









本节介绍了跨两个可用区 (AZ) 的控制器集群部署,以及故障期间发生的情况和出现某些故障时所需执行的恢复操作。
NSX Advanced Load Balancer 控制器 可部署为三节点集群,以实现高可用性和可扩展性。必须按特定方式部署这三个节点,以使两个控制器节点之间的 RTT(往返时间)值小于 20 毫秒。在 AWS 等公有云部署中,一个区域具有多个可用区。在此类部署中,作为最佳做法,应将每个控制器节点部署在单独的可用区中。
当区域具有三个或更多可用区时,控制器集群部署的注意事项十分简单。但是,在许多灾难恢复 (Disaster Recovery, DR) 部署中,控制器集群的三个节点仅部署到两个可用区中,如下所示:
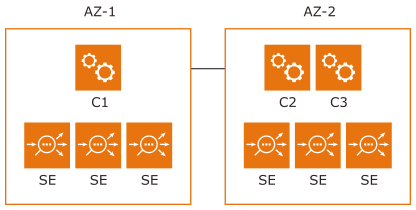
在分区方案中,如果至少有两个节点为 UP 状态且已连接,则控制器集群将为 UP 状态。SE 将尝试连接到活动分区。如果它们无法连接到活动分区,则将在没有控制器的情况下以无主方式运行,并继续处理应用程序流量。
在上述部署中,如果 AZ-2 变为 DOWN 状态,C1 将因未达到仲裁数而关闭。在这种情况下,需要手动干预以使控制器集群恢复为 UP 状态。
概括来说,手动工作流提供了一种方法来将剩余节点恢复为独立集群,并允许在适当时添加两个新节点。将此过程保持为手动是有意而为之,目的是使用户谨慎地恢复分区。
恢复未正常运行的集群
登录到控制器 C1,并运行 /opt/avi/scripts/recover_cluster.py 脚本。这会将 C1 重新配置为独立集群,保留配置和分析数据(日志和衡量指标),并将控制器集群恢复为 UP 状态。另外两个控制器节点的安全通道凭据将被吊销,并且与 C1 建立连接的 SE 将变为 UP 状态。在此过程中,SE 将进行重新配置以仅连接到 C1。
恢复 AZ-2 时会发生什么情况
C2 和 C3 将能够形成一个集群。AZ-2 中的 SE 可能连接到任一分区(C1 或 C2+C3)。此时,这两个分区都处于活动状态,如果它们运行时间过长,可能会导致中断。为防止出现这种情况,每个控制器节点都会监控其配置的成员列表中的其他控制器节点。如果某个节点确定它不在其他节点配置的成员列表中,它将自行关闭以便进行手动恢复。在此例中,C2 和 C3 都将检测到 C1 已进入手动恢复状态,并将自行关闭。
所有 SE 的安全通道凭据都将被吊销。在此期间,连接到 C2 或 C3 的 SE 将检测到控制器集群处于手动恢复状态;它们将重新引导,不再处理任何应用程序流量。在恢复为 UP 状态后,SE 将尝试连接到 C1 以执行正常操作。发送到控制器 C2 和 C3 的 REST API 命令将失败,状态代码为 520,这表示必须使用 clean_cluster.py 脚本将这两个节点重置为出厂默认设置。
清理未正常运行的集群
假设在 AZ-2 变为正常运行后不久,C2 和 C3 关闭。登录到 C2 和 C3,然后运行 /opt/avi/scripts/clean_cluster.py 脚本。此脚本将擦除所有配置和分析数据,并将 C2 和 C3 作为独立节点启动。清理后,C2 和 C3 可以重新加入 C1 以形成三节点集群。
