Bei Leistung geht es in erster Linie darum, Arbeitslasten mit den notwendigen Ressourcen zu versorgen, während Leistungsverwaltung auf gezieltem Weglassen beruht. Bei dieser Methode wird jede Schicht genau untersucht, um festzustellen, ob die jeweilige Schicht Leistungsprobleme verursacht. Eine einzelne Metrik ist zwingend erforderlich, um anzugeben, ob eine bestimmte Schicht ausgeführt wird. Diese primäre Metrik wird treffend als KPI (Key Performance Indicator) bezeichnet.
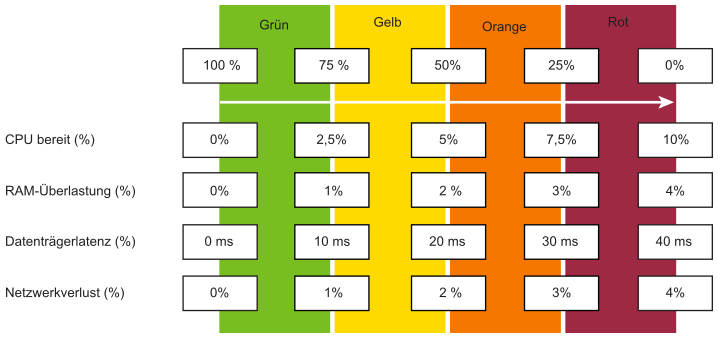
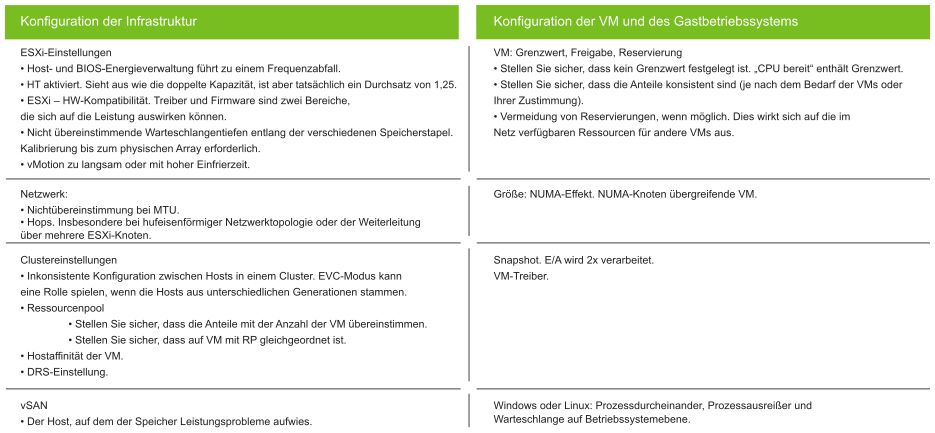
Jede Metrik, wie z. B. Festplattenlatenz, besteht aus vier Bereichen: grün, gelb, orange und rot.
Zur einfacheren Überwachung wird der Bereich auf 0 bis 100 % abgebildet. Grün entspricht 75 bis 100 % und rot 0 - 25 %. Durch Aufteilen von 100 % in vier gleiche Bereiche erhält jeder Bereich eine angemessene Größe.
Mithilfe der obigen Technik können Metriken mit unterschiedlichen Einheiten kombiniert werden. Jede Metrik wird demselben Bereich (Prozentsatz) zugeordnet.
Zur ordnungsgemäßen Zuordnung einer Metrik zu vier Bereichen werden der Logik folgend fünf statt vier Metriken benötigt. Beispielsweise bei der Festplattenlatenz:
-
Bei 41 ms beträgt die Festplattenlatenz 0 % (rot), da die Obergrenze des roten Bereichs bei 40 ms liegt.
-
Bei 35 ms beträgt die Festplattenlatenz 12,5 %, da sie zwischen 30 und 40 ms liegt und sich somit im roten Bereich befindet.
-
Bei 30 ms beträgt die Festplattenlatenz 25 %, da sie an der Grenze des roten zum orangefarbenen Bereich liegt.
Nach der Umwandlung aller Metriken in einen Bereich zwischen 0 und 100 % wird der Durchschnitts- und nicht der Spitzenwert verwendet, um die KPI-Metrik abzurufen. Durch Verwendung des Durchschnittswerts werden die Metriken daran gehindert, den KPI-Wert zu dominieren. Wenn sich Metriken als kritisch für Ihre Vorgänge erweisen, können Sie hierfür Warnungen verwenden. Die Verwendung eines Durchschnittswerts spiegelt die Realität wider, da jede Metrik zu gleichen Teilen berücksichtigt wird.
