了解如何将 Telegraf 收集的 主管 衡量指标流式传输到自定义可观测性平台。默认情况下,Telegraf 在主管上处于启用状态,它采用 Prometheus 格式从 主管 组件(如 Kubernetes API 服务器、虚拟机服务、Tanzu Kubernetes Grid 等)收集衡量指标。作为 vSphere 管理员,您可以配置可观测性平台(如 VMware Aria Operations for Applications、Grafana 等),以查看和分析收集的主管衡量指标。
Telegraf 是基于服务器的代理,用于从不同的系统、数据库和 IoT 收集和发送衡量指标。每个 主管 组件都会公开一个端点,供 Telegraf 连接。然后,Telegraf 会将收集的衡量指标发送到您选择的可观测性平台。您可以将 Telegraf 支持的任何输出插件配置为可观察性平台,以聚合和分析 主管 衡量指标。有关支持的输出插件,请参见 Telegraf 文档。
以下组件公开了相应端点,供 Telegraf 连接并收集衡量指标:Kubernetes API 服务器、etcd、kubelet、Kubernetes 控制器管理器、Kubernetes 调度程序、Tanzu Kubernetes Grid、虚拟机服务、虚拟机映像服务、NSX Container Plug-in (NCP)、器存储接口 (CSI)、证书管理器、NSX 以及各种主机衡量指标(如 CPU、内存和存储)。
查看 Telegraf Pod 和配置
Telegraf 在 主管 上的 vmware-system-monitoring 系统命名空间下运行。要查看 Telegraf Pod 和 ConfigMap,请执行以下操作:
- 使用 vCenter Single Sign-on 管理员帐户登录到 主管 控制平面。
kubectl vsphere login --server <control planе IP> --vsphere-username [email protected]
- 使用以下命令查看 Telegraf Pod:
kubectl -n vmware-system-monitoring get pods
生成的容器如下所示:telegraf-csqsl telegraf-dkwtk telegraf-l4nxk
- 使用以下命令查看 Telegraf ConfigMaps:
kubectl -n vmware-system-monitoring get cm
生成的 ConfigMap 如下所示:default-telegraf-config kube-rbac-proxy-config kube-root-ca.crt telegraf-config
default-telegraf-configConfigMap 保存默认的 Telegraf 配置,它是只读的。当文件损坏或您希望仅还原为默认值时,您可以将其用作后备选项来还原telegraf-config中的配置。您唯一可以编辑的 ConfigMap 是telegraf-config,它定义了哪些组件将衡量指标发送到 Telegraf 代理以及发送到哪些平台。 - 查看
telegraf-configConfigMap:kubectl -n vmware-system-monitoring get cm telegraf-config -o yaml
inputs 部分定义了 Telegraf 从中收集衡量指标的
主管 组件的所有端点以及衡量指标本身的类型。例如,以下输入将 Kubernetes API 服务器定义为端点:
[[inputs.prometheus]]
# APIserver
## An array of urls to scrape metrics from.
alias = "kube_apiserver_metrics"
urls = ["https://127.0.0.1:6443/metrics"]
bearer_token = "/run/secrets/kubernetes.io/serviceaccount/token"
# Dropping metrics as a part of short term solution to vStats integration 1MB metrics payload limit
# Dropped Metrics:
# apiserver_request_duration_seconds
namepass = ["apiserver_request_total", "apiserver_current_inflight_requests", "apiserver_current_inqueue_requests", "etcd_object_counts", "apiserver_admission_webhook_admission_duration_seconds", "etcd_request_duration_seconds"]
# "apiserver_request_duration_seconds" has _massive_ cardinality, temporarily turned off. If histogram, maybe filter the highest ones?
