









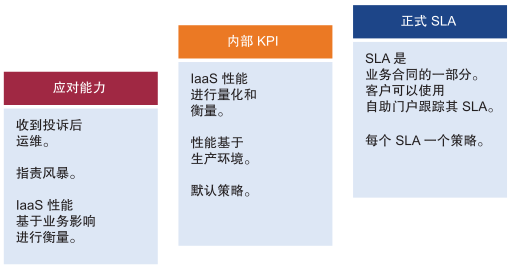
性能就是确保工作负载获得必要的资源。可以使用关键性能指标 (KPI) 确定与工作负载相关的性能问题。使用这些 KPI 定义与服务层相关联的 SLA。这些仪表板使用 KPI 来显示使用者层的工作负载性能以及提供者层的工作负载整体性能。
SLA 是您与客户签订的正式业务合同。通常,SLA 在 IaaS 提供者(基础架构团队)和 IaaS 客户(应用程序团队或业务部门)之间签订。正式的 SLA 需要运营转型,例如,它需要的不仅仅是技术变革,您可能还需要查看合同、价格(而非成本)、流程和人员。KPI 涵盖 SLA 衡量指标以及提供预警的其他衡量指标。如果您没有 SLA,请从内部 KPI 开始。您必须了解并分析 IaaS 的实际性能。如果您没有自己的阈值,请使用 vRealize Operations Manager 中的默认设置,因为已选择这些阈值以支持主动操作。
性能管理的三个过程
- 计划。设置性能目标。在构建 vSAN 时,您必须了解所需的磁盘延迟(毫秒)。在虚拟机级别(而不是 vSAN 级别)衡量的 10 毫秒是良好的开端。
- 监控。将计划与实际情况进行比较。实际情况是否与架构所要交付的内容匹配?如果不匹配,必须对其进行修复。
- 故障排除。如果实际情况与计划不相符,您必须主动修复计划,而不是等到出现问题和投诉。
- 争用:这是主要指标。
- 配置:检查版本不兼容问题。
- 可用性:检查软错误。vMotion 关闭时间、锁定。这需要 Log Insight。
- 利用率:最后检查此项。如果前三个参数正常,则可以跳过此项。
性能管理的三个层次
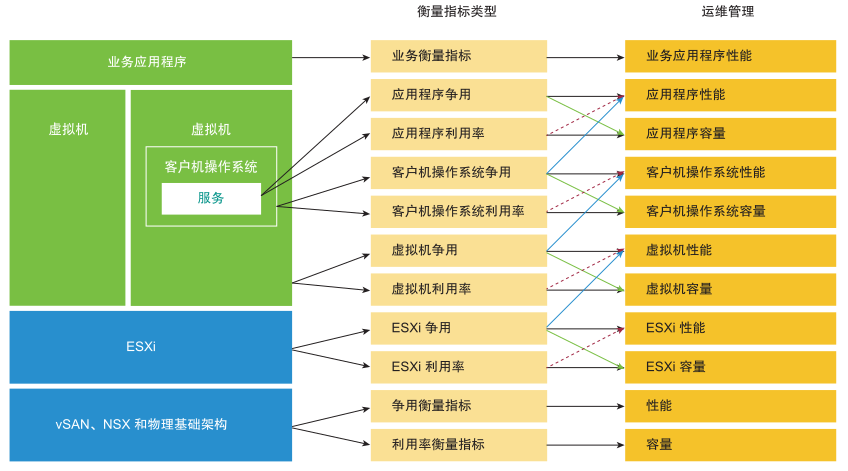
企业应用程序有三个主要领域。其中每个领域都有自己的一组团队。每个团队都有一组独特的职责,需要相关的技能集。三个领域由业务、应用程序和 IaaS 组成。请参阅下图,了解三个层次以及每一层上的典型问题。
性能管理在很大程度上是一种排除操作。该方法会对每一层进行划分,并确定该层是否导致性能问题。因此,必须使用单个衡量指标指示某特定层的性能是否正常。这个主要衡量指标恰如其名,就是关键性能指标 (KPI)。
上面的层取决于其下面的层,因此基础架构层通常是争用的根源。因此,请先将重点放在底部层,因为底部层是其上方层的基础。好的一面是,该层通常是一个水平层,提供了一组通用基础架构服务,而无论在其上运行的是何种业务应用程序。
性能管理的两个衡量指标
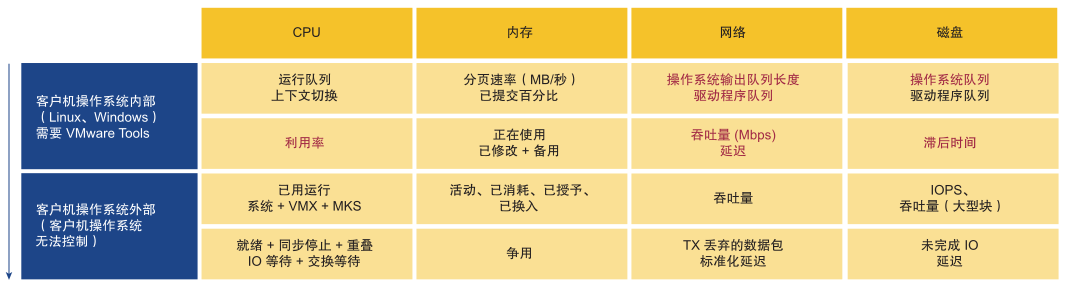
性能的主要计数器是争用。大多数人会查看利用率,因为他们担心如果利用率较高,可能会出现错误。实际上应该查看争用。争用以不同的形式呈现,如队列、延迟、已丢弃、已取消和上下文切换。
但是,请勿将超高利用率指示器与性能问题混淆。如果 ESXi 主机遇到内存膨胀、压缩和交换问题,并不意味着虚拟机出现性能问题。您可以根据主机为其虚拟机提供服务的情况来衡量主机的性能。虽然性能与 ESXi 主机利用率相关,但性能衡量指标并非基于利用率,而是基于争用衡量指标。
| 基础架构配置 | 虚拟机和客户机操作系统配置 |
|---|---|
ESXi 设置
|
虚拟机:限制、份额和预留
|
网络
|
大小:NUMA 作用。虚拟机跨多个 NUMA 节点。 |
集群设置
|
快照。IO 进程翻倍。 虚拟机驱动程序。 |
vSAN
|
Windows 或 Linux 进程乒乓式运行、进程失控和操作系统级队列。 |
从性能管理的角度来看,vSphere 集群是资源中最小的逻辑构造块。虽然资源池和虚拟机主机关联性可以提供较小的扇区,但其在操作上非常复杂,而且无法提供承诺的 IaaS 服务质量。资源池无法提供不同的服务等级。例如,您的 SLA 指明金牌比银牌快两倍,因为其价格高出 200%。资源池可为金级提供两倍的份额。无法预确定是否将这些额外份额转换为 CPU 就绪的一半。
虚拟机性能
KPI 计数器对于某些用户可能具有技术性,因此 vRealize Operations 包括一条起点线,方便他们开始使用。您可以在分析环境后调整阈值。这种分析是一种很好的做法,因为大多数客户没有基准。分析需要 Advanced 版。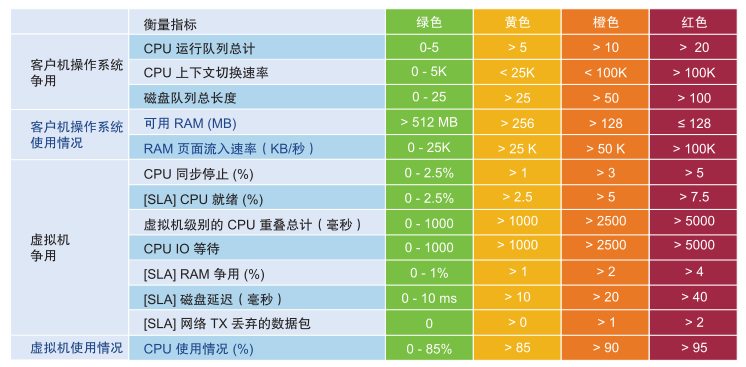
性能衡量指标
| IaaS | 虚拟机计数器 | 阈值 |
|---|---|---|
| CPU | 就绪 | 2.5% |
| 内存 | 争用 | 1% |
| 磁盘 | 滞后时间 | 10 毫秒 |
| 网络 | TX 丢弃的数据包 | 0 |
该表是一个严格阈值示例。之所以使用高性能标准,是因为它是基础架构团队使用的内部 KPI。不是向客户确认的外部正式 SLA。内部 KPI 与外部 SLA 之间必须有一个缓冲,以便运维团队收到预警,有时间采取应对措施,从而避免违反外部 SLA。高标准也适用于从任务关键点到开发环境的各个方面。如果将标准设置为性能最差环境,则无法将其应用于更关键的开发。
使用单个阈值是为了保持运维简单。这意味着生产环境的性能应高于开发环境。在其他条件都相同的情况下,开发环境的性能应低于生产环境。单个阈值有助于说明不同服务等级所提供服务质量 (QoS) 的差异。例如,如果您支付的费用较少,则获得的性能就会较差,如果您支付了一半的费用,就会获得一半的性能。
表中所述的 IaaS 的四个元素(CPU、RAM、磁盘和网络)在每个收集周期进行评估。收集时间设置为 5 分钟,因为此值是便于监控的适当平衡点。如果 SLA 基于一分钟,则会太过紧密,而导致成本增加或降低阈值。
设计注意事项
所有性能仪表板都采用相同的设计原则。它们有意设计得具有相似性,因为考虑到每个仪表板具有相同的目标,如果它们看起来彼此不同,则会令人困惑。
仪表板设计有两个单独的部分:摘要和详细信息。
- 摘要部分通常放置在仪表板的顶部,以提供整体情况。
- 详细信息部分放置在摘要部分下方。您可以在详细信息部分中深入了解特定对象。例如,您可以获取任何特定虚拟机的详细性能报告。
在详细信息部分中,使用快速上下文切换在性能故障排除期间检查多个对象的性能。例如,如果您正在查看虚拟机的性能,则可以查看特定于虚拟机的信息和 KPI,而无需更改屏幕。您可以从一个虚拟机移动到另一个虚拟机,以便在不打开多个窗口的情况下查看详细信息。
仪表板使用渐进式披露来最大程度地减少信息过载,并确保网页加载速度更快。此外,如果您的浏览器会话仍然存在,界面会记住您上次选择的内容。
许多性能仪表板和容量仪表板具有相似的布局,因为这些操作支柱之间存在一个共同点。
