









Als Automation Pipelines-Administrator oder Entwickler können Sie Automation Pipelines und VMware Tanzu Kubernetes Grid Integrated Edition (früher als VMware Enterprise PKS bezeichnet) verwenden, um die Bereitstellung Ihrer Softwareanwendungen in einem Kubernetes-Cluster zu automatisieren. In diesem Anwendungsfall werden weitere Methoden erläutert, mit denen Sie die Freigabe Ihrer Anwendung automatisieren können.
In diesem Anwendungsfall erstellen Sie eine Pipeline, die zwei Phasen umfasst und Jenkins zum Erstellen und Bereitstellen Ihrer Anwendung verwendet.
- Die erste Phase ist die Entwicklungsphase. Sie verwendet Jenkins, um den Code aus einem Branch im GitHub-Repository zu extrahieren und dann zu erstellen, zu testen und zu veröffentlichen.
- Die zweite Phase ist die Bereitstellungsphase. Während dieser Phase wird eine Benutzervorgangsaufgabe durchgeführt, die von Key-Usern genehmigt werden muss. Erst dann kann die Pipeline Ihre Anwendung auf dem Kubernetes-Cluster bereitstellen.
Wenn Sie einen Kubernetes-API-Endpoint im Arbeitsbereich der Pipeline verwenden, erstellt Automation Pipelines die erforderlichen Kubernetes-Ressourcen, wie z. B. ConfigMap, geheimen Schlüssel und Pod, um die CI- (Continuous Integration) oder benutzerdefinierte Aufgabe auszuführen. Automation Pipelines kommuniziert mit dem Container über den NodePort.
Zur Freigabe von Daten über Pipeline-Ausführungen hinweg müssen Sie eine Beanspruchung eines persistenten Volumes bereitstellen. Automation Pipelines mountet die Beanspruchung eines persistenten Volumes dann auf den Container, um die Daten zu speichern und für nachfolgende Pipeline-Ausführungen zu verwenden.
Der Arbeitsbereich der Automation Pipelines-Pipeline unterstützt Docker und Kubernetes für CI- und benutzerdefinierte Aufgaben.
Weitere Informationen zum Konfigurieren des Arbeitsbereichs finden Sie unter Konfigurieren des Pipeline-Arbeitsbereichs.
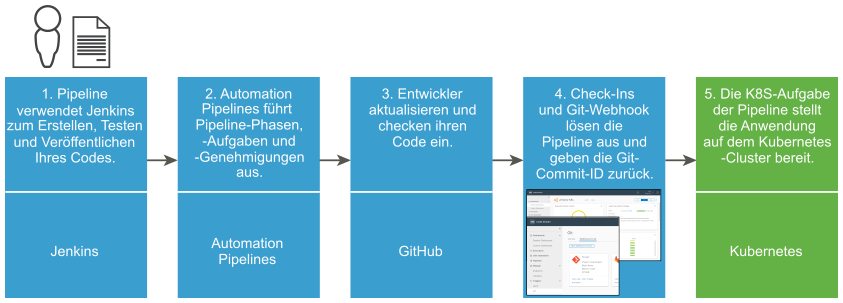
Die Entwicklungstools, Bereitstellungsinstanzen und die YAML-Datei der Pipeline müssen verfügbar sein, damit die Anwendung von der Pipeline erstellt, getestet, veröffentlicht und bereitgestellt werden kann. Die Pipeline stellt Ihre Anwendung für Entwicklungs- und Produktionsinstanzen von Kubernetes-Clustern bereit.
