









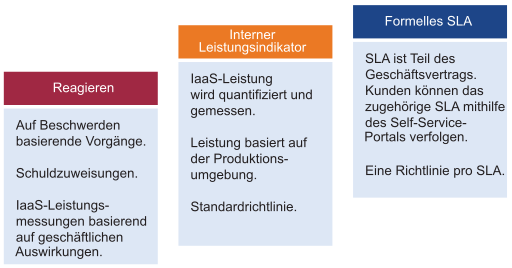
Bei der Leistung wird sichergestellt, dass Arbeitslasten die nötigen Ressourcen erhalten. Wichtige Leistungsindikatoren (KPI) können verwendet werden, um Leistungsprobleme im Zusammenhang mit Arbeitslasten zu ermitteln. Verwenden Sie diese KPIs, um Dienstebenen zugeordnete SLAs zu definieren. Diese Dashboards verwenden KPIs, um die Leistung der Arbeitslasten auf der Verbraucherebene und die Gesamtleistung der Arbeitslasten auf der Anbieterebene anzuzeigen.
SLA ist die formelle Geschäftsvereinbarung, die Sie mit ihren Kunden haben. In der Regel liegt die SLA zwischen dem-IaaS-Drittanbieter (Infrastrukturteam) und dem-IaaS-Kunden (dem Anwendungsteam oder Geschäftsbereich). Die formelle SLA muss operativ umgestaltet werden; z. B. benötigt sie mehr als nur technische Änderungen, und Sie müssen möglicherweise den Vertrag, den Preis (nicht die Kosten), den Prozess und die Mitarbeiter überprüfen. KPI umfasst SLA-Metriken und zusätzliche Metriken, die eine Frühwarnungsfunktion bieten. Wenn Sie nicht über eine SLA verfügen, beginnen Sie mit einem internen KPI. Sie müssen die tatsächliche Leistung Ihres IaaS verstehen und profilieren. Verwenden Sie die Standardeinstellungen in VMware Aria Operations , wenn Sie über keinen eigenen Schwellenwert verfügen, da diese Schwellenwerte ausgewählt wurden, um proaktive Maßnahmen zu vereinfachen.
Die drei Prozesse der Leistungsverwaltung
- Planung. Setzen Sie Ihre Leistungsziele. Wenn Sie ein vSAN entwerfen, müssen Sie wissen, wie viele Millisekunden Datenträgerlatenz Sie haben möchten. 10 Millisekunden auf der VM-Ebene (nicht der vSAN Ebene) ist ein guter Anfang.
- Überwachung. Vergleichen Sie Ihr Soll mit dem Ist. Stimmt die Realität mit dem überein, was Ihre Architektur leisten sollte? Andernfalls müssen Sie sie ändern.
- Fehlerbehebung. Wenn die Realität nicht dem Plan entspricht, müssen Sie Ihre Architektur proaktiv anpassen und nicht auf Probleme und Beschwerden warten.
- Konflikt: Dies ist der primäre Indikator.
- Konfiguration: Überprüfen Sie die Versionsinkompatibilitäten.
- Verfügbarkeit: Überprüfen Sie, ob behebbare Fehler vorhanden sind. vMotion-Einfrierzeit, sperren. Hierfür ist Log Insight erforderlich.
- Auslastung: Überprüfen Sie diesen Parameter zum Schluss. Wenn die ersten drei Parameter passend sind, können Sie diesen Schritt überspringen.
Die drei Ebenen der Leistungsverwaltung
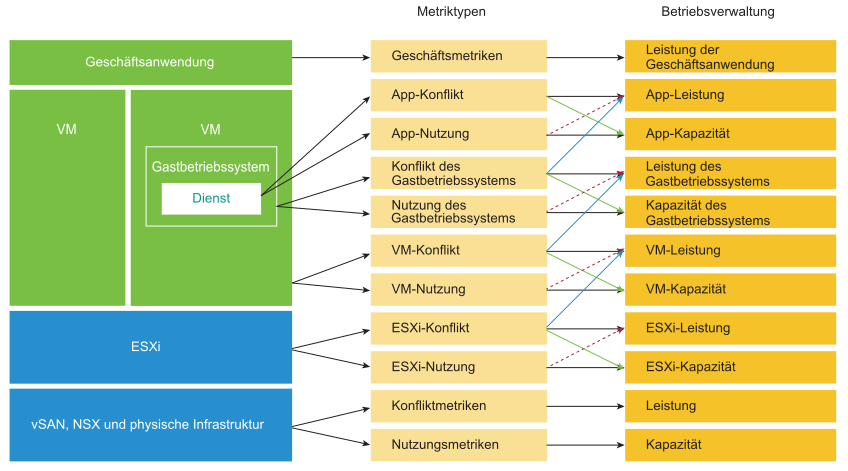
Es gibt drei Hauptbereiche von Unternehmensanwendungen. Jeder dieser Bereiche verfügt über einen eigenen Satz von Teams. Jedes Team hat eine Reihe eindeutiger Verantwortlichkeiten und benötigt die zugehörige Qualifikation. Die drei Bereiche sind Unternehmen, Anwendung und IaaS. Informationen zu den drei Ebenen und den typischen Fragen, die auf jeder Ebene gestellt werden, finden Sie in der folgenden Grafik. 
