









将工作负载集群部署到专用硬件
Tanzu Kubernetes Grid 支持在 vSphere 7.0 及更高版本上将工作负载集群部署到特定类型的启用了 GPU 的主机。
部署启用了 GPU 的工作负载集群
要在 vSphere 工作负载集群中使用具有 GPU 的节点,必须启用 PCI 直通模式。这允许集群绕过 ESXi 主管直接访问 GPU,从而提供与本机系统上 GPU 类似的性能级别。使用 PCI 直通模式时,每个 GPU 设备都专用于 vSphere 工作负载集群中的虚拟机 (VM)。
注意要将启用了 GPU 的节点添加到现有集群,请使用
tanzu cluster node-pool set命令。
必备条件
- 具有 NVIDIA V100 或 NVIDIA Tesla T4 GPU 卡的 ESXi 主机。
- vSphere 7.0 Update 3 及更高版本。下面列出了 7.0u3 的内部版本,这是支持此功能所需的最低内部版本。
- Tanzu Kubernetes Grid v1.6+。
- Helm,Kubernetes 软件包管理器。要安装,请参见 Helm 文档中的安装 Helm。
过程
要创建启用了 GPU 的主机的工作负载集群,请执行以下步骤以启用 PCI 直通、构建自定义计算机映像、创建集群配置文件和 Tanzu Kubernetes 版本、部署工作负载集群,以及使用 Helm 安装 GPU Operator。
-
将具有 GPU 卡的 ESXi 主机添加到 vSphere Client。
-
启用 PCI 直通并记录 GPU ID,如下所示:
- 在 vSphere Client,选择
GPU集群中的目标 ESXi 主机。 - 选择配置 (Configure) > 硬件 (Hardware) > PCI 设备 (PCI Devices)。
- 选择所有 PCI 设备 (All PCI Devices) 选项卡。
- 从列表中选择目标 GPU。
- 单击切换直通 (Toggle Passthrough)。
- 在常规信息 (General Information) 下,记录设备 ID (Device ID) 和供应商 ID (Vendor ID)(在下图中以绿色突出显示)。相同的 GPU 卡的 ID 相同。对于集群配置文件,您将需要这些。
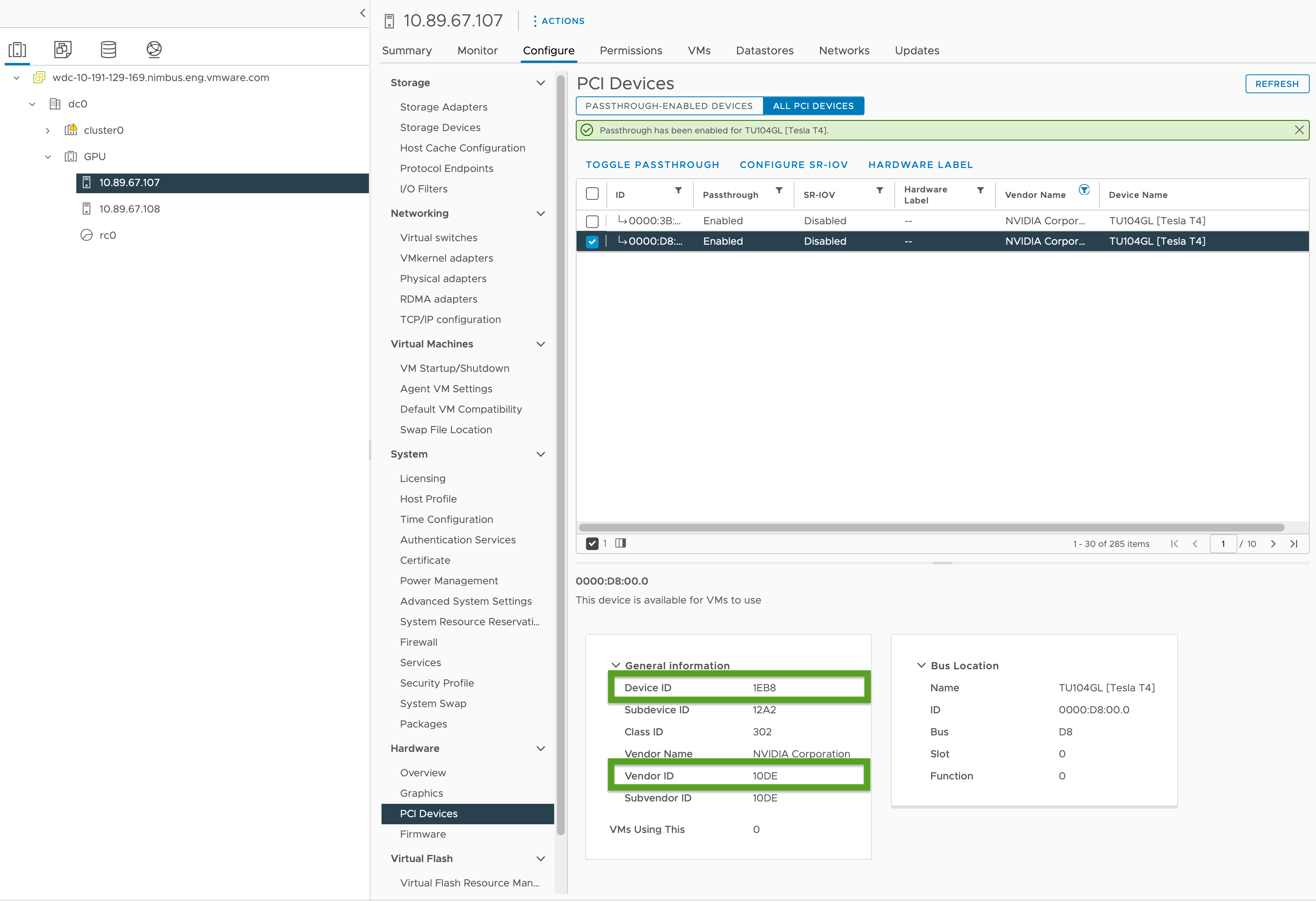
- 在 vSphere Client,选择
-
使用工作负载集群模板中的模板创建工作负载集群配置文件并包含以下变量:
... VSPHERE_WORKER_PCI_DEVICES: "0x<VENDOR-ID>:0x<DEVICE-ID>" VSPHERE_WORKER_CUSTOM_VMX_KEYS: 'pciPassthru.allowP2P=true,pciPassthru.RelaxACSforP2P=true,pciPassthru.use64bitMMIO=true,pciPassthru.64bitMMIOSizeGB=<GPU-SIZE>' VSPHERE_IGNORE_PCI_DEVICES_ALLOW_LIST: "<BOOLEAN>" VSPHERE_WORKER_HARDWARE_VERSION: vmx-17 WORKER_ROLLOUT_STRATEGY: "RollingUpdate"其中:
<VENDOR-ID>和<DEVICE-ID>是在上一步中记录的供应商 ID 和设备 ID。例如,如果供应商 ID为10DE且设备 ID 为1EB8,则值为"0x10DE:0x1EB8"。<GPU-SIZE>是集群中所有 GPU 的总帧缓存内存 GB,四舍五入到下一个更高的 2 次幂。- 例如,对于两个 40GB GPU,总缓存内存为 80 GB,四舍五入为 128 GB;因此,请将该值设置为
pciPassthru.64bitMMIOSizeGB=128。 - 要查找 GPU 卡所需的内存,请查阅特定 NVIDIA GPU 卡的文档。请参见 NVIDIA 文档中的表需要 64 GB 或更多 MMIO 空间的 GPU 上使用大型内存虚拟机的 vGPU 的要求。
- 另请参见:
- 例如,对于两个 40GB GPU,总缓存内存为 80 GB,四舍五入为 128 GB;因此,请将该值设置为
- 如果要使用 NVIDIA Tesla T4 GPU,则
<BOOLEAN>为false;如果要使用 NVIDIA V100 GPU,则为true。 <VSPHERE_WORKER_HARDWARE_VERSION>是我们希望将虚拟机升级到的虚拟机硬件版本。GPU 节点所需的最低版本应为 17。- 如果有额外的 PCI 设备可在升级期间供工作线程节点使用,