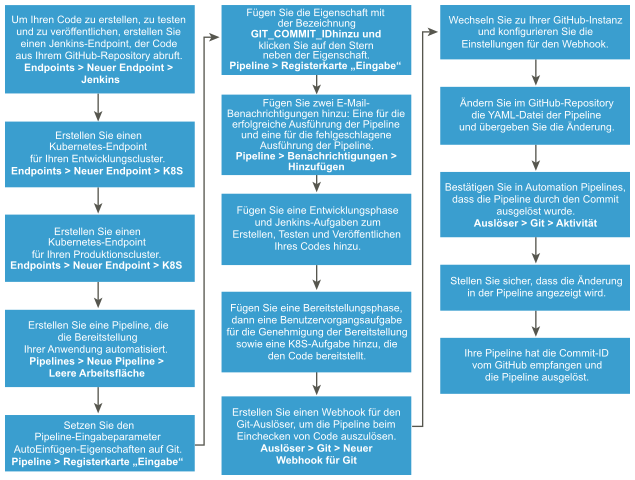
Weitere Methoden zum Automatisieren der Freigabe Ihrer Anwendung:
- Statt Jenkins können Sie zum Erstellen Ihrer Anwendung die native Erstellungsfunktion von Automation Pipelines oder einen Docker-Build-Host verwenden.
- Statt Ihre Anwendung in einem Kubernetes-Cluster bereitzustellen, können Sie sie in einem Amazon Web Services-Cluster (AWS) bereitstellen.
Weitere Informationen zur Verwendung der nativen Erstellungsfunktion von Automation Pipelines und eines Docker-Hosts finden Sie unter:
Voraussetzungen
- Stellen Sie sicher, dass sich der bereitzustellenden Anwendungscode in einem funktionierenden GitHub-Repository befindet.
- Stellen Sie sicher, dass Sie über eine funktionierende Jenkins-Instanz verfügen.
- Stellen Sie sicher, dass Sie über einen funktionierenden E-Mail-Server verfügen.
- Erstellen Sie in Automation Pipelines einen E-Mail-Endpoint, der eine Verbindung mit Ihrem E-Mail-Server herstellt.
- Richten Sie zwei Kubernetes-Cluster für Entwicklung und Produktion auf Amazon Web Services (AWS) ein, auf denen die Pipeline Ihre Anwendung bereitstellt.
- Stellen Sie sicher, dass das GitHub-Repository den YAML-Code für die Pipeline und alternativ eine YAML-Datei enthält, in der die Metadaten und Spezifikationen für Ihre Umgebung definiert werden.
