









VMware Integrated OpenStack CLI 运行状况检查运行手册介绍了修复所报告问题的 viocli check health 案例和过程。
您可以针对 viocli check health 中报告的问题运行以下任一解决方案:
节点未就绪
- 要获取节点状态,请运行
osctl get node命令。osctl get node NAME STATUS ROLES AGE VERSION controller-dqpzc8r69w Ready openstack-control-plane 17d v1.17.2+vmware.1 controller-lqb7xjgm9r Ready openstack-control-plane 17d v1.17.2+vmware.1 controller-mvn5nmdrsp Ready openstack-control-plane 17d v1.17.2+vmware.1 vxlan-vm-111-161.vio-mgmt.eng.vmware.com Ready master 17d v1.17.2+vmware.1
- 使用以下命令对
not ready node重新启动 kubelet 服务:viosshcmd ${not_ready_node} 'sudo systemctl restart kubelet' - 要重新检查此问题的状态,请运行
viocli check health -n kubernetes。
节点的 IP 地址重复
有关 IP 地址重复的节点的详细信息,请参见知识库文章 82608。
要重新检查此问题的状态,请运行 viocli check health -n kubernetes。
节点不正常
- 运行
osctl describe node <node>以获取节点的运行状况。Type Status LastHeartbeatTime LastTransitionTime Reason Message ---- ------ ----------------- ------------------ ------ ------- NetworkUnavailable False Sat, 05 Jun 2021 10:47:53 +0000 Sat, 05 Jun 2021 10:47:53 +0000 CalicoIsUp Calico is running on this node MemoryPressure False Mon, 07 Jun 2021 01:21:55 +0000 Mon, 07 Jun 2021 00:57:29 +0000 KubeletHasSufficientMemory kubelet has sufficient memory available DiskPressure False Mon, 07 Jun 2021 01:21:55 +0000 Mon, 07 Jun 2021 00:57:29 +0000 KubeletHasNoDiskPressure kubelet has no disk pressure PIDPressure False Mon, 07 Jun 2021 01:21:55 +0000 Mon, 07 Jun 2021 00:57:29 +0000 KubeletHasSufficientPID kubelet has sufficient PID available Ready True Mon, 07 Jun 2021 01:21:55 +0000 Mon, 07 Jun 2021 00:57:32 +0000 KubeletReady kubelet is posting ready status
- 如果
NetworkUnavailable、MemoryPressure、DiskPressure或PIDPressure状态为 true,表示 Kubernetes 节点处于不正常的状态。因此,您必须检查不正常节点的系统状态和资源使用情况。 - 要重新检查此问题的状态,请运行
viocli check health -n kubernetes。
节点的磁盘使用率较高
- 登录到报告磁盘使用率较高的节点。
#viossh ${node} - 使用
df -h检查磁盘使用情况。 - 移除节点上未使用的文件。
- 要重新检查此问题的状态,请运行
viocli check health -n kubernetes。
Evicted,请联系 VMware 技术支持团队进行修复。
- 登录到 inode 使用率较高的节点。
#viossh ${node} - 使用
df -i /检查 inode 的使用情况。 - 移除节点上未使用的文件。
- 要重新检查此问题的状态,请运行
viocli check health -n kubernetes。
节点有快照
- 登录到 vCenter,然后移除为 VMware Integrated OpenStack 控制器节点生成的快照。