Diese Dashboards verwenden KPIs, um die Leistung von Horizon-Sitzungen auf der Verbraucherebene und die Gesamtleistung der Arbeitslasten auf der Horizon-Infrastrukturebene anzuzeigen. Diese Dashboards sind für Horizon-Architekten oder leitende Administratoren konzipiert. Sie zeigen die Gesamtleistung des Datencenteranteils des Desktops als Dienst.
Horizon aus Sicht der Leistungsverwaltung
Bei der Leistungsüberwachung und Fehlerbehebung ähnelt Horizon einer Client-/Server-Architektur, bei der der Client über das WAN-Netzwerk angebunden ist. Die Komponenten „Netzwerk“ und „Datencenter“ sind unabhängig voneinander. Sie verwenden verschiedene Metriksätze und müssen als eigene Einheit überwacht werden. Sie verfügen über einen eigenen Satz an Problembehebungsaktionen. In einem großen Unternehmen wird das Netzwerk von einem eigenen Team verwaltet.
Das Management Pack for Horizon führt dann eine separate Überwachung durch und stellt den KPI bereit.
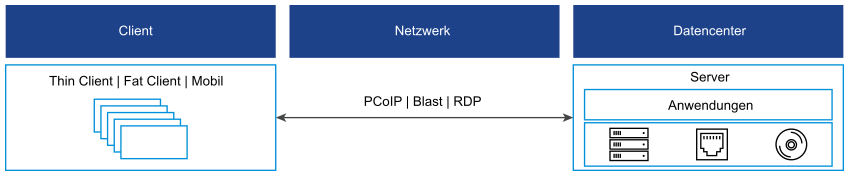
Die Clientkomponente gilt als letzter Schwerpunkt der Leistungsüberwachung, da sie im Wesentlichen wie ein Fernseher funktioniert. Sie zeigt die übertragenen Pixel an und akzeptiert einfache Eingaben. Zudem werden Probleme mit einem Client häufig isoliert. Netzwerk- und Datencenterausfälle können sich jedoch auf zahlreiche Benutzer auswirken.
Die drei Prozesse zur Fehlerbehebung in Bezug auf die Leistung
Zu den drei verschiedenen Prozessen bei der Leistungsverwaltung gehören:
-
Planung. An dieser Stelle können Sie das Leistungsziel angeben. An wie viele Millisekunden Plattenlatenz dachten Sie, als Sie diese vSAN-Architektur erstellt haben? 10 ms auf VM-Ebene (nicht auf vSAN-Ebene) sind ein guter Anfang.
-
Überwachung. Hier können Sie „Plan“ und „Tatsächlich“ vergleichen. Stimmt die Realität mit dem überein, was Ihre Architektur leisten sollte? Wenn nicht, müssen Sie sie ändern.
-
Fehlerbehebung. Sie können dies tun, wenn die Realität schlechter als der Plan ist, und nicht, wenn eine Beschwerde vorliegt. Da Sie sich nicht mit der Fehlerbehebung aufhalten möchten, empfiehlt sich ein proaktives Vorgehen.

Die beiden Metriken der Leistungsverwaltung
Der primäre Indikator für die Leistung lautet „Konflikt“. Die meisten Kunden beobachten die Auslastung, da sie fürchten, dass bei einer hohen Auslastung Probleme auftreten. Bei diesen Problemen handelt es sich um einen Konflikt. Konflikte manifestieren sich in unterschiedlichen Formen. Sie können als Warteschlange, Latenz, verworfene und abgebrochene Objekte oder Kontextwechsel auftreten.
Verwechseln Sie extrem hohe Auslastungsindikatoren nicht mit Leistungsproblemen. Gerade weil auf einem ESXi-Host Ballooning, Komprimierung und Auslagerung stattfinden, deutet dies nicht auf ein Problem Ihrer VM mit der Arbeitsspeicherleistung hin. Die Leistung des Hosts können Sie daran messen, wie gut er seine VMs versorgt. Obwohl sie im Zusammenhang mit der ESXi-Auslastung steht, basiert die Leistungsmetrik nicht auf der Nutzung. Sie basiert auf Konfliktmetriken.
