









Der Autoscaler-Dienst von VMware Cloud on AWS überwacht die Integrität Ihrer SDDC-Infrastruktur, erkennt ausstehende und tatsächliche Fehler und standardisiert die Infrastruktur automatisch, indem Hosts vor oder nach einem Ausfall ersetzt werden.
Die AWS-Infrastruktur ist zuverlässig, aber Fehler sind selbst in der zuverlässigsten Infrastruktur unvermeidlich. In der Säule Zuverlässigkeit des AWS-Architektur-Frameworks werden Designkonzepte für die Zuverlässigkeit in der Cloud erörtert. VMware Cloud on AWS erweitert diese Prinzipien, indem es die zugrunde liegende Infrastruktur abstrahiert und die Funktionen für die vorausschauende Fehleranalyse von vCenter Server und ESXi nutzt, um eine reaktive Standardisierung bei Ausfällen und eine prädiktive Standardisierung bereitzustellen, die verhindern kann, dass Fehler die Arbeitslasten beeinträchtigen.
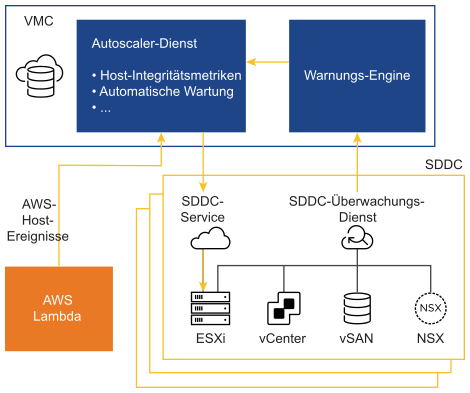
Architektur auf hoher Ebene für die automatische Standardisierung
- AWS sendet Informationen auf VMware-Hostebene zur geplanten Wartung, insbesondere AWS-Ereignisse. Der Autoscaler-Dienst empfängt diese Benachrichtigungen und behebt automatisch alle Probleme innerhalb des SDDC.
- Ein Überwachungsdienst auf SDDC-Ebene empfängt Benachrichtigungen von den zugrunde liegenden VMware Cloud on AWS-Komponenten des Systems.
Reaktive Standardisierung
Die reaktive automatische Standardisierung überwacht Hardware- und Softwarefehler und versucht, Probleme auf verschiedene Arten zu beheben. Die automatische Standardisierung ist ein interner Prozess, der sich ständig weiterentwickelt. VMware Cloud on AWS-Benutzer haben keinen Zugriff auf den Workflow oder seine Konfiguration. Zum besseren Verständnis geben wir Ihnen hier einen Überblick über die gegenwärtig durchgeführten Schritte.
- 1: Überwachen
- VMware Cloud on AWS überwacht kontinuierlich die Integrität jedes Hosts in Ihrem SDDC. Wenn ein Fehler erkannt wird, wird ein Ereignis an die automatische Wartung gesendet.
- 2: Auf vorübergehende Ereignisse warten
- Einige der erkannten Fehler können vorübergehend sein. Wenn das Überwachungssystem zum Beispiel einen Host aufgrund eines vorübergehenden Verbindungsproblems nicht erreichen kann. Die automatische Standardisierung wartet fünf Minuten, um zu ermitteln, ob das Problem vorübergehend ist. Ist dies der Fall, wird die automatische Standardisierung erneut aktiviert, ohne eine Aktion durchzuführen.
- 3: Host hinzufügen
- Wenn der Fehler nach fünf Minuten nicht behoben ist, beginnt die automatische Standardisierung mit dem Hinzufügen eines Hosts zum SDDC. Das präventive Hinzufügen eines Hosts auf seine Weise stellt sicher, dass der Host bei Bedarf verfügbar ist. Beachten Sie, dass dieser Host erst berechnet wird, wenn er einen fehlerhaften Host in Ihrem SDDC ersetzt.
- 4: Fehlertyp bestimmen und Maßnahmen ergreifen
- Hosts können aus verschiedenen Gründen ausfallen und erfordern unterschiedliche Aktionen. Ein Ausfall einer vSAN-Festplatte auf einem Host, der noch mit einem vCenter Server verbunden ist, kann beispielsweise durch einen Soft Reboot behoben werden, während ein PSOD-Host einen harten Neustart benötigt.