WORKER_ROLLOUT_STRATEGY为RollingUpdate,否则请使用OnDelete。
注意
每个虚拟机只能使用一种类型的 GPU。例如,不能在单个虚拟机上同时使用 NVIDIA V100 和 NVIDIA Tesla T4,但可以使用具有相同供应商 ID 和设备 ID 的多个 GPU 实例。
tanzuCLI 不允许更新MachineDeployment上的WORKER_ROLLOUT_STRATEGY规范。如果集群升级由于 PCI 设备不可用而停滞,VMware 建议使用kubectlCLI 编辑MachineDeployment策略。部署策略在spec.strategy.type中定义。有关可以为启用了 GPU 的集群配置的变量的完整列表,请参见《配置文件变量参考》中的启用了 GPU 的集群。
-
通过运行以下命令创建工作负载集群:
tanzu cluster create -f CLUSTER-CONFIG-NAME其中
CLUSTER-CONFIG-NAME是在前面的步骤中创建的集群配置文件的名称。 -
添加 NVIDIA Helm 存储库。
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia \ && helm repo update -
安装 NVIDIA GPU Operator:
helm install --kubeconfig=./KUBECONFIG --wait --generate-name -n gpu-operator --create-namespace nvidia/gpu-operator其中,
KUBECONFIG是工作负载集群的kubeconfig的名称和位置。有关详细信息,请参见检索工作负载集群kubeconfig。有关此命令中的参数的信息,请参见 NVIDIA 文档中的安装 GPU Operator。
-
确保 NVIDIA GPU Operator 正在运行:
kubectl --kubeconfig=./KUBECONFIG get pods -A输出类似于:
NAMESPACE NAME READY STATUS RESTARTS AGE gpu-operator gpu-feature-discovery-szzkr 1/1 Running 0 6m18s gpu-operator gpu-operator-1676396573-node-feature-discovery-master-7795vgdnd 1/1 Running 0 7m7s gpu-operator gpu-operator-1676396573-node-feature-discovery-worker-bq6ct 1/1 Running 0 7m7s gpu-operator gpu-operator-84dfbbfd8-jd98f 1/1 Running 0 7m7s gpu-operator nvidia-container-toolkit-daemonset-6zncv 1/1 Running 0 6m18s gpu-operator nvidia-cuda-validator-2rz4m 0/1 Completed 0 98s gpu-operator nvidia-dcgm-exporter-vgw7p 1/1 Running 0 6m18s gpu-operator nvidia-device-plugin-daemonset-mln6z 1/1 Running 0 6m18s gpu-operator nvidia-device-plugin-validator-sczdk 0/1 Completed 0 22s gpu-operator nvidia-driver-daemonset-b7flb 1/1 Running 0 6m38s gpu-operator nvidia-operator-validator-2v8zk 1/1 Running 0 6m18s
测试 GPU 集群
要测试启用了 GPU 的集群,请为 Kubernetes 文档中的 cuda-vector-add 示例创建 Pod 清单并进行部署。容器将下载、运行并使用 GPU 执行 CUDA 计算。
-
创建一个名为
cuda-vector-add.yaml的文件并添加以下内容:apiVersion: v1 kind: Pod metadata: name: cuda-vector-add spec: restartPolicy: OnFailure containers: - name: cuda-vector-add # https://github.com/kubernetes/kubernetes/blob/v1.7.11/test/images/nvidia-cuda/Dockerfile image: "registry.k8s.io/cuda-vector-add:v0.1" resources: limits: nvidia.com/gpu: 1 # requesting 1 GPU -