# Similarly, maybe filters to _only_ allow error code related metrics through?
## Optional TLS Config
tls_ca = "/run/secrets/kubernetes.io/serviceaccount/ca.crt"
alias 属性指示从中收集衡量指标的组件。namepass 属性指定公开的且相应地由 Telegraf 代理收集的组件衡量指标。
尽管 telegraf-config ConfigMap 已包含广泛的衡量指标,但您仍然可以定义其他衡量指标。请参见 Kubernetes 系统组件的衡量指标和 Kubernetes 衡量指标参考。
将可观察性平台配置到 Telegraf
在 telegraf-config 的 outps 部分中,您可以配置 Telegraf 将其收集的衡量指标流式传输到的位置。有多个选项可供选择,例如 outputs.file、outputs.wavefront、outputs.prometheus_client 和 outps-https。在 outps-https 部分中,您可以配置要用于汇总和监控主管衡量指标的可观测性平台。您可以将 Telegraf 配置为将衡量指标发送到多个平台。要编辑 telegraf-config ConfigMap 并配置可观察性平台以查看 主管 衡量指标,请执行以下步骤:
- 使用 vCenter Single Sign-on 管理员帐户登录到 主管 控制平面。
kubectl vsphere login --server <control planе IP> --vsphere-username [email protected]
- 将
telegraf-configConfigMap 保存到本地 kubectl 文件夹:kubectl get cm telegraf-config -n vmware-system-monitoring -o jsonpath="{.data['telegraf\.conf']}">telegraf.conf在对