- 如果报告错误 无法连接到 vCenter (fail to connect to vCenter),则必须在 VMware Integrated OpenStack 中检查 vCenter 连接信息。
- 要重新检查此问题的状态,请运行
viocli check health -n kubernetes。
无法解析 FQDN
- 从 VMware Integrated OpenStack 管理节点中,使用以下命令检查 DNS 解析:
#viosshcmd ${node_name} -c "nslookup ${reported_host}" #toolbox -c "dig $host +noedns +tcp" - 如果失败,请检查在 VMware Integrated OpenStack 节点的 /etc/resolve.conf 中配置的 DNS 服务器。
- 要重新检查此问题的状态,请运行
viocli check health -n connectivity。
节点中未同步 NTP
有关 NTP 节点的详细信息,请参见知识库文章 78565。要重新检查此问题的状态,请运行 viocli check health -n connectivity。
无法访问 LDAP
检查 VMware Integrated OpenStack 节点与指定 LDAP 服务器的连接,并确保 VMware Integrated OpenStack 中的 LDAP(用户、凭据)设置正确无误。要重新检查此问题的状态,请运行 viocli check health -n connectivity。
无法访问 vCenter
如果无法访问 vCenter,请检查 VMware Integrated OpenStack 节点与指定 vCenter 的连接,并确保 VMware Integrated OpenStack 中的 vCenter 设置(用户、凭据)正确无误。要重新检查此问题的状态,请运行 viocli check health -n connectivity。
无法访问 NSX
如果无法访问 NSX,请检查 VMware Integrated OpenStack 节点与指定 NSX 服务器的连接,并确保 NSX 设置(用户、凭据)正确无误。要重新检查此问题的状态,请运行 viocli check health -n connectivity。
- 您必须准备好 Integrate VMware Integrated OpenStack with vRealize Log Insight 文档中列出的所有必备条件。
- 要重新检查此问题的状态,请运行
viocli check health -n connectivity。
- 确保 DNS 服务器可以与 VMware Integrated OpenStack API 访问网络通信。
- 您必须准备好启用 Designate 组件文档中列出的所有必备条件。
- 要重新检查此问题的状态,请运行
viocli check health -n connectivity。
rabbitmq 节点中的网络分区不正确
- 要强制重新创建
rabbitmq节点,请在 VMware Integrated OpenStack 管理节点上运行。#osctl delete pod ${reported_rabbitmq_node} - 要重新检查此问题的状态,请运行
viocli heath check -n rabbitmq。
WSREP 集群问题
viocli get deployment 中的部署状态为 Running,请联系 VIO 技术支持团队。否则,请按照以下说明进行操作。
- 从 VMware Integrated OpenStack Manager 节点运行以下命令:
#kubectl -n openstack exec -ti mariadb-server-0 -- mysql --defaults-file=/etc/mysql/admin_user.cnf --connect-timeout=5 --host=localhost -B -N -e "show status;" #kubectl -n openstack exec -ti mariadb-server-1 -- mysql --defaults-file=/etc/mysql/admin_user.cnf --connect-timeout=5 --host=localhost -B -N -e "show status;" #kubectl -n openstack exec -ti mariadb-server-2 -- mysql --defaults-file=/etc/mysql/admin_user.cnf --connect-timeout=5 --host=localhost -B -N -e "show status;"
- 如果
mariadb-server-x的输出wsrep_cluster_size不是 3,请使用以下命令重新创建mariadb节点:#kubectl -n openstack delete pod mariadb-server-x