应用文件:
kubectl apply -f cuda-vector-add.yaml -
运行:
kubectl get po cuda-vector-add输出类似于:
cuda-vector-add 0/1 Completed 0 91s -
运行:
kubectl logs cuda-vector-add输出类似于:
[Vector addition of 50000 elements] Copy input data from the host memory to the CUDA device CUDA kernel launch with 196 blocks of 256 threads Copy output data from the CUDA device to the host memory Test PASSED Done
将工作负载集群部署到 Edge 站点
Tanzu Kubernetes Grid v1.6+ 支持将工作负载集群部署到 Edge VMware ESXi 主机。如果希望在不同的位置运行多个 Kubernetes 集群,这些集群全部由中央管理集群管理,则可以使用此方法。
拓扑:您可以在具有单个控制平面节点且仅具有一个或两个主机的生产环境中运行边缘工作负载集群。但是,尽管这使用较少的 CPU、内存和网络带宽,但您不具备标准生产 Tanzu Kubernetes Grid 集群的弹性和恢复特性。有关更多信息,请参见 VMware Tanzu 边缘解决方案参考架构 1.0。
本地注册表:要最大程度地减少通信延迟并最大限度地提高弹性,每个边缘集群应具有自己的本地 Harbor 容器注册表。有关此架构的概述,请参见《架构概览》中的容器注册表。要安装本地 Harbor 注册表,请参见在 vSphere 上部署脱机 Harbor 注册表。
超时:此外,当边缘工作负载集群在主数据中心具有远程管理集群时,您可能需要调整特定的超时,以使管理集群有足够的时间与工作负载集群计算机连接。要调整这些超时,请参见下面的扩展边缘集群超时以处理较高的延迟。
指定本地虚拟机模板
如果您的 Edge 工作负载集群使用自己的隔离存储,而不是共享 vCenter 存储,则必须将其配置为从本地存储中检索节点虚拟机模板映像作为 OVA 文件。
注意您无法使用
tanzu cluster upgrade升级使用本地虚拟机模板的 Edge 工作负载集群的 Kubernetes 版本。但可以按照《升级工作负载集群》主题中的升级具有本地虚拟机模板的 Edge 集群升级集群。
要为集群指定单个虚拟机模板或特定于工作节点和控制平面计算机部署的不同模板,请执行以下操作:
-
创建集群配置文件,并按照 创建基于类的集群中所述的两步过程的步骤 1 生成集群清单。
-
确保集群的虚拟机模板满足下列条件:
- 具有 TKG 的有效 Kubernetes 版本。
- 具有与 TKr 的
spec.osImages属性匹配的有效 OVA 版本。 - 上载到本地 vCenter 并具有有效的清单路径,例如
/dc0/vm/ubuntu-2004-kube-v1.27.5+vmware.1-tkg.1。
-
编辑清单中的
Cluster对象规范,如下所示,具体取决于您是定义集群范围的虚拟机模板还是多个虚拟机模板:-
集群范围的虚拟机模板:
- 在
annotations下,将run.tanzu.vmware.com/resolve-vsphere-template-from-path设置为空字符串。 - 在
vcenter块的spec.topology.variables下,将template设置为虚拟机模板的清单路径。 -
例如:
annotations: run.tanzu.vmware.com/resolve-vsphere-template-from-path: "" ... spec: topology: class: tkg-vsphere-default-v1.0.0 variables: - name: vcenter value: cloneMode: fullClone datacenter: /dc0 datastore: /dc0/datastore/sharedVmfs-0 folder: /dc0/vm/folder0 network: /dc0/network/VM Network resourcePool: /dc0/host/cluster0/Resources/rp0 ... template: VM-TEMPLATE ...其中,
