









Wenn der Cloud-Administrator Private AI Automation Services in VMware Aria Automation eingerichtet hat, können Sie KI-Arbeitslasten mithilfe des Automation Service Broker-Katalogs anfordern.
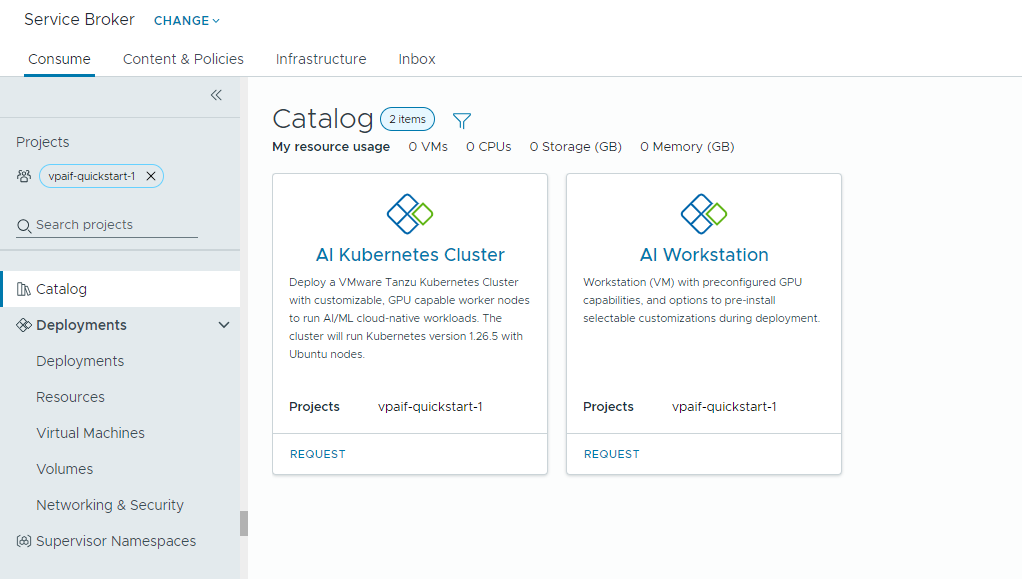
Private AI Automation Services unterstützt zwei Katalogelemente in Automation Service Broker, auf die Benutzer mit den entsprechenden Berechtigungen zugreifen und die von Benutzern angefordert werden können.
- KI-Arbeitsstation – eine GPU-fähige virtuelle Maschine, die mit der gewünschten vCPU und vGPU, dem gewünschten Arbeitsspeicher und der gewünschten KI-/ML-Software von NVIDIA konfiguriert werden kann.
- KI-Kubernetes-Cluster – ein GPU-fähiger Tanzu Kubernetes-Cluster, der mit einem NVIDIA GPU-Operator konfiguriert werden kann.
Bevor Sie beginnen
- Stellen Sie sicher, dass Private AI Automation Services für Ihr Projekt konfiguriert ist und Sie über Berechtigungen zum Anfordern von KI-Katalogelementen verfügen.
Beachten Sie, dass es sich hier bei allen Werten um Anwendungsbeispiele handelt. Ihre Kontowerte hängen von Ihrer Umgebung ab.
Bereitstellen einer Deep Learning-VM in einer VI-Arbeitslastdomäne
Als Datenwissenschaftler können Sie eine einzelne softwaredefinierte GPU-Entwicklungsumgebung über den Automation Service Broker-Self-Service-Katalog bereitstellen. Sie können eine GPU-fähige virtuelle Maschine mit Maschinenparametern erstellen, um die Entwicklungsanforderungen zu modellieren, die KI-/ML-Softwarekonfigurationen zur Erfüllung von Schulungs- und Inferenzanforderungen angeben und die KI-/ML-Pakete aus der NVIDIA NGC-Registrierung über einen Portalzugriffsschlüssel festlegen.
Prozedur
Bereitstellen eines KI-fähigen Tanzu Kubernetes-Clusters
Als DevOps-Ingenieur können Sie einen GPU-fähigen Tanzu Kubernetes-Cluster anfordern, in dem KI-/ML-Arbeitslasten von Worker-Knoten ausgeführt werden können.
Der TKG-Cluster enthält einen NVIDIA GPU-Operator. Bei diesem handelt es sich um einen Kubernetes Operator, der für die Einrichtung des geeigneten NVIDIA-Treibers für die NVIDIA GPU-Hardware auf den TKG-Clusterknoten verantwortlich ist. Der bereitgestellte Cluster kann für KI-/ML-Arbeitslasten verwendet werden, ohne dass ein zusätzliches GPU-bezogenes Setup erforderlich ist.
Prozedur
- Suchen Sie nach der Karte KI-Kubernetes-Cluster und klicken Sie auf Anfordern.
- Wählen Sie ein Projekt aus.
- Geben Sie einen Namen und eine Beschreibung für Ihre Bereitstellung ein.
- Wählen Sie die Anzahl der Steuerungsbereichsknoten aus.
Einstellung Beispielwert Anzahl der Knoten 1 VM-Klasse cpu-only-medium – 8 CPUs und 16 GB Arbeitsspeicher Die Klassenauswahl definiert die innerhalb der virtuellen Maschine verfügbaren Ressourcen.
- Wählen Sie die Anzahl der Arbeitsknoten aus.
Einstellung Beschreibung Anzahl der Knoten 3 VM-Klasse a100-medium – 4 vGPU (64 GB), 16 CPUs und 32 GB Arbeitsspeicher - Klicken Sie auf Senden.
Ergebnisse
Die Bereitstellung enthält einen Supervisor-Namespace, einen TKG-Cluster mit drei Arbeitsknoten, mehrere Ressourcen innerhalb des TKG-Clusters und eine Carvel-Anwendung, die die GPU-Operator-Anwendung bereitstellt.
Überwachen der Private AI-Bereitstellungen
Sie verwenden die Seite „Bereitstellungen“, um Ihre Bereitstellungen und die verknüpften Ressourcen zu verwalten, Änderungen an Bereitstellungen vorzunehmen, Fehler in Bereitstellungen zu beheben, die Ressourcen zu ändern und nicht verwendete Bereitstellungen zu löschen.
Zum Verwalten Ihrer Bereitstellungen klicken Sie auf .
Weitere Informationen finden Sie unter Vorgehensweise zum Verwalten meiner Automation Service Broker-Bereitstellungen.