Prozedur
- Erstellen Sie eine Pipeline, die einen Container Ihrer Anwendung, wie z. B. WordPress, im Kubernetes-Entwicklungscluster bereitstellt, und legen Sie die Eingabeeigenschaften für die Pipeline fest.
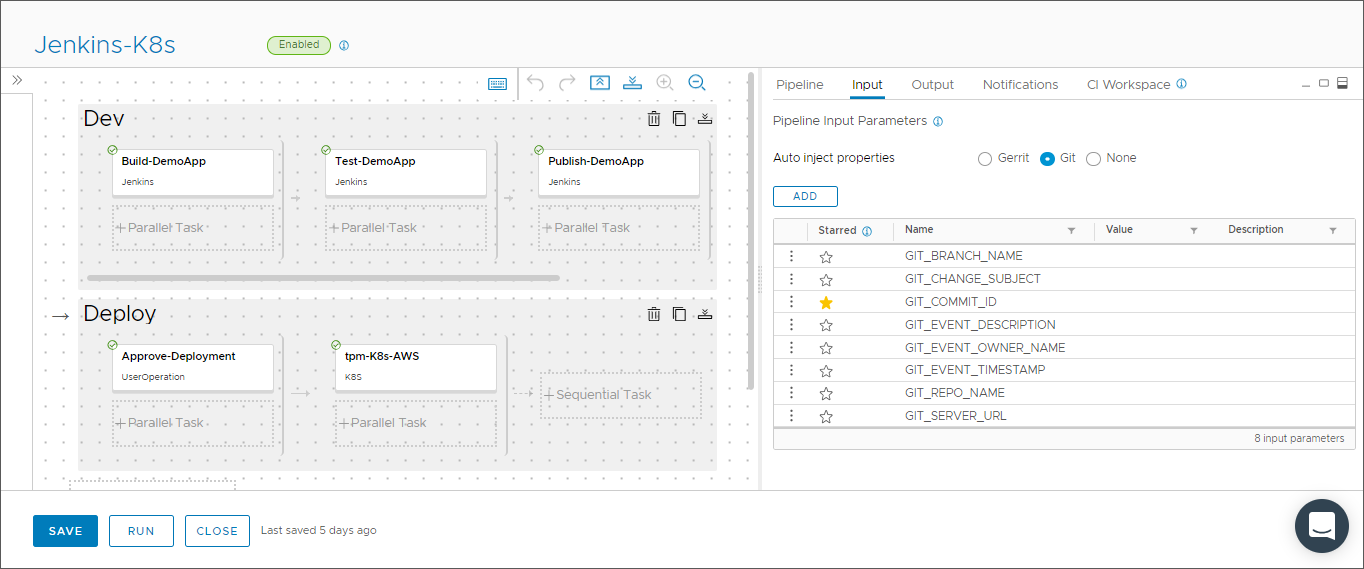
- Damit die Pipeline einen Code-Commit in GitHub erkennt, der die Pipeline auslöst, klicken Sie in der Pipeline auf die Registerkarte Eingabe und wählen Sie AutoEinfügen-Eigenschaften aus.
- Fügen Sie die Eigenschaft mit dem Namen GIT_COMMIT_ID hinzu und klicken Sie auf den Stern daneben.
Bei Ausführung der Pipeline wird die Commit-ID angezeigt, die vom Git-Auslöser zurückgegeben wird.
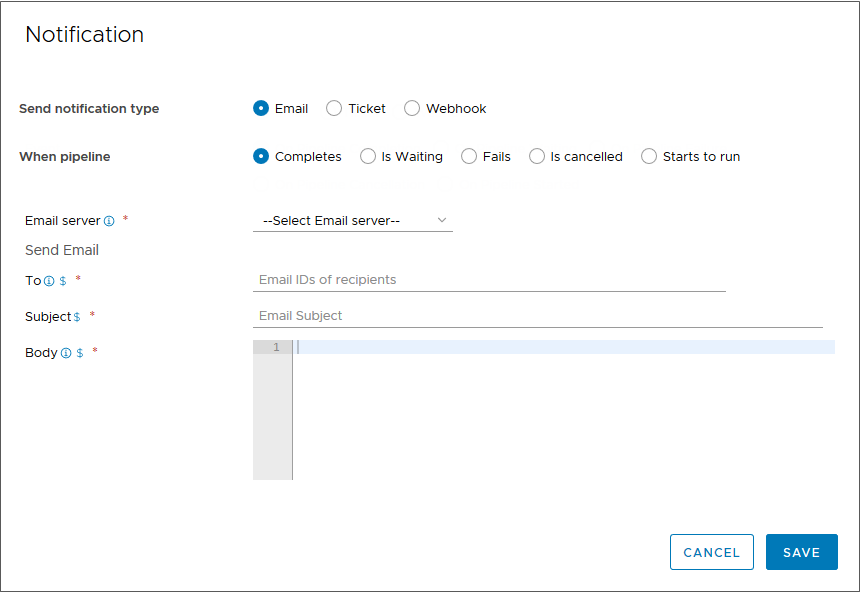
- Fügen Sie Benachrichtigungen hinzu, um bei erfolgreicher oder fehlgeschlagener Ausführung der Pipeline eine E-Mail zu senden.
- Klicken Sie in der Pipeline auf die Registerkarte Benachrichtigungen und dann auf Hinzufügen.
- Um nach Abschluss der Pipeline-Ausführung eine E-Mail-Benachrichtigung hinzuzufügen, wählen Sie E-Mail und dann Abschluss aus. Wählen Sie anschließend den E-Mail-Server aus, geben Sie die E-Mail-Adressen ein und klicken Sie auf Speichern.