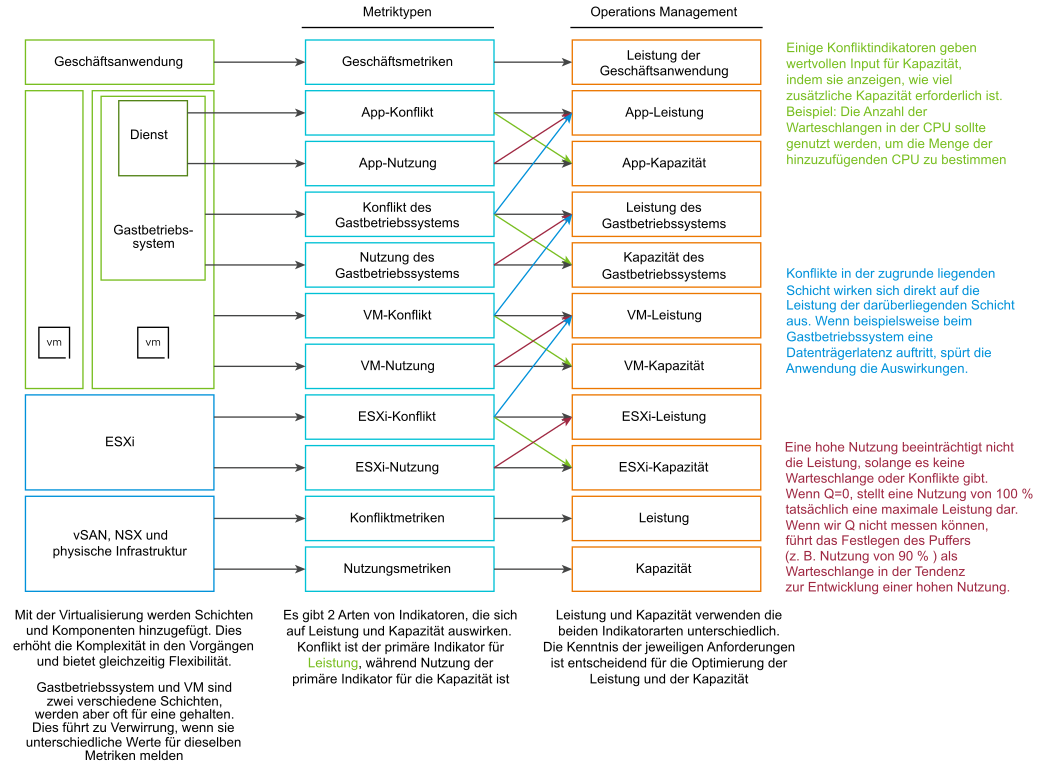
Möglicherweise können VMs im Cluster bei geringer Clusternutzung schlechte Leistungswerte aufweisen. Ein Hauptgrund dafür ist, dass bei der Clusternutzung die Anbieterebene (ESXi) betrachtet wird, während bei der Leistung ein einzelner Verbraucher (VM) betrachtet wird.
Aus der Perspektive der Leistungsverwaltung ist der vSphere-Cluster der kleinste logische Baustein der Ressourcen. Der Ressourcenpool und die Hostaffinität der VM können zwar einen kleineren Anteil ausmachen, sie sind jedoch in betrieblicher Hinsicht komplex und können nicht die zugesagte Qualität des IaaS-Diensts liefern. Der Ressourcenpool kann keine differenzierte Dienstklasse bereitstellen. In Ihrem SLA ist beispielsweise angegeben, dass Premium-Desktops zwei Mal schneller als reguläre Desktops sind, da sie mit 200 % berechnet werden. Der Ressourcenpool kann Premium-Desktops zwei Mal mehr Anteile zuweisen. Diese zusätzlichen Anteile, die die Hälfte der CPU-Bereitschaft ausmachen, können nicht im Voraus ermittelt werden.
Tiefe und Breite
Proaktive Überwachung muss aus verschiedenen Blickwinkeln erfolgen. Wenn bei einem Benutzer Leistungsprobleme auftreten, müssen Sie folgende Fragen stellen:
-
Wie schlimm ist es? Sie möchten die Schwere des Problems beurteilen.
-
Wie viele Benutzer sind betroffen? Sie möchten das Ausmaß des Problems beurteilen.
Die Antwort auf die zweite Frage wirkt sich auf den Verlauf der Fehlerbehebung aus. Handelt es sich um ein einzelnes oder ein weit verbreitetes Problem? Bei einem einzelnen Problem betrachten Sie das betroffene Objekt genauer. Bei einem weit verbreiteten Problem betrachten Sie die allgemeinen Bereiche (z. B. Cluster, Datenspeicher, Ressourcenpools und Hosts), die vom betroffenen Objekt gemeinsam genutzt werden.
