









VMware Cloud on AWS Autoscaler 服务可监控 SDDC 基础架构的运行状况,检测早期故障和实际故障,并通过在故障发生之前或之后更换主机来自动修复基础架构。
AWS 基础架构安全可靠,但即使在最可靠的基础架构中也难免出现故障。AWS 架构框架可靠性支柱讨论了云可靠性的设计原则。VMware Cloud on AWS 对底层基础架构进行了抽象化并利用 vCenter Server 和 ESXi 的预测性故障分析功能,扩展了这些原则,可在发生故障时提供响应式修复,并提供可防止故障影响工作负载的预测性修复。
大多数自动修复过程都在后台执行,并且在不影响现有工作负载的情况下执行。自动修复可监控系统的运行状况,并在必要时快速地将硬件添加到 SDDC,从而在发生故障或检测到运行状况问题时将新主机插入到集群中,并将工作负载虚拟机从已发生故障或即将发生故障的硬件中撤出。此外,由于所有
VMware Cloud on AWS SDDC 都使用 VMware
vSAN 和 vSphere HA,因此受主机故障影响的工作负载会自动重新放置并重新启动。
注: 您无需为用于自动修复或计划内维护的额外主机付费。
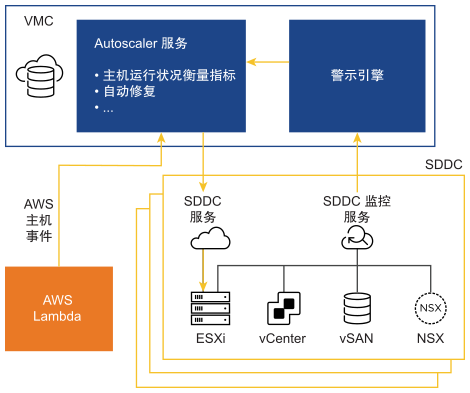
自动修复高级架构
自动修复架构包括由 AWS 和 VMware 提供的组件。
- AWS 向 VMware 发送主机级别信息,特别是 AWS 计划内维护事件。Autoscaler 服务接收这些通知,并自动修复 SDDC 中的所有问题。
- SDDC 级别的监控服务从底层 VMware Cloud on AWS 组件接收通知。
响应式修复
响应式自动修复可监控硬件故障和软件故障,并尝试通过多种方式修复问题。自动修复是一个内部过程,并且不断发展。VMware Cloud on AWS 用户无权访问工作流或其配置,但为了帮助您更好地了解该工作流,下面简要概述了当前涉及的步骤。
- 1:监控
- VMware Cloud on AWS 持续监控 SDDC 中每个主机的运行状况。检测到故障时,事件将发送到自动修复功能。
- 2:等待暂时性事件
- 某些检测到的故障可能是暂时的。例如,由于临时的连接问题,监控系统无法访问主机。自动修复会等待五分钟,以确定问题是否是暂时性的。如果是,自动修复将返回而不执行任何操作。
- 3:添加主机
- 如果错误在五分钟后未解决,自动修复会开始向 SDDC 添加主机。以这种方式预先添加主机可确保主机在需要时可用。请注意,在更换 SDDC 中出现故障的主机之前,不会对此主机进行计费。
- 4:确定故障类型并执行操作
- 主机可能会由于各种不同的原因而发生故障,因此需要执行不同的操作。例如,仍然连接到 vCenter Server 的主机上的 vSAN 磁盘故障可以通过软重启进行修复,而 PSOD 主机需要硬重启。
- 5:检查主机运行状况
- 下一步是检查修复操作是否修复了主机。如果故障主机在软重启或硬重启后正常运行,则自动修复可避免进一步中断 SDDC。它会收集并采取任何其他必要操作,并移除在步骤 3 中预先添加的新主机。
- 6:更换主机
- 如果无法恢复出现故障的主机,则 Autoscaler 将移除出现故障的主机,并将其更换为在步骤 3 中添加的主机。将触发 vSphere HA 和 vSAN,计算策略标记将连接到新主机。
抢先式修复
除了响应式修复外,Autoscaler 还会监控多个独立源,以尝试在故障出现之前发现故障。如果该服务确定主机可能会遇到硬件故障,则会触发无中断抢先式计划内维护事件。在计划内维护完成之前,主机仍可能会出现故障,但通过预先启动主机更换,可以最大限度地降低影响。在计划内维护期间:
- 向集群添加新主机。将标记从要更换的主机复制到此新主机。
- 将故障主机置于维护模式并撤出全部数据。这会将任何虚拟机和/或 vSAN 数据无中断地移至集群内的其他主机。
- 从集群中移除故障主机。
Autoscaler 事件
当 Autoscaler 服务收到故障事件时,它会确定故障类型,然后执行相应的操作。SDDC 活动日志包括所有 Autoscaler 活动,但不显示触发相关活动的故障事件。
- vCenter Server 事件
-
- 触发以检查主机连接状态的事件
- 当 ESXi 主机断开连接或无响应时,将触发事件。
- DAS 事件
-
- vSphere HA 事件:在未与主节点通信或 HA 关闭时创建事件。(FDM)
- 当主机关闭时,HA 系统将报告主机故障。
- vSAN 个事件
-
- 主机上出现磁盘故障时。
- vSAN 主机断开连接时。
- EDRS 事件(非故障)
- 升级:禁用 EDRS。维护活动通常需要额外主机,此主机将添加为维护事件的一部分。EDRS 在任何计划内维护期间均处于禁用状态,以防止这些活动触发缩小/扩大事件。
- AWS 事件
-
- 计划内维护事件。来自 AWS 的通知,指出检测到实例运行状况问题,应撤出该实例。
- Personal Health Dashboard (PHD)。一个事件流,有助于了解各种硬件组件并有助于 VMware 预先发现硬件故障。
- 系统状态检查。监控实例所依赖的 AWS 系统的运行状况。此检查报告只有 AWS 才能修复的问题。在许多情况下,这些问题是暂时性的,无需执行任何操作。
- 实例状态检查。监控每个实例的软件和网络配置。此检查通过定期向网卡发出 ARP 请求来监控实例的可用性。除了报告 EC2 层的实例可用性之外,实例状态检查还会监控底层硬件利用率,并报告网络连接问题、内存耗尽、文件系统损坏和内核错误等。与系统状态检查不同,实例状态检查需要 VMware 交互才能解决。
- SDDC 事件
- vCenter Server 主机运行状况。