- 5: Prüfen der Integrität des Hosts
- Im nächsten Schritt wird geprüft, ob die Standardisierungsmaßnahme am Host erfolgreich waren. Wenn der ausgefallene Host nach einem weichen oder harten Neustart nun fehlerfrei funktioniert, wird die automatische Wartung die Funktion des SDDC nicht weiter unterbrechen. Sie erfasst alle weiteren erforderlichen Maßnahmen, führt diese aus und entfernt den neuen Host, der in Schritt 3 präventiv hinzugefügt wurde.
- 6: Host ersetzen
- Wenn der ausgefallene Host nicht wieder aktiviert werden kann, entfernt der Autoscaler-Dienst den ausgefallenen Host und ersetzt ihn durch den in Schritt 3 hinzugefügten Host. vSphere HA und vSAN werden ausgelöst, und Tags für Computing-Richtlinien werden an den neuen Host angehängt.
Präventive Standardisierung
- Ein neuer Host wird zum Cluster hinzugefügt. Tags werden aus dem zu ersetzenden Host in diesen neuen Host kopiert.
- Der fehlgeschlagene Host wird in den Wartungsmodus mit vollständiger Datenevakuierung versetzt. Dadurch werden alle VMs und/oder vSAN-Daten unterbrechungsfrei auf andere Hosts innerhalb des Clusters verschoben.
- Der fehlgeschlagene Host wird aus dem Cluster entfernt.
Autoscaler-Ereignisse
Wenn der Autoscaler-Dienst ein Fehlerereignis empfängt, ermittelt er den Fehlertyp und ergreift dann die entsprechenden Maßnahmen. Das SDDC-Aktivitätsprotokoll enthält alle Autoscaler-Aktivitäten, zeigt aber nicht das Fehlerereignis an, das die Aktivität ausgelöst hat.
- vCenter Server-Ereignisse.
-
- Ein Ereignis wird ausgelöst, um den Verbindungsstatus des Hosts zu prüfen
- Ein Ereignis wird ausgelöst, wenn beispielsweise die Verbindung zum ESXi-Host getrennt wurde oder dieser nicht reagiert.
- DAS-Ereignisse
-
- vSphere HA-Ereignisse: Ein Ereignis wird erstellt, wenn keine Kommunikation zum Master-Knoten besteht oder HA nicht aktiv ist. (FDM)
- Wenn ein Host ausfällt, meldet das HA-System einen Hostfehler.
- vSAN Ereignisse
-
- Bei einem Festplattenfehler auf einem der Hosts.
- Wenn die Verbindung zum vSAN-Host getrennt wird.
- EDRS-Ereignisse (keine Fehler)
- Upgrade: EDRS deaktivieren. Für Wartungsaktivitäten wird häufig ein zusätzlicher Host benötigt. Dieser wird im Rahmen des Wartungsereignisses hinzugefügt. EDRS ist während der geplanten Wartung deaktiviert, damit diese Aktivitäten keine vertikalen oder horizontalen Skalierungsereignisse auslösen können.
- AWS-Ereignisse
-
- Geplante Wartungsereignisse. Benachrichtigung von AWS, dass ein Integritätsproblem der Instanz erkannt wurde und die Instanz evakuiert werden muss.
- Personal Health Dashboard (PHD). Ein Ereignis-Stream, der Einblick in verschiedene Hardwarekomponenten bietet und es VMware ermöglicht, Hardwarefehler präventiv zu erkennen.
- Systemstatusprüfung. Überwacht den Systemzustand der AWS-Systeme, auf die sich die Instanz stützt. Diese Prüfung meldet Probleme, die nur von AWS behoben werden können. In vielen Fällen sind diese Probleme vorübergehend, und es sind keine Maßnahmen erforderlich.
- Instanzstatusprüfung. Überwacht die Software- und Netzwerkkonfiguration für jede Instanz. Diese Prüfung überwacht die Verfügbarkeit der Instanz, indem in regelmäßigen Abständen ARP-Anforderungen an die Netzwerkkarte ausgegeben werden. Zusätzlich zur Berichterstellung über die Verfügbarkeit von Instanzen auf der EC2-Ebene. Instanzstatusprüfungen überwachen die zugrunde liegende Hardwareauslastung und melden Netzwerkprobleme, Arbeitsspeicherausschöpfung, beschädigtes Dateisystem, Kernelfehler usw. Im Gegensatz zu Systemstatusprüfungen ist bei Instanzstatusprüfungen eine VMware-Interaktion erforderlich.
- SDDC-Ereignisse
- vCenter Server-Hostintegrität.