telegraf-configConfigMap 进行任何更改之前,请确保将其存储在版本控制系统中,以防想要还原为文件的先前版本。如果要还原为默认配置,可以使用default-telegraf-configConfigMap 中的值。 - 使用文本编辑器(如 VIM)在
outputs.http部分中添加所选可观察性平台的连接设置:vim telegraf.config
您可以直接取消对以下部分的注释并相应地编辑值,也可以根据需要添加新的outputs.http部分。#[[outputs.http]] # alias = "prometheus_http_output" # url = "<PROMETHEUS_ENDPOINT>" # insecure_skip_verify = <PROMETHEUS_SKIP_INSECURE_VERIFY> # data_format = "prometheusremotewrite" # username = "<PROMETHEUS_USERNAME>" # password = "<PROMETHEUS_PASSWORD>" # <DEFAULT_HEADERS>例如,以下是 Grafana 的outputs.http配置的示例:[[outputs.http]] url = "http://<grafana-host>:<grafana-metrics-port>/<prom-metrics-push-path>" data_format = "influx" [outputs.http.headers] Authorization = "Bearer <grafana-bearer-token>"
有关配置仪表板和使用来自 Telegraf 的衡量指标的详细信息,请参见将衡量指标从 Telegraf 流式传输到 Grafana。