VM-TEMPLATE是集群的虚拟机模板的路径。
- 在
-
每个
machineDeployment的多个虚拟机模板:- 在
annotations下,将run.tanzu.vmware.com/resolve-vsphere-template-from-path设置为空字符串。 - 在
variables.overrides中,针对每个machineDeployments块的spec.topology.worker和controlplane下,为vcenter添加一行,以将template设置为虚拟机模板的清单路径。 -
例如:
annotations: run.tanzu.vmware.com/resolve-vsphere-template-from-path: "" ... spec: workers: machineDeployments: - class: tkg-worker metadata: annotations: run.tanzu.vmware.com/resolve-os-image: image-type=ova,os-name=ubuntu name: md-1 replicas: 2 variables: overrides: - name: vcenter value: ... datacenter: /dco template: VM-TEMPLATE ...其中,
VM-TEMPLATE是machineDeployment的虚拟机模板的路径。
- 在
-
-
按照创建基于类的集群中所述的过程的步骤 2 使用修改后的配置文件创建集群。
延长边缘集群的超时以处理更高的延迟
如果您的管理集群远程管理在边缘站点上运行的工作负载集群或管理超过 20 个工作负载集群,则可以调整特定的超时,以便集群 API 不会阻止或删除可能暂时脱机或需要超过 12 分钟才能与其远程管理集群通信的计算机,尤其是在基础架构置备不足时。
您可以调整三个设置,为您的边缘集群提供额外的时间与其控制平面进行通信:
-
MHC_FALSE_STATUS_TIMEOUT:例如,将默认的12m扩展到40m,以防止MachineHealthCheck控制器在其Ready状态保持为False超过 12 分钟时重新创建计算机。有关计算机运行状况检查的详细信息,请参见配置 Tanzu Kubernetes 集群的计算机运行状况检查。 -
NODE_STARTUP_TIMEOUT:例如,将默认20m扩展到60m,以防止MachineHealthCheck控制器阻止新计算机加入集群,因为新计算机启动时间超过 20 分钟,其会认为该操作不正常。 -
etcd-dial-timeout-duration:例如,在capi-kubeadm-control-plane-controller-manager中将默认的10m延长到40s,以防止管理集群上的etcd客户端在扫描工作负载集群上etcd的运行状况时过早失败。管理集群使用其与etcd连接的能力作为计算机运行状况的衡量标准。例如:-
在终端中,运行:
kubectl edit capi-kubeadm-control-plane-controller-manager -n capi-system -
更改
--etcd-dial-timeout-duration的值:- args: - --leader-elect - --metrics-bind-addr=localhost:8080 - --feature-gates=ClusterTopology=false - --etcd-dial-timeout-duration=40s command: - /manager image: projects.registry.vmware.com/tkg/cluster-api/kubeadm-control-plane-controller:v1.0.1_vmware.1
-
此外,您需要注意:
-
capi-kubedm-control-plane-manager:如果它以某种方式与工作负载集群“分离”,您可能需要将其退回到新节点,以便它可以正确监控工作负载集群中的
etcd。 -
TKG 中的 Pinniped 配置均假定工作负载集群已连接到管理集群。如果断开连接,您应该确保工作负载 Pod 使用管理帐户或服务帐户与边缘站点上的 API 服务器进行通信。否则,从管理集群断开连接将干扰边缘站点通过 Pinniped 对其本地工作负载 API 服务器进行身份验证的能力。
