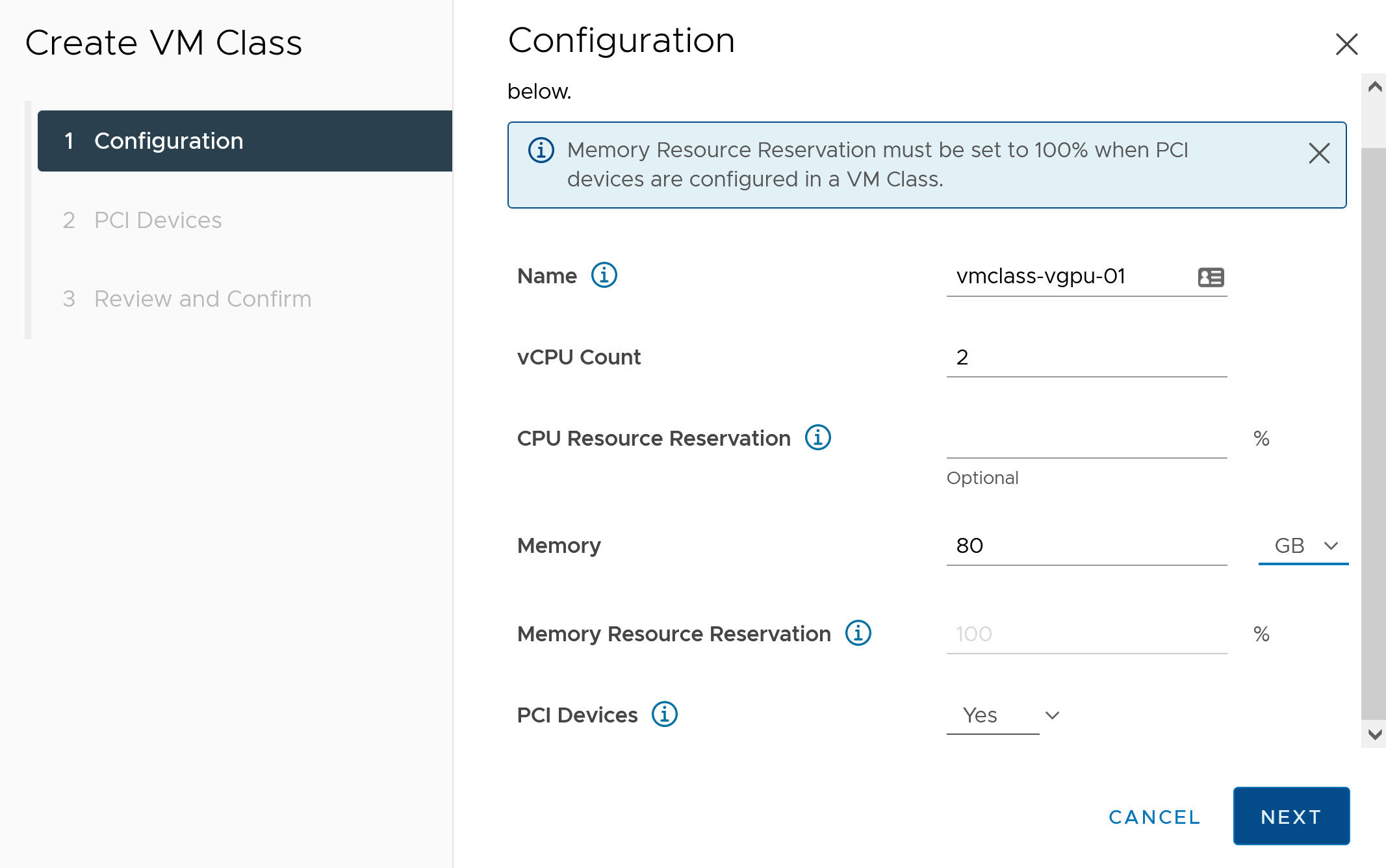
- Clique em Avançar.
- Na guia Dispositivos PCI, selecione a opção .
- Configure o modelo da NVIDIA vGPU.
Campo NVIDIA vGPU Descrição Modelo Selecione o modelo do dispositivo de hardware da GPU NVIDIA entre os disponíveis no menu . Se o sistema não mostrar nenhum perfil, nenhum dos hosts no cluster terá suporte a dispositivos PCI. Compartilhamento de GPU Essa configuração define como o dispositivo de GPU é compartilhado entre VMs habilitadas para GPU. Há dois tipos de implementações de vGPU: Time Sharing e Multi-Instance GPU Sharing.