- 如果三个节点之间的
wsrep_last_commited差距较大,请重新启动mariadb节点或wsrep_last_committed数值较小的节点。#kubectl -n openstack delete pod mariadb-server-x
- 要重新检查此问题的状态,请运行
viocli check health -n mariadb。
OpenStack 数据库中的大表
nova.instances请参阅知识库文章 83768。
glance.images默认情况下,将启用 cron 作业以自动清除 Glance 数据库中的软删除记录。
请检查数据库清除 cron 作业是否已启用并正常运行。
viocli update glance jobs: db_purge: age_in_days: 60 max_rows: 1000 db_purge_images: age_in_days: 60 max_rows: 1000 manifests: cron_job_db_purge: true cron_job_db_purge_images: truecron_job_db_purge用于对除“映像”表之外的 Glance 表启用数据库清除。cron_job_db_purge_images用于对 Glance“映像”表启用数据库清除。--age_in_days NUM仅清除删除时间超过 NUM 天的行。默认值为 30 天。--max_rows NUM从每个表中清除最多 NUM 行。默认为 100。cinder.volumes和cinder.volume_attachment清除 Cinder 数据库的手动步骤
- 备份 Cinder 数据库。
osctl exec -ti mariadb-server-0 -- mysqldump --defaults-file=/etc/mysql/admin_user.cnf -R cinder > /tmp/cinder_backup.sql
- 登录到 cinder-api-xxxxx pod。
osctl exec -ti deploy/cinder-api bash
- 清理 Cinder 数据库。
cinder-manage db purge 60
注:命令用法:cinder-manage db purge
age_in_days。位置参数:
age_in_days清除早于使用时间(以天为单位)的已删除行。可能需要调整
age_in_days,以清理 Cinder 数据库中更多的软删除记录。
控制平面中的旧网络资源过多
有关解决方案,请参见 VMware Integrated OpenStack 7.1 发行说明中的当存在 10k neutron 租户网络时,无法启用 ceilometer。
OpenStack Keystone 无法正常工作
- 您必须尝试以管理员用户身份从工具箱登录到 OpenStack,然后尝试运行
openstack user list和openstack user show等命令。如果登录失败,请收集 Keystone 日志并检查错误消息。 - 获取 keystone-api pod 列表:
#osctl get pod | grep keystone-api
- 收集日志:
#osctl logs keystone-api-xxxx -c keystone-api >keystone-api-xxxx.log
- 要检查此问题的状态,请运行
viocli check health -n keystone。
Neutron 数据库中的网络 ID 为空
对于解决方案,请参见知识库文章 76455。要检查此问题的状态,请运行 viocli check health -n neutron。
Neutron 中的 vCenter 引用错误
- 获取
viocluster名称。如果返回osctl get viocluster
viocluster1,请继续执行下一步。否则,这是一条无效警报。请联系 VMware 技术支持团队,获取永久解决方案。 - 获取
vioclustervCenter 配置。# osctl get viocluster viocluster1 -oyaml
- 备份 Neutron 配置。
osctl get neutron -oyaml > neutron-<time-now>.yml
- 编辑 Neutron CR
cmd:osctl edit neutron neutron-xxx,然后通过替换步骤 1 中找到的 vCenter 引用来更改 CR 规范。spec: conf: plugins: nsx: dvs: dvs_name: vio-dvs host_ip: .VCenter:vcenter812:spec.hostname <---- change the vcenter instance to viocluster refered host_password: .VCenter:vcenter812:spec.password <---- same above host_username: .VCenter:vcenter812:spec.username <---- insecure: .VCenter:vcenter812:spec.insecure <---- - 要检查此问题的状态,请运行
