









服务器在 UP 和 DOWN 之间波动是一个常见问题。通常,服务器波动是由服务器达到或略微超过运行状况监控器允许的最大响应时间引起的。
要验证服务器是否发生波动,请检查池中的特定服务器的分析页面,如下所示:
导航到,然后单击池名称。
单击服务器选项卡。
单击一个服务器名称以查看其衡量指标,如下图所示:
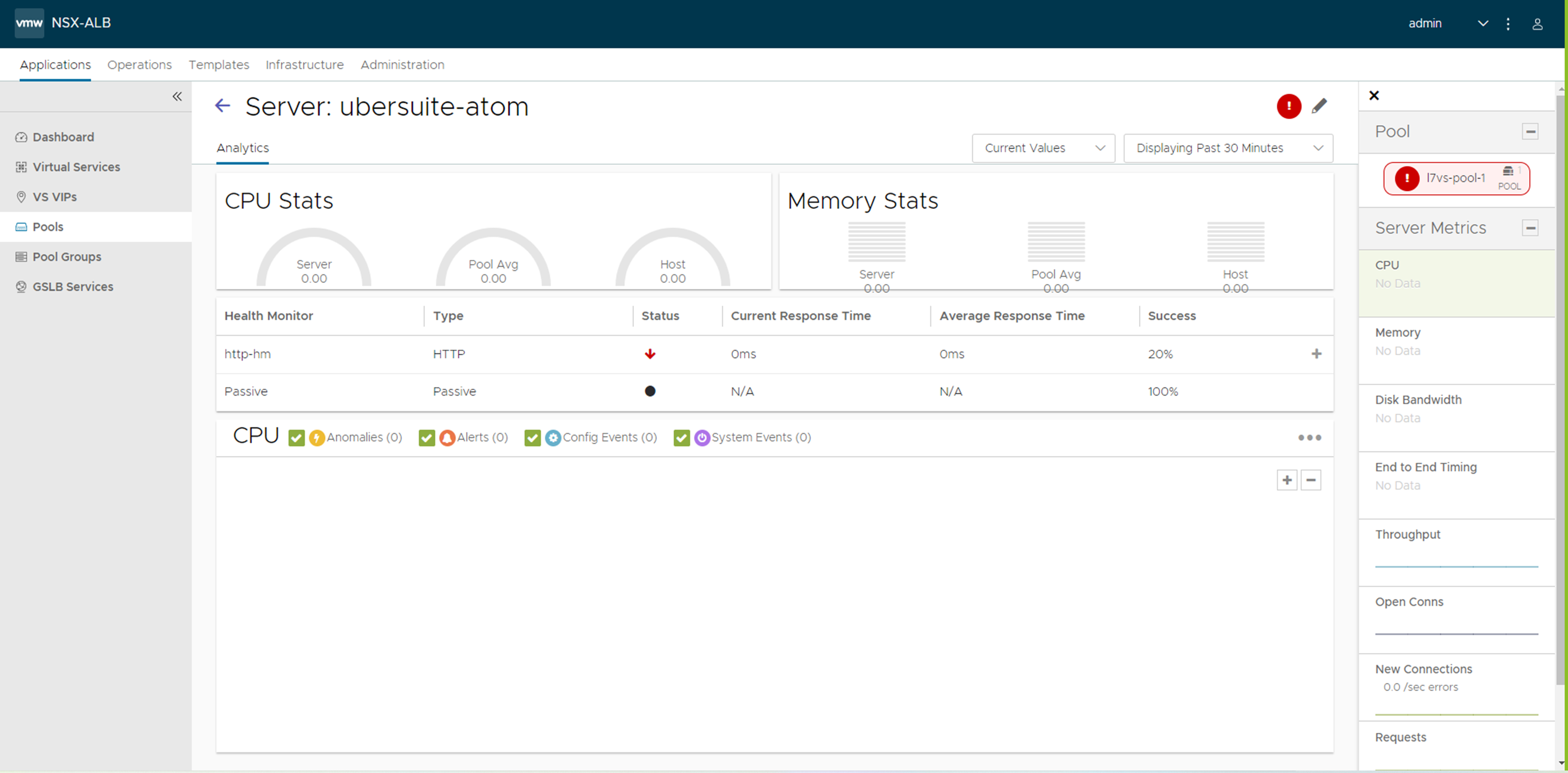
选择主图表的警示和系统事件叠加项图标,以查看选定持续时间的服务器 UP 和 DOWN 事件。该页面还显示发生故障的运行状况监控器列表。
将来自服务器的响应时间与运行状况监控器配置的接收超时范围进行比较。如果故障可能是由这些定时器造成的,您可以使用以下步骤以纠正这些故障:
添加额外的服务器 - 如果速度下降是由后端数据库造成的,添加额外服务器将无济于事,但对于只是繁忙或过载的服务器,这可能是一种快速且永久的修复方法。
增加运行状况监控器的接收超时窗口 - 超时值可能是 1-300 秒。超时值必须始终少于运行状况监控器的发送间隔。
增加所需的成功检查次数,并减少允许的失败检查次数。这将确保服务器不会很快恢复轮换状态,从而可能为其留出更多时间以处理导致响应缓慢的进程。
更改连接分配缓冲期(如果使用最少连接负载均衡算法)- 在首次启动服务器时,服务器可能会过快接收太多的连接。例如,如果一个服务器具有 1 个连接,其余服务器具有 100 个连接,根据最少连接算法,新服务器必须获得接下来的 99 个连接。这可能很容易使该服务器不堪重负,而必须由其余服务器处理瞬间出现的大量连接,从而导致多米诺骨牌效应。您可以在池配置的高级选项卡上配置连接分配缓冲期功能。连接分配缓冲期功能缓慢增加发送到新服务器的新连接的比例。如果您看到服务器发生连锁故障,增加缓冲期时间可能会有所帮助。
设置每个服务器的最大连接数。可以在池配置的高级选项卡上配置该选项,以确保服务器不会过载并以最佳速度处理连接。