- Zum Hinzufügen einer weiteren E-Mail-Benachrichtigung bei einem Pipeline-Fehler wählen Sie Fehler aus und klicken Sie auf Speichern.
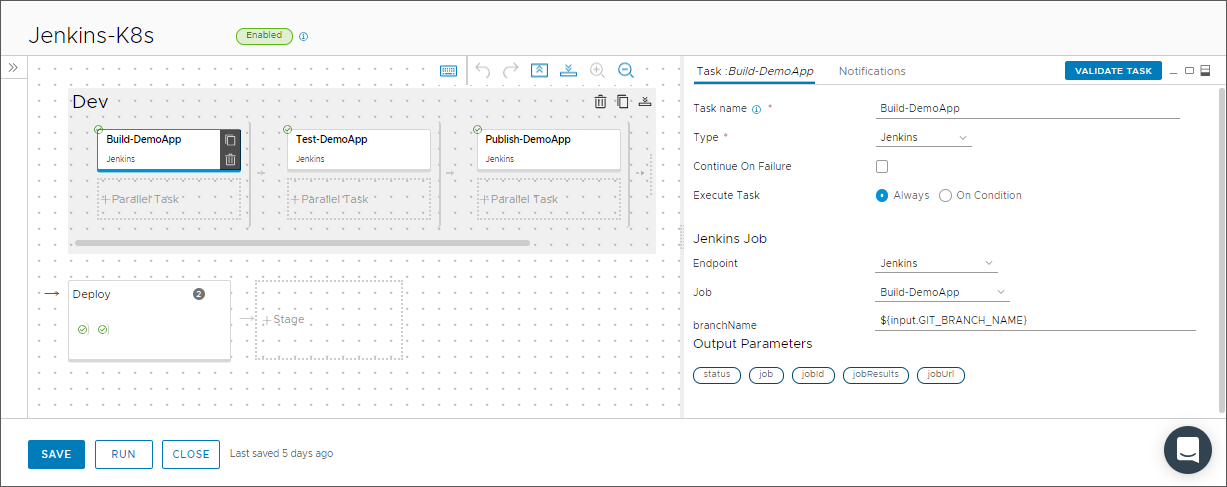
- Fügen Sie Ihrer Pipeline eine Entwicklungsphase und Aufgaben zum Erstellen, Testen und Veröffentlichen der Anwendung hinzu. Überprüfen Sie anschließend jede Aufgabe.
- Fügen Sie zum Erstellen der Anwendung eine Jenkins-Aufgabe hinzu, die den Jenkins-Endpoint verwendet und einen Erstellungsauftrag über den Jenkins-Server ausführt. Damit die Pipeline den Code abrufen kann, geben Sie den Git-Branch in folgendem Format ein: $ {Input. GIT_BRANCH_NAME}
- Fügen Sie zum Testen der Anwendung eine Jenkins-Aufgabe hinzu, die denselben Jenkins-Endpoint verwendet und einen Testauftrag über den Jenkins-Server ausführt. Geben Sie anschließend denselben Git-Branch ein.
- Fügen Sie zum Veröffentlichen der Anwendung eine Jenkins-Aufgabe hinzu, die denselben Jenkins-Endpoint verwendet und einen Veröffentlichungsauftrag über den Jenkins-Server ausführt. Geben Sie anschließend denselben Git-Branch ein.