Da der Durchschnitt in diesem Fall zu spät zur Verfügung steht, denken Sie daran, dass Sie nicht nach der durchschnittlichen Leistung fragen müssen. Zum Zeitpunkt einer schlechten Durchschnittsleistung ist wahrscheinlich die Hälfte der Population betroffen.
Count() funktioniert besser als Percentage(), wenn die Anzahl der Mitglieder sehr hoch ist. In einer VDI-Umgebung mit 100.000 Benutzern stellen fünf betroffene Benutzer beispielsweise 0,005 % dar. Eine Überwachung unter Verwendung der Anzahl ist einfacher, da sich diese in der Praxis auswirkt.
Gesamtabläufe
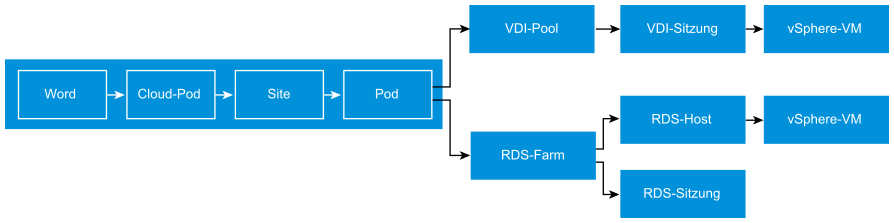
Die Management Pack for Horizon-Dashboards wurden nicht isoliert konzipiert. Sie bilden einen Ablauf, in dem beim Drilldown Kontext übergeben wird. Das folgende Beispiel zeigt, wie Sie aus der Vogelperspektive einen Drilldown zur zugrunde liegenden VM durchführen können, die eine Sitzung unterstützt. Das erste Dashboard enthält alle Pods in der Horizon-Welt. Über dieses Dashboard können Sie einen Drilldown zur RDS-Farm oder zum VDI-Pool durchführen. Innerhalb der Verzweigungen können Sie einen Drilldown zu einzelnen Sitzungen durchführen.
Überlegungen zum Entwurf
In allen Leistungs-Dashboards wurden dieselben Designprinzipien verwirklicht. Sie sind ähnlich aufgebaut, weil unterschiedliche Designs die Benutzer irritieren könnten. Die Dashboard verfolgen dasselbe Ziel.
Das Dashboard ist horizontal aufgebaut und enthält die Abschnitte „Übersicht“ und „Details“.
-
Der Abschnitt „Übersicht“ befindet sich im Allgemeinen im oberen Bereich des Dashboards und bietet eine Übersicht.
-
Der Abschnitt „Details“ befindet sich unterhalb des Abschnitts „Übersicht“ und enthält Detailinformationen zu einem bestimmtem Objekt. Handelt es sich beispielsweise um die Leistung einer VM, können Sie die Leistungsdetails einer bestimmten VM abrufen.
Dieser Abschnitt „Detail“ ist außerdem mit schnellem Kontextwechsel ausgestattet, da Sie die Leistung mehrerer Objekte während der Behebung von Leistungsfehlern überprüfen können. Das Dashboard „RDS-Host-Leistung“ bietet Ihnen beispielsweise alle für den RDS-Host spezifischen Informationen und ermöglicht Ihnen, die KPIs ohne Bildschirmwechsel anzuzeigen. Sie können von einem RDS-Host zu einem anderen wechseln, und die Details anzeigen, ohne mehrere Fenster öffnen zu müssen.
Aus der Perspektive der Benutzeroberfläche zeigt das Dashboard die Daten nach einem progressiven System an, um die Informationsflut zu minimieren und sicherzustellen, dass die Webseite schnell geladen wird. Solange die Browsersitzung aktiv ist, bleibt die letzte Auswahl erhalten.
