性能是为了确保工作负载获取必要的资源,而性能管理在很大程度上是一项消除活动。该方法对每一层进行划分,并确定该层是否导致出现性能问题。必须具有单个衡量指标用于指示某个特定层是否正常运行。此主要衡量指标恰当地命名为关键性能指标 (KPI)。

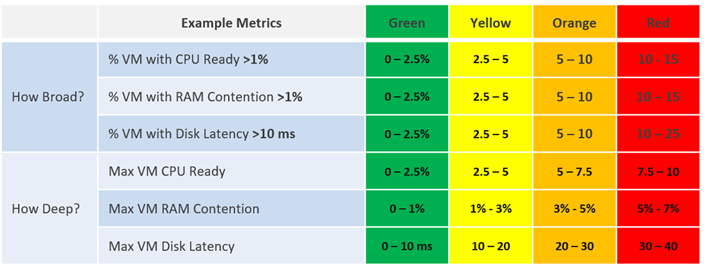
每个衡量指标(如磁盘延迟)有四个范围:绿色、黄色、橙色和红色。
为了便于监控,该范围对应于 0–100%。绿色对应于 75–100%,红色对应于 0-25%。将 100% 分为四个相等的范围,使每个范围都具有适当的大小条带。
上述技术支持将具有不同单位的衡量指标组合在一起。其中每个对应于同一条带,即一个百分比。
将衡量指标正确对应于四个范围的逻辑需要五个衡量指标,而不是四个。例如,在磁盘延迟中:
-
如果为 41 毫秒,则为 0%(红色),因为红色的上限为 40 毫秒。
-
如果为 35 毫秒,则为 12.5%,因为位于 30 毫秒和 40 毫秒的中间,并且为红色。
-
如果为 30 毫秒,则为 25%,因为位于红色和橙色的边框上。
将每个衡量指标转换为 0–100% 范围后,可利用平均值(而不是峰值)得出 KPI 衡量指标。使用平均值是为了避免任何衡量指标在 KPI 值中占主导地位。如果有衡量指标对您的运维至关重要,则可以对此使用警示。使用平均值可反映实际情况,因为每个衡量指标的占比相同。
这些仪表板使用 KPI 来显示使用者层的 Horizon 会话性能以及 Horizon 基础架构层的工作负载整体性能。这些仪表板专为 Horizon 架构师或首席管理员而设计。它们提供桌面即服务的数据中心部分的整体性能。
从性能管理角度看 Horizon
对于性能监控和故障排除,Horizon 类似于客户端/服务器架构,其中客户端通过 WAN 网络。网络和数据中心组件相互独立,它们使用不同的衡量指标集,并且必须单独作为一个实体进行监控。它们有自己的一组修复操作。在大型企业中,网络由单独的团队负责。
之后,Management Pack for Horizon 单独进行监控,提供 KPI。

客户端组件是性能监控的最后一个焦点,因为它本质上就像一台电视机。它显示传输的像素,并接受简单的输入。此外,客户端问题往往为孤立问题。但是,网络和数据中心中断可能会影响许多用户。
性能故障排除的三个流程
性能管理包括三个不同的流程,分别是:
-
计划:在此流程设置性能目标。当您构建 vSAN 时,想要磁盘延迟是多少毫秒?在虚拟机级别(而不是 vSAN 级别)衡量的 10 毫秒是良好的开端。
-
监控。在此流程比较计划与实际情况。实际情况是否与架构所要交付的内容匹配?如果不匹配,必须对其进行修复。
-
故障排除。当实际情况比计划糟糕时执行此流程,而不是有人投诉时才执行。您不希望在故障排除上花费时间,因此最好主动执行。