No modo de compartilhamento de tempo, o programador de vGPU instrui a GPU a realizar o trabalho para cada VM habilitada para vGPU em série por um período de tempo com a meta de melhor esforço de balancear o desempenho entre vGPUs.
O modo MIG permite que várias VMs habilitadas para vGPU sejam executadas em paralelo em um único dispositivo GPU. O modo MIG é baseado em uma arquitetura de GPU mais recente e é compatível apenas com dispositivos NVIDIA A100 e A30. Se a opção MIG não for exibida, o dispositivo PCI selecionado não é compatível com ela.
Modo GPU Cálculo Memória da GPU 8 GB, por exemplo Número de vGPUs 1, por exemplo Por exemplo, aqui está um perfil NVIDIA vGPU configurado no modo Time Sharing:
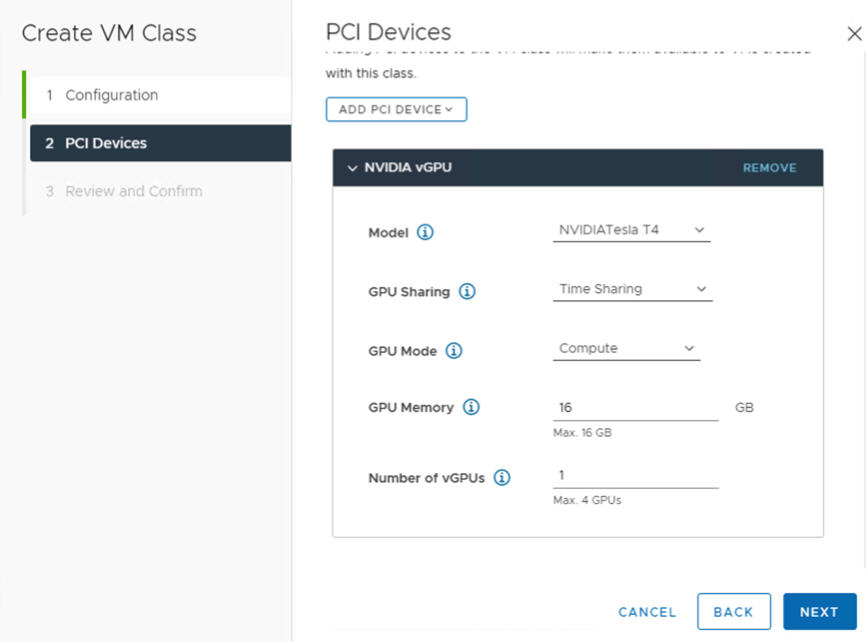
Por exemplo, aqui está um perfil NVIDIA vGPU configurado no modo MIG com dispositivo GPU compatível:
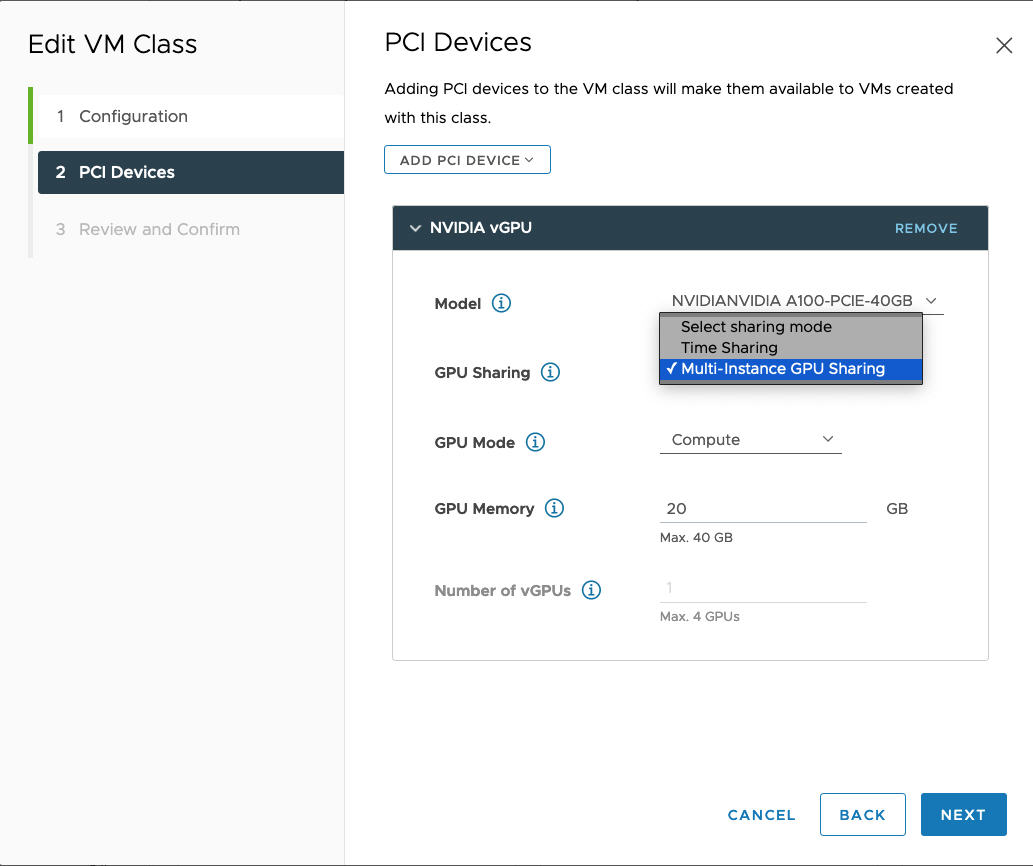
- Clique em Avançar.