Leistungsverwaltung beruht weitgehend auf gezieltem Weglassen. Bei dieser Methode wird jede Ebene genau untersucht, um festzustellen, ob die jeweilige Ebene Leistungsprobleme verursacht. Deshalb ist eine einzelne Metrik zwingend erforderlich, um anzugeben, ob eine bestimmte Ebene ausgeführt wird. Diese primäre Metrik wird treffend als KPI (Key Performance Indicator) bezeichnet.
Die obere Ebene hängt von der darunter liegenden ab. Deshalb ist die Quelle des Konflikts in der Regel die Infrastrukturebene. Konzentrieren Sie sich daher zunächst auf die untere Ebene, da sie als Grundlage für die darüber liegende Ebene dient. Praktischerweise handelt es sich bei dieser Ebene in der Regel um eine horizontale Ebene, die eine Reihe generischer Infrastrukturdienste bereitstellt. Hierbei spielt es keine Rolle, welche Geschäftsanwendungen auf der Ebene ausgeführt werden.
Die beiden Metriken der Leistungsverwaltung
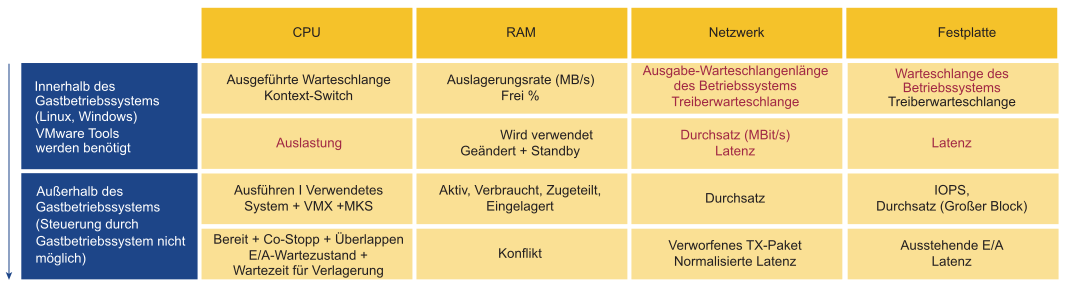
Der primäre Indikator für die Leistung lautet „Konflikt“. Die meisten Benutzer beobachten die Auslastung, da sie fürchten, dass bei einer hohen Auslastung Probleme auftreten könnten. Bei diesen Problemen handelt es sich um einen Konflikt. Konflikte präsentieren sich auf verschiedene Arten, wie z. B. Warteschlangen, Latenz, Paketverluste, Abbrüche und Kontextwechsel.
Verwechseln Sie jedoch nicht Indikatoren für extrem hohe Nutzung mit einem Leistungsproblem. Wenn bei Ihrem ESXi-Host Ballooning, Komprimierung und ein hoher Grad an Auslagerung auftreten, bedeutet dies nicht, dass Ihre VM ein Leistungsproblem hat. Die Leistung des Hosts können Sie daran messen, wie gut er seine VMs versorgt. Obwohl die Leistung mit der ESXi-Hostnutzung zusammenhängt, basiert die Leistungsmetrik nicht auf der Nutzung, sondern auf Konfliktmetriken.
| Infrastrukturkonfiguration | Konfiguration der VM und des Gastbetriebssystems |
|---|---|
ESXi-Einstellungen
|
VM: Grenzwert, Anteil und Reservierung
|
Netzwerk
|
Größe: NUMA-Effekt. NUMA-Knoten übergreifende VM. |
Clustereinstellungen
|
Snapshot. E/A wird 2x verarbeitet. VM-Treiber. |
vSAN
|
Windows- oder Linux-Prozessdurcheinander, Prozessausreißer und Warteschlange auf Betriebssystemebene. |
Aus der Perspektive der Leistungsverwaltung ist der vSphere-Cluster der kleinste logische Baustein der Ressourcen. Der Ressourcenpool und die Hostaffinität der VM können zwar einen kleineren Anteil ausmachen, Sie sind jedoch in betrieblicher Hinsicht komplex und können nicht die zugesagte Qualität des IaaS-Dienstes liefern. Der Ressourcenpool kann keine differenzierte Dienstklasse bereitstellen. Beispielsweise sagt Ihr SLA aus, dass „Gold“ zwei Mal schneller als „Silber“ ist, da es mit 200 % mehr berechnet wird. Der Ressourcenpool kann „Gold“ zwei Mal mehr Anteile geben. Ob diese zusätzlichen Anteile die Hälfte der CPU-Bereitschaft ausmachen, kann vorab nicht ermittelt werden.