性能管理的两个衡量指标
性能的主要计数器是争用。大多数客户都关注利用率,因为他们担心如果利用率很高,可能会出现错误。这就是争用。争用以不同的形式呈现。可以是队列、延迟、已丢弃、已中止或环境切换。
不要将利用率指标超高与性能问题混淆。仅仅因为 ESXi 主机出现内存膨胀、压缩和交换,并不意味着您的虚拟机存在内存性能问题。您可以根据主机为其虚拟机提供服务的情况来衡量主机的性能。虽然与 ESXi 利用率相关,但性能衡量指标不是基于利用率,而是基于争用衡量指标。

集群中的虚拟机可能出现性能不佳的情况,而集群利用率较低。一个主要原因是集群利用率考虑提供者层 (ESXi),而性能考虑单个使用者(虚拟机)。

从性能管理的角度来看,vSphere 集群是资源中最小的逻辑构造块。虽然资源池和虚拟机主机关联性可以提供更小的单元,但在操作上非常复杂,而且无法提供承诺的 IaaS 服务质量。资源池无法提供差异化服务类别。例如,您的 SLA 规定高级桌面比普通桌面快两倍,因为其价格高出 200%。资源池可为高级桌面提供两倍的份额。无法预先确定那些转换为 CPU 就绪的一半的额外份额。
深度和广度
主动监控需要从多个角度进行洞察。如果用户遇到性能导致的问题,您接下来应提出的问题是:
-
有多糟糕?您想要衡量问题的深度。
-
有多少个用户受到影响?您想要衡量问题的广度。
第二个问题的答案会影响故障排除过程。是孤立事件还是普遍存在?如果是孤立问题,则可以更密切地查看受影响的对象。如果是普遍问题,则可以查看受影响对象之间共享的通用区域(例如集群、数据存储、资源池和主机)。
请注意,您没有问平均性能是多少?因为,在此情况下,平均值已为时已晚。等到平均性能不佳时,可能已有一半的用户受到影响。
当成员数量很大时,Count() 的作用要优于 Percentage()。例如,在一个具有 10 万用户的 VDI 环境中,受影响的用户为五个,占 0.005%。使用计数更容易监控,因为您可以了解实际情形。
整体流
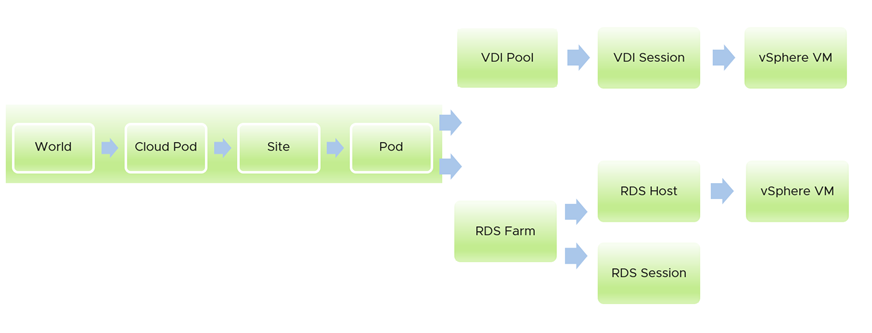
Management Pack for Horizon 仪表板并非孤立设计。它们形成一个流,随着您向下钻取传递上下文。以下示例以鸟瞰视图展示了如何下钻至支持会话的底层虚拟机。第一个仪表板涵盖了 Horizon 环境中的所有容器。从该仪表板,可以下钻至 RDS 场或 VDI 池。在每个分支中,可以下钻至单个会话。
设计注意事项
所有性能仪表板都采用相同的设计原则。它们特意采用类似设计,因为如果每个仪表板的外观不同,会让人感到困惑。仪表板具有相同的目标。
仪表板采用自上而下进行设计,包含摘要和详细信息部分。
-
摘要部分通常放在仪表板的顶部,便于您了解整体情况。
-
详细信息部分放在摘要部分下方。可在其中下钻至某个特定对象。例如,如果是虚拟机的性能,可以获取特定虚拟机的详细性能。
