









ACME Enterprise 公司在美国拥有两个专用数据中心站点,一个位于 Palo Alto,一个位于 Austin。在 Palo Alto 站点的计划维护或意外故障期间,该公司会在其 Austin 站点恢复所有应用程序。
- 重新映射 IP 地址
- 同步安全策略
- 更新使用应用程序 IP 地址的其他服务,例如 DNS、安全策略和其他服务。
这种传统的灾难恢复方法需要花费大量额外的时间,才能在位于 Austin 的站点上完成 100% 的恢复。为了以最短的停机时间实现快速灾难恢复,ACME Enterprise 决定在跨 vCenter 环境中部署 NSX Data Center 6.4.5 或更高版本,如以下逻辑拓扑图中所示。
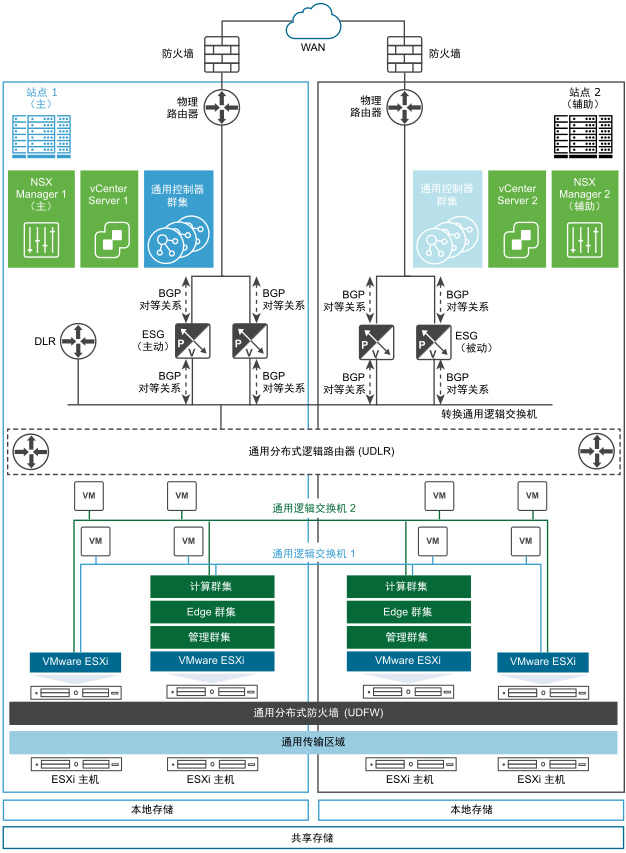
在该拓扑中,位于 Palo Alto 的站点 1 是主(受保护)数据中心,位于 Austin 的站点 2 是辅助(恢复)数据中心。每个站点都有一个 vCenter Server,它与自己的 NSX Manager 进行配对。站点 1 (Palo Alto) 的 NSX Manager 分配有主 NSX Manager 角色,站点 2 (Austin) 的 NSX Manager 分配有辅助 NSX Manager 角色。
ACME Enterprise 在两个站点中以主动-被动模式部署 跨 vCenter NSX。所有应用程序(工作负载)均在位于 Palo Alto 的站点 1 上运行,而在位于 Austin 的站点 2 上不运行任何应用程序。也就是说,默认情况下,站点 2 处于被动或待机模式。
两个站点具有自己的计算、Edge 和管理群集以及 ESG,它们位于该站点本地。由于在 UDLR 上禁用了本地输出,因此,仅在主站点上部署了单个 UDLR 控制虚拟机。UDLR 控制虚拟机连接到通用转换逻辑交换机。
NSX 管理员创建了一些跨两个 vCenter 域(分别位于站点 1 和站点 2 上)的通用对象。通用逻辑网络使用通用网络和安全对象,如通用逻辑交换机 (Universal Logical Switch, ULS)、通用分布式逻辑路由器 (Universal Distributed Logical Router, UDLR) 和通用分布式防火墙 (Universal Distributed Firewall, UDFW)。
- 从主 NSX Manager 中创建通用传输区域。
- 部署具有三个控制器节点的通用控制器群集。
- 将本地计算、Edge 和管理群集添加到主 NSX Manager 中的通用传输区域。
- 在 UDLR 控制虚拟机(Edge 设备虚拟机)上禁用本地输出,启用 ECMP 并启用平滑重启。
- 使用 BPG 在 Edge 服务网关 (ESG) 和 UDLR 控制虚拟机之间配置动态路由。
- 禁用 ECMP 并在两个 ESG 上启用“平滑重启”。
- 在两个 ESG 上禁用防火墙,因为在 UDLR 控制虚拟机上启用了 ECMP 以确保允许所有流量。
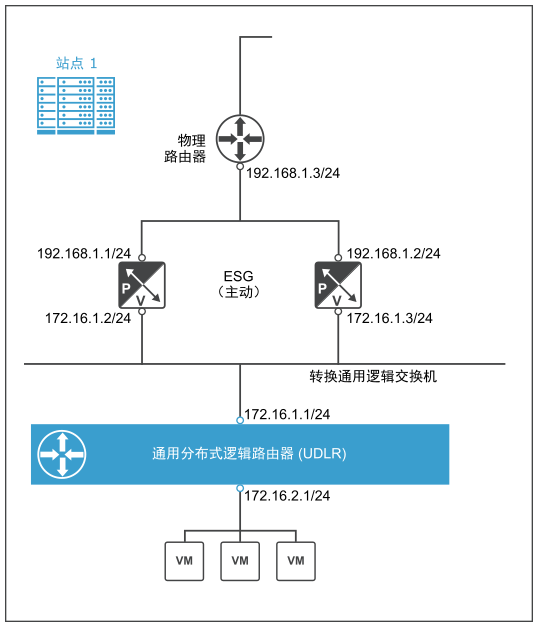
下图显示了站点 1 中 ESG 和 UDLR 的上行链路和下行链路接口的配置示例。
- 将本地计算、Edge 和管理群集添加到辅助 NSX Manager 中的通用传输区域。
- 在 ESG 上指定与站点 1 ESG 中配置的下行链路接口类似的下行链路接口。
- 在 ESG 上指定与站点 1 ESG 中配置的 BGP 配置类似的 BGP 配置。
- 在站点 1 处于活动状态时,关闭辅助站点上的 ESG 电源。
- 场景 1:站点 1 上计划的全站点故障
- 场景 2:站点 1 上非计划的全站点故障
- 场景 3:完全故障恢复到站点 1