viocli check health -n neutron。
- 获取 Nova Pod。
osctl get pod | grep nova
检查 Nova Pod 是否未处于正在运行状态。
- 使用以下命令删除 Pod:
osctl delete pod xxx。等待新 Pod,直到其状态为正在运行。
- 要检查此问题的状态,请运行
viocli check health -n nova。
Nova 服务失效
有关失效的 Nova 服务,请参见 知识库文章 78736。要检查此问题的状态,请运行 viocli check health -n nova。
- 登录到工具箱,然后尝试查找并删除冗余的 Nova 服务和某些不带端点的 Nova 服务。
# openstack catalog list

# openstack service list

- 查找正在使用的 Nova 服务。
# openstack endpoint list |grep nova
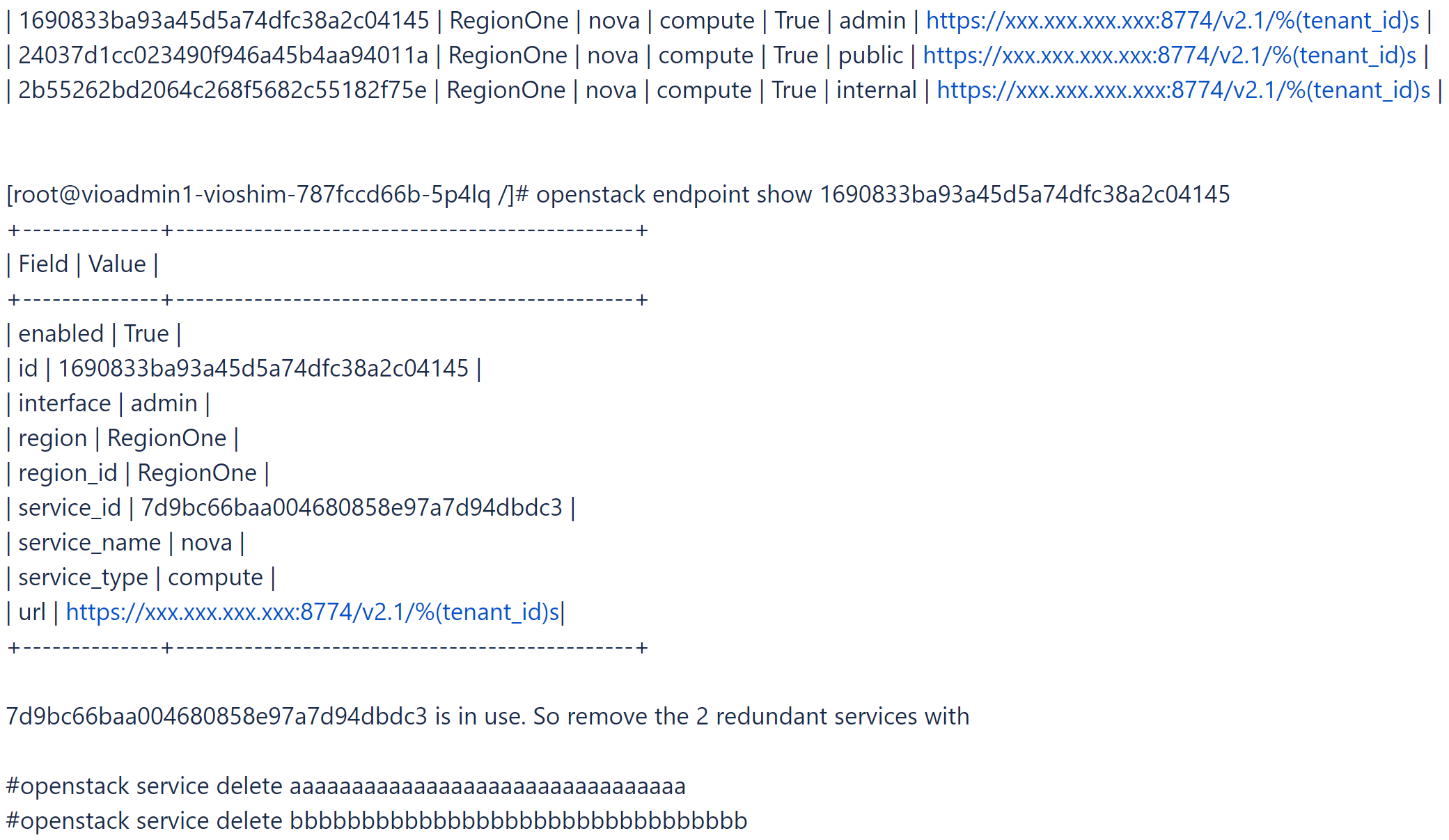
- 要检查此问题的状态,请运行
viocli check health -n nova。
某些 Nova 计算 pod 由于启动超时不断重新启动
此警报指示某些 Nova 计算 pod 可能处于不正常状态。请联系 VMware 技术支持团队,获取解决方案。要检查此问题的状态,请运行 viocli check health -n nova。
Glance 数据存储无法访问
- 获取 Glance 服务列表。
osctl get glance
- 获取 Glance 数据存储信息。
osctl get glance $glance-xxx -o yaml
- 查找数据存储连接信息。
spec: conf: backends: vmware_backend: vmware_datastores: xxxx vmware_server_host: xxxx vmware_server_password: xxxx vmware_server_username: .xxxx - 如果信息不正确,请检查 vCenter 和数据存储连接,并相应地使用
osctl update glance $glance-xxx进行更新。 - 要检查此问题的状态,请运行
viocli check health -n glance。
Glance 映像的位置格式不正确
此消息指示某些 Glance 映像的位置格式不正确。请联系 VMware 技术支持团队,获取解决方案。要检查此问题的状态,请运行 viocli check health -n glance。
Cinder 服务关闭
- 获取 Cinder Pod。
osctl get pod | grep cinder | grep -v Completed
检查 Cinder Pod 是否未处于正在运行状态。
- 使用以下命令删除 Pod:
osctl delete pod xxx。等待新 Pod,直到其状态显示为正在运行。
- 要检查此问题的状态,请运行
viocli check health -n cinder。
- 登录到
cinder-volumePod。#osctl exec -ti cinder-volume-0 bash
- 检查并列出失效的 Cinder 服务。
#cinder-manage service list
例如:#cinder-manage service list

- 使用
cinder-manage命令从cinder-volumePod 中删除失效的 Cinder 服务。# cinder-manage service remove cinder-scheduler cinder-scheduler-7868dc59dc-km9mj # cinder-manage service remove cinder-volume controller01@e-muc-cb-1b-az3:172.23.48.18
- 要检查此问题的状态,请运行
viocli check health -n cinder。
- 要在 VMware Integrated OpenStack 管理节点中安装所需的命令,请运行
tdnf install xxx。 - 要检查此问题的状态,请运行
viocli check health -n basic。
Kubernetes 节点列表为空或无法访问节点
从 VMware Integrated OpenStack 管理节点运行 osctl get nodes 并检查它是否可以捕获正确的输出。要检查此问题的状态,请运行 viocli check health -n basic。
没有正在运行的 Pod