此外,在此详细信息部分中还设计了快速环境切换,以便于您在性能故障排除期间检查多个对象的性能。例如,“RDS 主机性能”仪表板提供了所有 RDS 主机特定信息,并且无需更换屏幕即可查看 KPI。您可以从一个 RDS 主机移至另一个 RDS 主机并查看详细信息,而无需打开多个窗口。
从用户界面的角度讲,仪表板使用渐进式呈现来最大程度地减少信息过载,并确保网页快速加载。只要您的浏览器会话保持活动状态,就会记住您的最后选择。
颜色作为含义
当使用不同的阈值时,仪表板使用颜色传达含义。
| 计数器 | 使用的阈值 |
|---|---|
| KPI | 绿色:75% - 100% 黄色:50% - 75% 橙色:25% - 50% 红色:0% - 25% 相应地,阈值集为 25%、50% 和 75%。 |
| 红色范围内的项目计数。例如,具有红色 KPI 的 VDI 会话计数。 |
此值应始终为 0,因为任何 VDI 会话的 KPI 值都不应位于红色范围内。相应地,阈值集为 1、2、3。 如果您希望在计数为 1 时显示红色,则可以将其设置为 0.1、0.2 或 1。 |
显示的数字应位于绿色区域内 (75%-100%)。平均值可能不是 100%,但目标是在绿色范围内。
表作为见解
表只是一个列表,其中每一行表示一个对象,每一列显示一个值。这将列出数百行,并且能够筛选和排序。每个单元格值也可以采用颜色编码。
表适用于呈现详细信息。但是,总的来说,主要问题是如何随着时间的推移提供见解,因为每个单元格只能容纳一个值。如何深入了解过去发生的情况?例如,如何查看过去 1 周的性能?过去 7 天内有数千个数据点,应挑选哪个数据点?
vRealize Operations Cloud 8.2 中有几个可能的选项
-
当前数字。说明当前情况非常有用。但是,不会说明五分钟前发生的情况。
-
一段时间内的平均值。平均值是一个滞后指标。等到平均值不佳时,大约有一半的数字都可能不佳。
-
一段时间内的最差值。此方法可能过于极端,因为它只需要一个峰值。在某些情况下,数百个数据点中有一个数字可能是异常值。此方法适用于峰值检测,但需要进行补充。
-
第 95 百分位。这是一个介于平均值和最差值之间的不错中间点。对于性能监控,第 95 百分位比平均值能更好地提供性能摘要。
请同时使用最差值和第 95 百分位数,从第 95 百分位数开始。如果这两个数字相差很大,则表明最差值可能是异常值。
为了更好地了解,请考虑添加第 98 百分位以补充第 95 百分位和最差值。
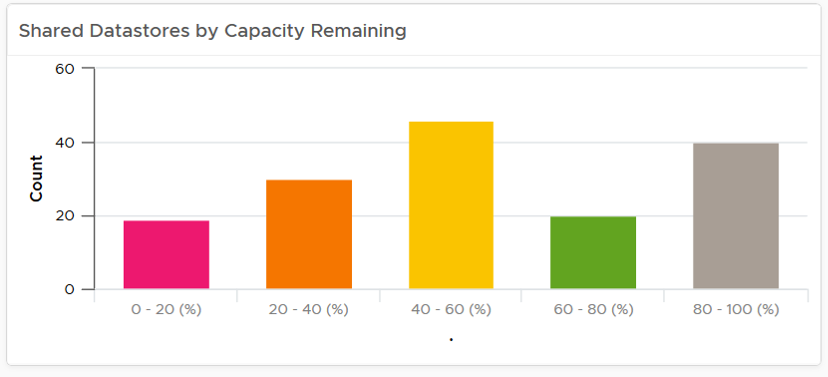
条形图作为见解
分布图有很多形状,其中条形图是最常见的一种。可使用条形图深入剖析大型数据集。例如,vSphere 共享数据存储按剩余容量显示。它们分为五段,从最小剩余容量到最大剩余容量。每段都分配有一种颜色来传达含义。大于 80% 的容量用灰色表示,因为大量容量未使用表示资源浪费。