VM-Leistung
Die KPI-Indikatoren können für einige Benutzer sehr technisch sein. Daher bietet VMware Aria Operations eine Grundlinie, um ihnen das Verständnis zu erleichtern. Sie können den Schwellenwert anpassen, nachdem Sie Ihre Umgebung profiliert haben. Diese Profilerstellung ist eine gute Übung, da die meisten Kunden nicht über eine Baseline verfügen. Für die Profilerstellung benötigen Sie eine erweiterte Edition. 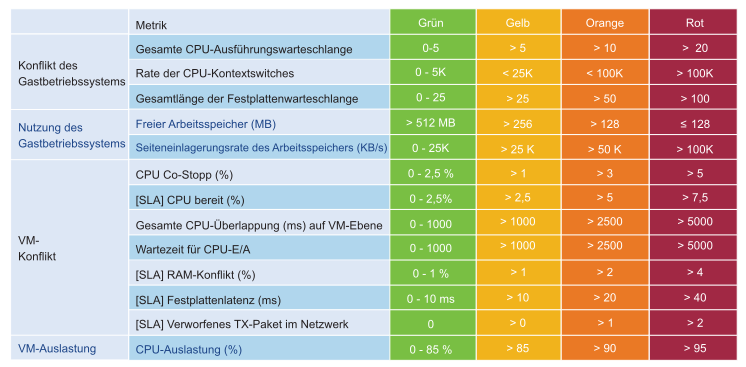
Leistungsmetriken
| IaaS | VM-Indikator | Schwellenwert |
|---|---|---|
| CPU | Bereit | 2,5% |
| RAM | Konflikt | 1 % |
| Festplatte | Latenz | 10 ms |
| Netzwerk | Verworfene TX-Pakete | 0 |
Bei der Tabelle handelt es sich um ein Beispiel für einen strengen Grenzwert. Ein hoher Leistungsstandard wird verwendet, da es sich hierbei um einen internen KPI für den Verbrauch des Infrastrukturteams handelt. Es handelt sich nicht um ein externes formelles SLA, das von den Kunden bestätigt wird. Zwischen dem internen KPI und dem externen SLA muss ein Puffer bestehen, damit das Operations-Team Frühwarnungen erhält und reagieren kann, bevor das externe SLA nicht eingehalten werden kann. Ein hoher Standard wirkt sich auch auf die Entwicklungsumgebung aus. Wenn der Standard für die am wenigsten leistungsfähige Umgebung gilt, sollte er nicht auf die kritischere Entwicklungsumgebung angewendet werden.
Ein einzelner Schwellenwert wird verwendet, um den Betrieb zu vereinfachen. Das bedeutet, dass das Maß für die Leistung der Produktionsumgebung höher als das der Entwicklungsumgebung ist. Es wird erwartet, dass die Leistung der Entwicklungsumgebung schlechter als die der Produktionsumgebung ist, während alle anderen Wert gleich bleiben. Ein einzelner Schwellenwert hilft dabei, den Unterschied in der Dienstqualität zu erläutern, der durch eine andere Dienstklasse zur Verfügung gestellt wird. Beispiel: Wenn Sie weniger bezahlen, erhalten Sie weniger Leistung. Bei der Hälfte des Preises erhalten Sie nur halb so viel Leistung.
Die vier in der Tabelle erwähnten IaaS-Elemente (CPU, Arbeitsspeicher, Festplatte und Netzwerk) werden in jedem Erfassungszyklus bewertet. Der Erfassungszeitraum ist auf 5 Minuten festgelegt und stellt somit einen angemessenen Wert für die Überwachung dar. Ein einminütiger Zeitraum für das SLA ist zu kurz und führt zu einem Anstieg der Kosten oder zu einer Verringerung des Schwellenwerts.
Technische Erwägungen
Alle Leistungs-Dashboards sind nach denselben Designprinzipien aufgebaut. Sie sind absichtlich ähnlich gestaltet, da sie ja sie das gleiche Ziel haben und es verwirrend wäre, wenn jedes Dashboard anders aussähe.
Die Dashboards verfügen über zwei getrennte Bereiche: Übersicht und Details.
- Der Übersichts-Bereich befindet sich in der Regel ganz oben am Dashboard, um das Gesamtbild zu zeigen.
- Der Details-Bereich befindet sich unterhalb des Übersichts-Bereichs. Er zeigt Ihnen Detailinformationen für ein bestimmtes Objekt an. Beispielsweise können Sie den detaillierten Leistungsbericht einer bestimmten VM aufrufen.
Verwenden Sie im Bereich „Detail“ den Schnellkontext-Schalter, um während der Behebung von Leistungsproblemen die Leistung mehrerer Objekte zu überprüfen. Wenn Sie z. B. die VM-Performance betrachten, können Sie die VM-spezifischen Informationen und die KPIs einsehen, ohne den Bildschirm verlassen zu müssen. Sie können von einer VM zu einer anderen wechseln, und die Details anzeigen, ohne mehrere Fenster öffnen zu müssen.
Das Dashboard zeigt die Daten nach einem progressiven System an, um die Informationsflut zu minimieren und sicherzustellen, dass die Webseite schnell geladen wird. Wenn Ihre Browsersitzung offen bleibt, merkt sich die Oberfläche Ihre letzten gewählten Optionen.
Viele der Leistungs- und Kapazitäts-Dashboards haben ein ähnliches Layout, da diese operativen Säulen viele Gemeinsamkeiten aufweisen.