从 VMware Integrated OpenStack 管理节点运行 osctl get pod |grep xxx,并检查它是否可以从输出中捕获任何正在运行的 Pod。要检查此问题的状态,请执行viocli check health -n basic。
无法访问 Pod
从 VMware Integrated OpenStack 管理节点运行 osctl exec -it $pod_name bash,然后检查是否可以登录到 Pod。要检查此问题的状态,请运行 viocli check health -n basic。
在 Pod 中运行命令
请查看日志文件 /var/log/viocli_health_check.log 以了解详细信息,然后尝试从 VMware Integrated OpenStack 管理节点重新运行命令。要检查此问题的状态,请运行 viocli check health -n basic。
- 登录到工具箱并运行一些 OpenStack 命令,例如,
openstack catalog list,并检查该命令是否可以捕获正确的返回。 - 有关更多消息,请添加调试选项。例如:
openstack catalog list --debug
- 要检查此问题的状态,请运行
viocli check health -n basic。
- 获取 openstack 管理员密码并将其与
OS_PASSWORD进行比较。osctl get secret keystone-keystone-admin -o jsonpath='{.data.OS_PASSWORD} - 如果
keystone-keystone-admin中没有存储任何值,请使用osctl edit secret keystone-keystone-admin进行更新。 - 要检查此问题的状态,请运行
viocli check health -n basic。
vCenter 集群过载/主机面临压力
检查 VIO 控制平面的 vCenter 主机并添加更多资源,或者清理一些未使用的实例以缓解资源压力。
- 查看日志 /var/log/viocli_health_check.log,然后在最后一条消息中搜索
check_vio_cert_expire以了解证书已过期或即将过期的时间。 - 要更新证书,请按照更新 VMware Integrated OpenStack 的证书执行操作。
- 要重新检查此问题的状态,请运行
viocli check health -n connectivity。
LDAP 证书已过期/即将过期
- 查看日志 /var/log/viocli_health_check.log,然后在最后一条消息中搜索
check_ldap_cert_expire以了解证书已过期或即将过期的时间。 - 要更新证书,请按照更新 LDAP 服务器的证书执行操作。
注: 如果未配置 LDAP,将跳过检查,并显示日志消息:
No LDAP Certificate found。 - 要重新检查此问题的状态,请运行
viocli check health -n connectivity。
vCenter 证书已过期/即将过期
- 查看日志 /var/log/viocli_health_check.log,然后在最后一条消息中搜索
check_vcenter_cert_expire以了解证书已过期或即将过期的时间。 - 要更新证书,请按照使用更新的 vCenter 或 NSX-T 证书配置 VMware Integrated OpenStack 执行操作。
注: 如果 vCenter 配置为使用不安全连接,将跳过检查,并显示日志消息:
Use insecure connection。 - 要重新检查此问题的状态,请运行
viocli check health -n connectivity。
NSX 证书已过期/即将过期
- 查看日志 /var/log/viocli_health_check.log,然后在最后一条消息中搜索
check_nsx_cert_expire以了解证书已过期或即将过期的时间。 - 要更新证书,请按照使用更新的 vCenter 或 NSX-T 证书配置 VMware Integrated OpenStack 执行操作。
注: 如果 NSX 配置为使用不安全连接,将跳过检查,并显示日志消息:
Use insecure connection。 - 要重新检查此问题的状态,请运行
viocli check health -n connectivity。
服务 xxx 已停止
运行 viocli start xxx 以启动服务。要检查此问题的状态,请运行 viocli check health -n lifecycle_manager。
- 查看日志 /var/log/viocli_health_check.log,然后在最后一条消息中搜索
check_cluster_workload以了解资源的详细使用情况。 - 修复报告的资源问题,并运行
viocli check health -n kubernetes,重新检查状态。