以下是 VMware Aria Operations for Applications(以前为 Wavefront)的配置示例:[[outputs.wavefront]] url = "http://<wavefront-proxy-host>:<wavefront-proxy-port>"建议通过代理将衡量指标载入到 Aria Operations for Applications。有关详细信息,请参见 Wavefront 代理。
- 将 主管 上的现有
telegraf-config文件替换为在本地文件夹上编辑过的文件:kubectl create cm --from-file telegraf.conf -n vmware-system-monitoring telegraf-config --dry-run=client -o yaml | kubectl replace -f -
- 检查新配置是否已成功保存:
- 查看新的 telegraf-config ConfigMap:
kubectl -n vmware-system-monitoring get cm telegraf-config -o yaml
- 检查所有 Telegraf Pod 是否均已启动且正在运行:
kubectl -n vmware-system-monitoring get pods
- 如果某些 Telegraf Pod 未运行,请检查该 Pod 的 Telegraf 日志以进行故障排除:
kubectl -n vmware-system-monitoring logs <telegraf-pod>
- 查看新的 telegraf-config ConfigMap:
应用程序仪表板的示例操作
以下是一个仪表板,其中显示了通过 Telegraf 从 主管 上的 API 服务器和 etcd 接收的衡量指标摘要:
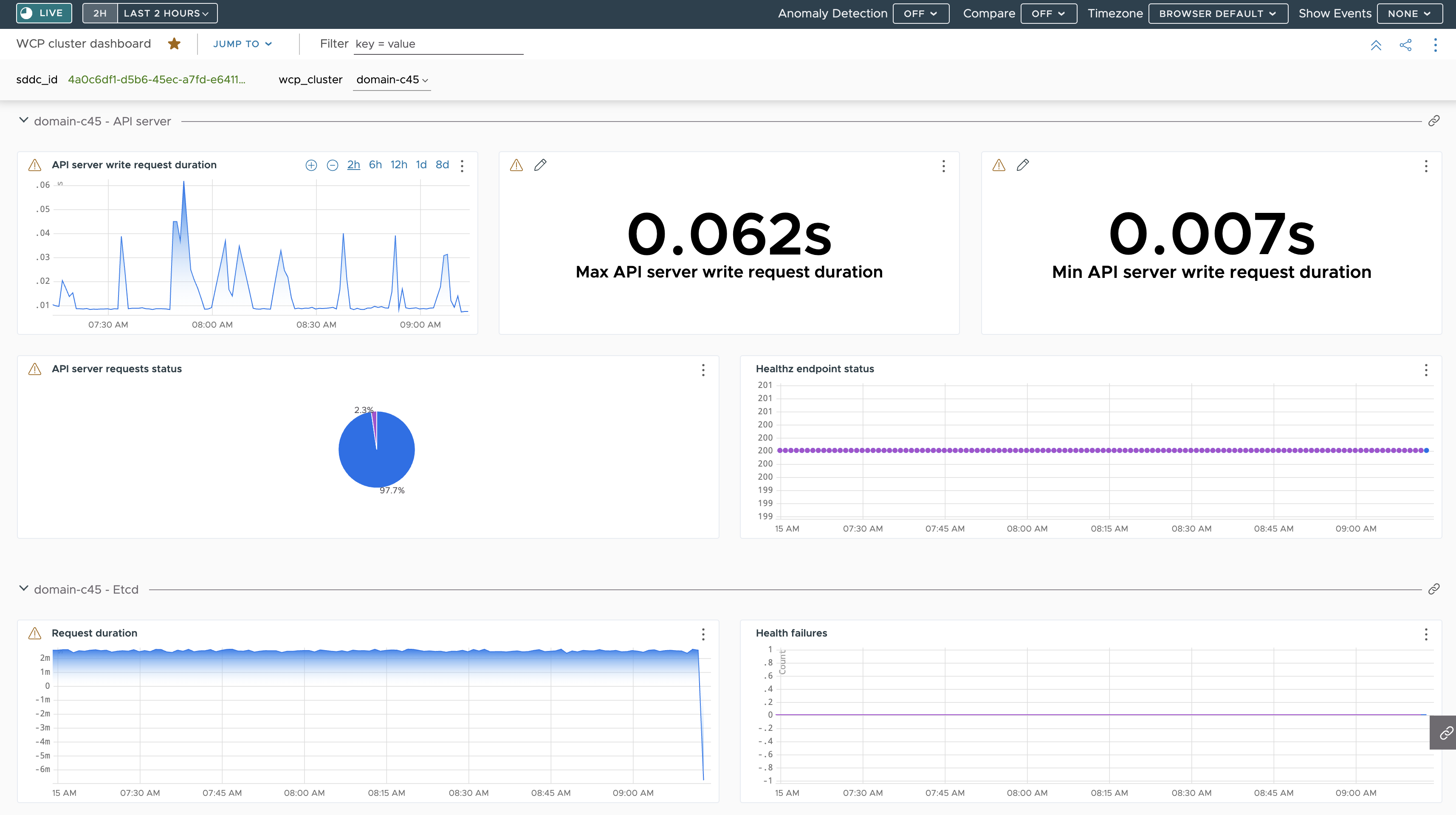
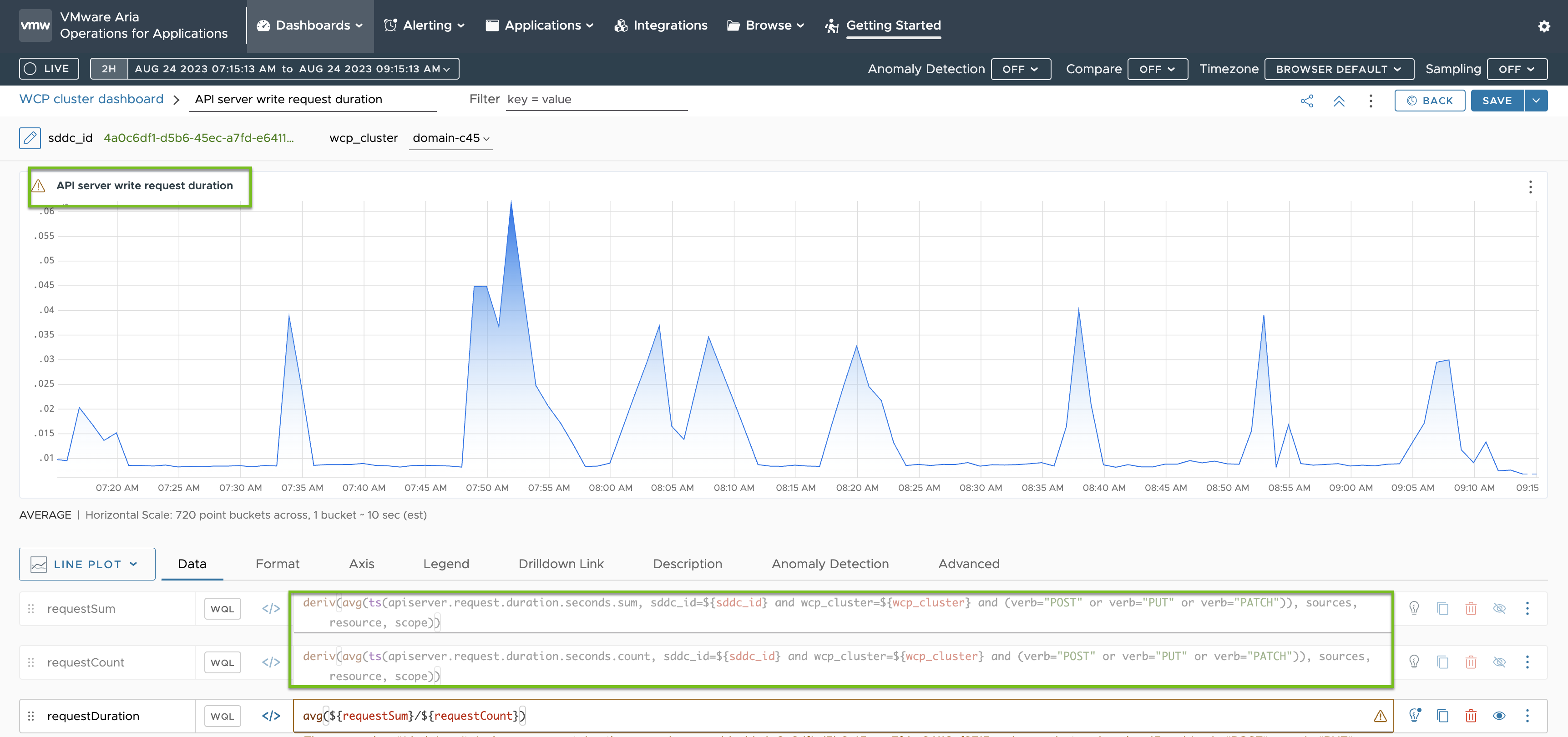
API 服务器写入请求持续时间 I 的衡量指标基于在 telegraf-config ConfigMap 中指定的衡量指标,您可以看到这些衡量指标以绿色突出显示: