









随着在 vRealize Operations 8 中引入连续可用性,出现几个常见问题。本节旨在帮助提高对连续可用性的认识和认知。
- 如何将数据存储在分析节点中?
-
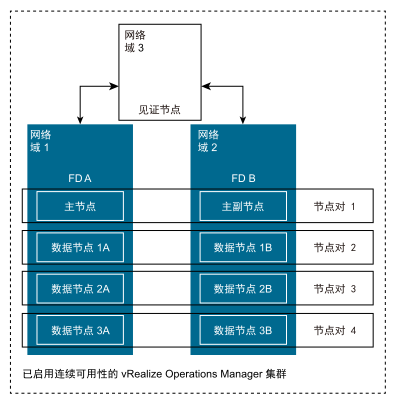
发现对象后,vRealize Operations 会确定要保留数据的节点,然后将数据复制到其在另一个故障域中的配对节点。每个对象都存储在故障域中的两个分析节点(节点对)中且始终保持同步。
例如,vRealize Operations 具有八个分析节点,CA 已启用,因此每个故障域具有四个分析节点(请参见上图)。
发现新对象后,vRealize Operations 会决定将数据存储在“数据节点 2B”(主)中,并自动将数据副本保存在“数据节点 2A”(辅助)中。
如果因某种原因“FD A”变得不可用,则将使用“数据节点 2B”中的“主”数据。
如果因某种原因“FD B”变得不可用,则将使用“数据节点 2A”中的“辅助”数据。
- 哪些情况下会中断连续可用性集群?不支持两个故障域中的主节点或主副本节点和数据节点或者两个或多个数据节点同时丢失的情况。
-
故障域 1 中的每个分析节点在故障域 2 中都有其节点对,反之亦然。
使用前面提到的示例,我们将有四个节点对:
主节点 + 副本节点
数据节点 1A (FD A) + 数据节点 1B (FD B)
数据节点 2A (FD A) + 数据节点 2B (FD B)
数据节点 3A (FD A) + 数据节点 3B (FD B)
每个节点对的两个节点始终同步并存储相同的数据。因此,当所有节点对中的一个节点可用时,集群将继续运行,而不会丢失数据。
- 如果一个故障域中的一个数据节点变得不可用,会发生什么情况?
- 集群将处于降级状态,但当一个节点在任一故障域中变得不可用时,集群将继续运行。不会丢失数据。必须修复或替换数据节点,以便集群不会保持降级状态。
- 如果故障域 1 中的两个数据节点和故障域 2 中的主副本节点丢失,集群是否会中断?
- 在此示例中,集群将继续运行,而不会丢失数据。如果每个节点对中仍有一个分析节点可用,则不会丢失数据。
- 如果整个故障域变得不可用,会发生什么情况?
-
集群将处于降级状态,但会在整个故障域变得不可用时继续运行。不会丢失数据。必须修复故障域并使其联机,以便集群不会保持降级状态。
如果故障域无法恢复,则可以将整个故障域替换为新部署的节点。从管理 UI 中,只能替换主副本节点。如果主节点的整个故障域丢失,您需要等到主节点发生故障切换,并且主副本节点升级为新的主节点。
- 将故障节点重新添加到故障域的正确过程是什么?同步需要多长时间?
- 重新添加故障节点的建议过程是使用管理 UI 中的“替换集群节点”功能。添加替换节点后,将同步数据。同步时间在很大程度上取决于对象计数、对象的历史时间段、网络带宽和集群上的负载。
- 当故障域之间的网络延迟超过 20 毫秒时,会发生什么情况? vRealize Operations 最多容许多长时间的延迟?
- 要获得最佳性能,必须遵守延迟要求。故障域之间的延迟应少于 10 毫秒,在 20 秒间隔内峰值最长为 20 毫秒。有关网络延迟准则的详细信息,请参见知识库文章 vRealize Operations Manager 大小调整准则(知识库文章 2093783)。
- 当故障域之间的网络延迟在一段时间内超过“20 秒间隔内 20 毫秒”,而随后又恢复到 10 毫秒以下时,需要多长时间才能重新同步?
- 高延迟并不意味着同步已停止。发现对象后, vRealize Operations 会决定需要保留数据的节点(主),然后将数据的第二个副本转到其节点对(辅助)。每个对象都存储在两个故障域中的两个分析节点(对)中。同步是一个持续过程,在该过程中,辅助节点会定期与主节点同步。同步根据主节点和辅助节点的上次同步时间戳执行。因此, vRealize Operations 中没有同步数据队列。
- 实际见证节点容许的错过轮询是多少?
- 见证节点操作不基于轮询。仅当其中一个节点无法与其他故障域中的节点进行通信(经过各种检查后)时,见证节点才会交互。
- 主节点和主副本节点将在何时进行故障切换?
- 仅当主节点无法再访问或处于非活动状态时,才会进行故障切换。
- 主副本节点何时升级为主节点?
-
主副本节点仅在两种情况下升级为主节点:
- 现有主节点关闭时。
- 关联的故障域已关闭/脱机。
- 原始主节点恢复联机时,是否会恢复主节点控制?如何同步数据?
- 当操作恢复正常并且主节点和主副本节点都处于联机状态时,新升级的主节点(原主副本节点)将保留新的主节点,新的主副本节点(原主节点)将与新的主节点同步。
- 见证节点变得不可用时,故障域会发生什么情况?
-
虽然两个故障域都运行良好并且相互通信,但见证节点不可用性不会对集群产生任何影响; vRealize Operations 将继续运行。如果故障域之间存在通信问题,可能会出现以下三种情况:
- 可以从两个故障域中访问见证节点 - 见证节点将根据站点运行状况使一个故障域脱机。
- 只能从一个故障域访问见证节点 - 另一个故障域将自动脱机。
- 无法从两个故障域访问见证节点 - 两个故障域都将处于脱机状态。
- 当分析节点无法与其他故障域中的分析节点通信时,会发生什么情况?
- 如果分析节点无法与其他故障域或见证节点中的所有节点进行通信,分析节点将自动脱机。在确保所有通信问题都得到解决后,管理员用户应手动将自动脱机的所有节点或整个故障域恢复联机。
- 如果标准集群中的最大节点数为 10 个特大节点(支持 440,000 个对象),那么为什么连续可用性集群中的最大节点数更多,为 12 个特大节点(支持 264,000 个对象)?
- 只有连续可用性集群支持 12 个特大节点,并且在两个单独的故障域中引用最多六个特大节点。这允许增加标准集群中的节点数,并允许收集更多对象。
- 连续可用性是否支持负载均衡器?
- 是,有关负载均衡器配置的详细信息,请参见 vRealize Operations Manager 文档页面中“资源”下的《 vRealize Operations 负载均衡配置指南》。
- 文档指出:“启用 CA 后,如果主节点发生故障,副本节点可以接管主节点提供的所有功能。故障切换到副本节点的操作为自动执行,并且仅需两到三分钟的 vRealize Operations 停机时间,便可恢复操作并重新开始收集数据。”
- 在测试过程中,断开主节点上的网络接口的连接,会在 5 分钟内切换到新的主节点,您将从产品 UI 中退出或出现异常错误。
- 所述的两到三分钟是近似中值,因此 5 分钟是可接受的。
