









如果云管理员已在 VMware Aria Automation 中设置 Private AI Automation Services,则可以使用 Automation Service Broker 目录请求 AI 工作负载。
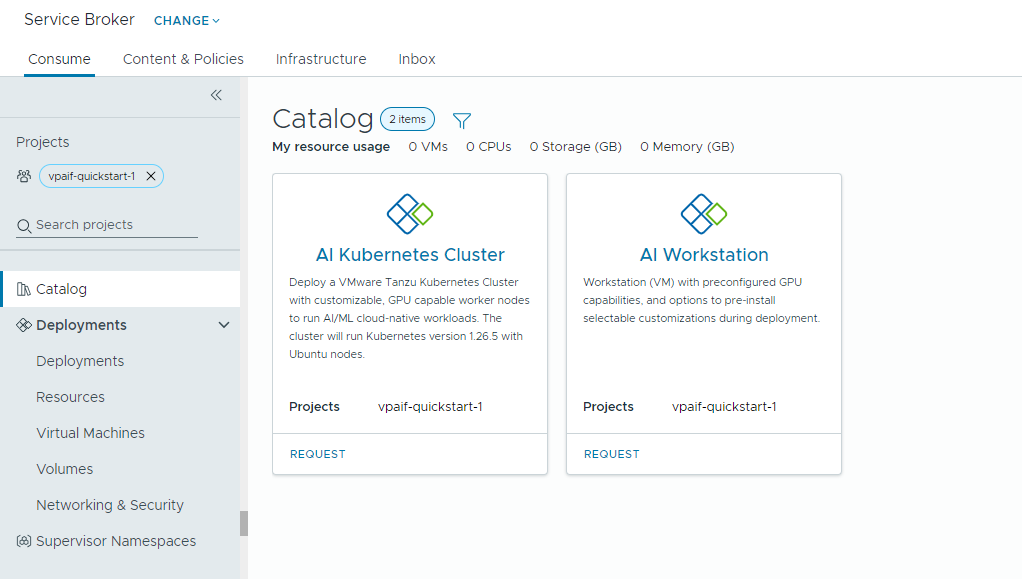
Private AI Automation Services 支持 Automation Service Broker 中的两个目录项,具有相应权限的用户可以访问和请求这些目录项。
- AI Workstation - 启用了 GPU 的虚拟机,可以从 NVIDIA 配置所需的 vCPU、vGPU、内存和 AI/ML 软件。
- AI Kubernetes 集群 – 启用了 GPU 的 Tanzu Kubernetes 集群,可以配置 NVIDIA GPU Operator。
开始之前
- 确认已为您的项目配置 Private AI Automation Services,并且您有权请求 AI 目录项。
请记住,此处的所有值均为用例示例。您的帐户值取决于您的环境。
将深度学习虚拟机部署到 VI 工作负载域
数据科学家可以从自助 Automation Service Broker 目录中部署单个 GPU 软件定义的开发环境。您可以使用计算机参数自定义启用了 GPU 的虚拟机以模拟开发要求,指定 AI/ML 软件配置以满足培训和推理要求,以及通过门户访问密钥从 NVIDIA NGC 注册表指定 AI/ML 软件包。
过程
部署启用了 AI 的Tanzu Kubernetes集群
DevOps 工程师可以请求启用了 GPU 的 Tanzu Kubernetes 集群,Worker 节点可在这些集群中运行 AI/ML 工作负载。
TKG 集群包含一个 NVIDIA GPU 运算符,它是 Kubernetes 运算符,负责为 TKG 集群节点上的 NVIDIA GPU 硬件设置正确的 NVIDIA 驱动程序。部署的集群可用于 AI/ML 工作负载,而无需进行额外的 GPU 相关设置。
过程
- 找到 AI Kubernetes 集群卡视图,然后单击请求。
- 选择一个项目。
- 输入部署的名称和描述。
- 选择控制窗格节点数。
设置 示例值 节点计数 1 虚拟机类 cpu-only-medium - 8 CPUs and 16 GB Memory 选择的类将定义虚拟机中的可用资源。
- 选择工作节点数。
设置 说明 节点计数 3 虚拟机类 a100-medium - 4 vGPU (64 GB), 16 CPUs and 32 GB Memory - 单击提交。
结果
部署中包含一个主管命名空间、一个具有三个 Worker 节点的 TKG 集群、TKG 集群内的多个资源以及一个用于部署 GPU Operator 应用程序的 carvel 应用程序。
监控您的专用 AI 部署
可以使用“部署”页面管理部署和关联的资源,对部署进行更改,对失败的部署进行故障排除,对资源进行更改以及销毁未使用的部署。
要管理部署,请选择。
有关详细信息,请参见如何管理我的 Automation Service Broker 部署。