- Revise e confirme suas seleções.
- Clique em Concluir.
- Verifique se a nova Classe de VM personalizada está disponível na lista de Classes de VM.
vGPU com Dynamic DirectPath IO
- Selecione Gerenciamento de carga de trabalho.
- Selecione Serviços.
- Selecione Classes de VMs.
- Edite a classe de VM personalizada que já está configurada com o perfil NVIDIA vGPU.
- Selecione a guia Dispositivos PCI.
- Clique em Adicionar dispositivo PCI (Add PCI Device).
- Selecione a opção Dynamic DirectPath IO.
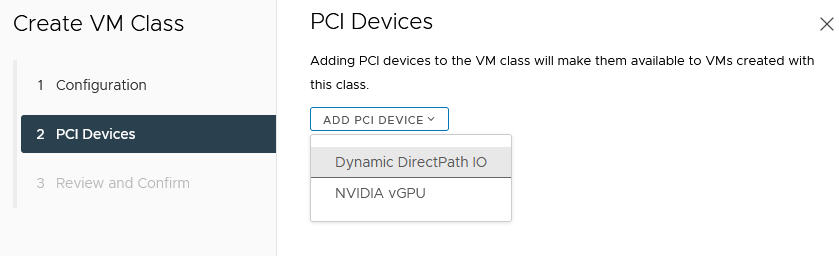
- Selecione o Dispositivo PCI.
Por exemplo:
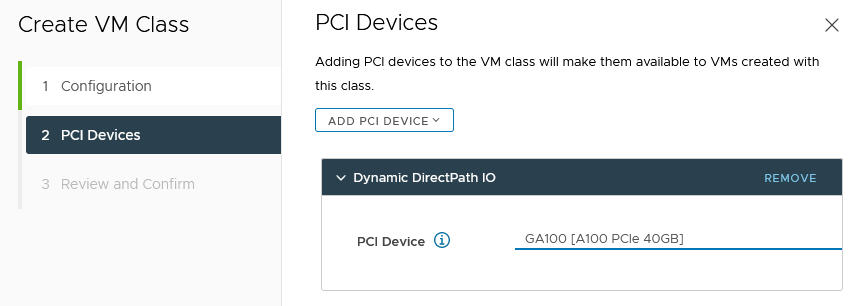
- Clique em Avançar.
- Revise e confirme suas seleções.
- Clique em Concluir.
- Verifique se a nova Classe de VM personalizada está disponível na lista de Classes de VM.
Etapa 9 do administrador: criar e configurar um vSphere Namespace
Crie um vSphere Namespace para cada cluster de vGPU TKG que você planeja provisionar. Configure o vSphere Namespace adicionando vSphere usuários/grupos de SSO com permissões de Edição e anexe uma política de armazenamento para volumes permanentes. Associe a biblioteca de conteúdo do TKR e a classe de VM personalizada ao vSphere Namespace. Consulte Configurando vSphere Namespaces para clusters TKG 2 em Supervisor.
Etapa 10 do administrador: Verificar se o Cluster do Supervisor está acessível
A última tarefa de administração é verificar se o Supervisor está provisionado e disponível para uso pelo Operador de Cluster para provisionar um cluster TKG para cargas de trabalho de IA/ML.
Consulte Conectando-se a clusters TKG em Supervisor usando a autenticação de SSO do vCenter.