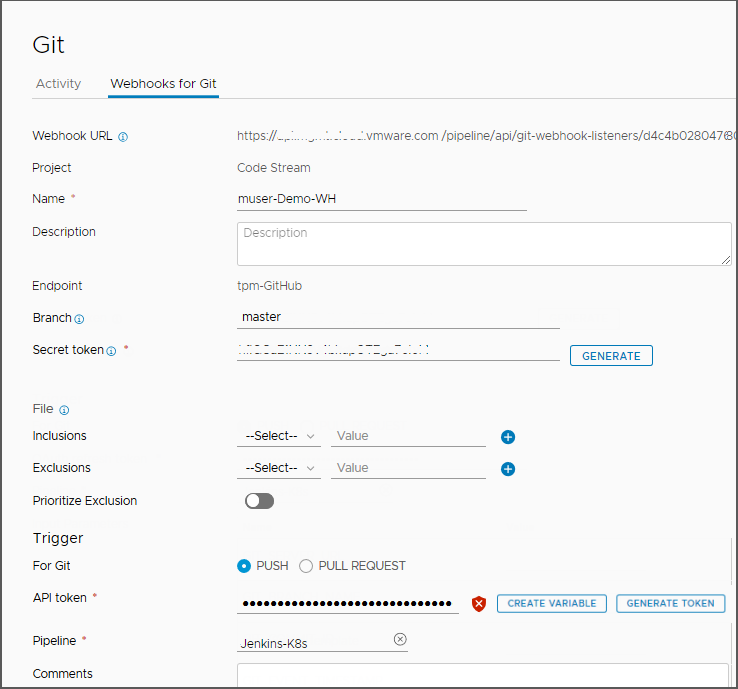
- Fügen Sie einen Git-Webhook hinzu, der Automation Pipelines die Verwendung des Git-Auslösers ermöglicht. Mit diesem Auslöser wird die Pipeline ausgelöst, wenn Entwickler Ihren Code übergeben.
Ergebnisse
Herzlichen Glückwunsch! Sie haben die Bereitstellung Ihrer Softwareanwendung in Ihrem Kubernetes-Cluster automatisiert.
Beispiel: Beispiel für eine Pipeline-YAML, die eine Anwendung in einem Kubernetes-Cluster bereitstellt
Für den in diesem Beispiel verwendeten Pipeline-Typ ähnelt die YAML dem folgenden Code:
apiVersion: v1
kind: Namespace
metadata:
name: ${input.GIT_BRANCH_NAME}
namespace: ${input.GIT_BRANCH_NAME}
---
apiVersion: v1
data:
.dockercfg: eyJzeW1waG9ueS10YW5nby1iZXRhMi5qZnJvZy5pbyI6eyJ1c2VybmFtZSI6InRhbmdvLWJldGEyIiwicGFzc3dvcmQiOiJhRGstcmVOLW1UQi1IejciLCJlbWFpbCI6InRhbmdvLWJldGEyQHZtd2FyZS5jb20iLCJhdXRoIjoiZEdGdVoyOHRZbVYwWVRJNllVUnJMWEpsVGkxdFZFSXRTSG8zIn19
kind: Secret
metadata:
name: jfrog
namespace: ${input.GIT_BRANCH_NAME}
type: kubernetes.io/dockercfg
---
apiVersion: v1
kind: Service
metadata:
name: pipelines
namespace: ${input.GIT_BRANCH_NAME}
labels:
app: pipelines
spec:
ports:
- port: 80
selector:
app: pipelines
tier: frontend
type: LoadBalancer
---
apiVersion: extensions/v1
kind: Deployment
metadata:
name: pipelines
namespace: ${input.GIT_BRANCH_NAME}
labels:
app: pipelines
spec:
selector:
matchLabels:
app: pipelines
tier: frontend
strategy:
type: Recreate
template:
metadata:
labels:
app: pipelines
tier: frontend
spec:
containers:
- name: pipelines
image: cas.jfrog.io/pipelines:${input.GIT_BRANCH_NAME}-${Dev.PublishApp.output.jobId}
ports:
- containerPort: 80
name: pipelines
imagePullSecrets:
- name: jfrog
Nächste Maßnahme
Zur Bereitstellung Ihrer Softwareanwendung im Kubernetes-Produktionscluster führen Sie die Schritte erneut aus und wählen Sie den Produktionscluster aus.
Weitere Informationen zur Integration von Automation Pipelines mit Jenkins finden Sie unter Vorgehensweise zum Integrieren von Automation Pipelines in Jenkins.