Farben als Bedeutung
Im Dashboard wird die Bedeutung durch Farben vermittelt, da verschiedene Schwellenwerte verwendet werden.
| Anzahl | Verwendeter Schwellenwert |
|---|---|
| KPI | Grün: 75 % - 100 % Gelb: 50 % - 75 % Orange: 25 % - 50 % Rot: 0 % - 25 % Dementsprechend liegen die Schwellenwerte bei 25 %, 50 % und 75 %. |
| Anzahl bestimmter Elemente im roten Bereich. Beispiel: Anzahl der VDI-Sitzungen mit rotem KPI. |
Dieser Wert sollte immer bei 0 liegen, da es keine VDI-Sitzungen mit einem KPI-Wert geben sollte, der in den roten Bereich fällt. Dementsprechend betragen die Schwellenwerte 1, 2 und 3. Soll „Rot“ mit einer Anzahl von 1 angezeigt werden, können Sie den Wert auf 0,1, 0,2 oder 1 festlegen. |
Die angezeigten Zahlen sollten sich in der grünen Zone befinden (75 % - 100 %). Der Durchschnittswert liegt vielleicht nicht bei 100 %, sollte aber auf jeden Fall im grünen Bereich zu finden sein.
Tabelle als Erkenntnis
Bei einer Tabelle handelt es sich um eine einfache Liste, in der jede Zeile ein Objekt darstellt und jede Spalte einen einzelnen Wert enthält. Auf diese Weise werden Hunderte von Zeilen aufgelistet, die gefiltert und sortiert werden können. Jeder Zellenwert kann auch farbcodiert sein.
Tabellen eignen sich zur Angabe von Details. Zusammengefasst besteht das Hauptproblem jedoch in der Bereitstellung von Erkenntnissen über einen bestimmten Zeitraum, da jede Zelle nur einen Wert enthalten kann. Wie erhält man Erkenntnisse über die Geschehnisse in der Vergangenheit? Wie kann man beispielsweise die Leistung der vergangenen Woche anzeigen? Für die letzten sieben Tage stehen Tausende von Datenpunkten zur Verfügung. Welcher soll ausgewählt werden?
In VMware Aria Operations 8.2 stehen ein paar mögliche Optionen zur Verfügung.
-
Die aktuelle Anzahl. Es ist nützlich, die aktuelle Situation anzuzeigen. Hierbei werden die Geschehnisse der letzten fünf Minuten jedoch nicht angezeigt.
-
Der Durchschnitt des Zeitraums. Der Durchschnittswert ist ein verzögerter Indikator. Bei einem schlechten Durchschnittswert sind wahrscheinlich etwa 50 % der Werte ebenfalls schlecht.
-
Der schlechteste Wert des Zeitraums. Dieser kann zu hoch sein, da bereits ein Extremwert ausreicht. Ein einzelner Wert unter Hunderten von Datenpunkten kann gegebenenfalls ein Ausreißer sein. Dieser Wert eignet sich hervorragend für die Erkennung von Spitzen, muss jedoch ergänzt werden.
-
Das 95. Perzentil. Hierbei handelt es sich um einen geeigneten Mittelwert zwischen Durchschnitts- und schlechtestem Wert. Für die Leistungsüberwachung bietet das 95. Perzentil eine bessere Übersicht als der Durchschnittswert.
Verwenden Sie den schlechtesten und den 95. Perzentilwert zusammen und beginnen Sie mit dem 95. Perzentil. Wenn die Werte weit auseinander liegen, weist dies darauf hin, dass es sich bei dem schlechtesten Wert wahrscheinlich um einen Ausreißer handelt.
Für mehr Transparenz sollten Sie darüber nachdenken, das 98. Perzentil als Ergänzung zum 95. Perzentil und dem schlechtesten Wert hinzuzufügen.
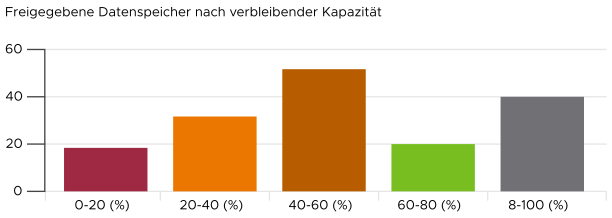
Balkendiagramm als Erkenntnis
Verteilungsdiagramme gibt es in vielen Formen, wobei das Balkendiagramm eines der bekanntesten ist. Ein Balkendiagramm kann verwendet werden, um Erkenntnisse über große Datensätze bereitzustellen. Beispielsweise werden freigegebene vSphere-Datenspeicher nach verbleibender Kapazität angezeigt. Sie werden in fünf Buckets eingeordnet, von der niedrigsten verbleibenden Kapazität bis zur höchsten. Jedem Bucket wird eine Farbe zur Vermittlung von Bedeutung zugewiesen. Eine Kapazität größer als 80 % wird in grauer Farbe dargestellt, da eine große Menge nicht genutzter Kapazität auf eine Verschwendung von Ressourcen hinweist.