









Das Runbook für die VMware Integrated OpenStack-CLI-Integritätsprüfung behandelt die viocli check health-Fälle und -Verfahren zur Behebung der gemeldeten Probleme.
Sie können eine der folgenden Lösungen für die in viocli check health gemeldeten Probleme ausführen:
Knoten nicht bereit
- Um den Knotenstatus abzurufen, führen Sie den Befehl
osctl get nodeaus.osctl get node NAME STATUS ROLES AGE VERSION controller-dqpzc8r69w Ready openstack-control-plane 17d v1.17.2+vmware.1 controller-lqb7xjgm9r Ready openstack-control-plane 17d v1.17.2+vmware.1 controller-mvn5nmdrsp Ready openstack-control-plane 17d v1.17.2+vmware.1 vxlan-vm-111-161.vio-mgmt.eng.vmware.com Ready master 17d v1.17.2+vmware.1
- Starten Sie den Kubelet-Dienst auf
not ready nodemit dem folgenden Befehl neu:viosshcmd ${not_ready_node} 'sudo systemctl restart kubelet' - Um den Status dieses Problems erneut zu überprüfen, führen Sie
viocli check health -n kubernetesaus.
Knoten mit doppelter IP-Adresse
Weitere Informationen zu Knoten mit doppelter IP-Adresse finden Sie unter KB 82608.
Um den Status dieses Problems erneut zu überprüfen, führen Sie viocli check health -n kubernetes aus.
Knoten fehlerhaft
- Führen Sie
osctl describe node <node>aus, um den Integritätsstatus des Knotens abzurufen.Type Status LastHeartbeatTime LastTransitionTime Reason Message ---- ------ ----------------- ------------------ ------ ------- NetworkUnavailable False Sat, 05 Jun 2021 10:47:53 +0000 Sat, 05 Jun 2021 10:47:53 +0000 CalicoIsUp Calico is running on this node MemoryPressure False Mon, 07 Jun 2021 01:21:55 +0000 Mon, 07 Jun 2021 00:57:29 +0000 KubeletHasSufficientMemory kubelet has sufficient memory available DiskPressure False Mon, 07 Jun 2021 01:21:55 +0000 Mon, 07 Jun 2021 00:57:29 +0000 KubeletHasNoDiskPressure kubelet has no disk pressure PIDPressure False Mon, 07 Jun 2021 01:21:55 +0000 Mon, 07 Jun 2021 00:57:29 +0000 KubeletHasSufficientPID kubelet has sufficient PID available Ready True Mon, 07 Jun 2021 01:21:55 +0000 Mon, 07 Jun 2021 00:57:32 +0000 KubeletReady kubelet is posting ready status
- Wenn der Status
NetworkUnavailable,MemoryPressure,DiskPressureoderPIDPressurewahr ist, befindet sich der Kubernetes-Knoten in einem fehlerhaften Status. Daher müssen Sie den Systemstatus und die Ressourcennutzung des fehlerhaften Knotens überprüfen. - Um den Status dieses Problems erneut zu überprüfen, führen Sie
viocli check health -n kubernetesaus.
Knoten mit hoher Festplattennutzung
- Melden Sie sich bei dem Knoten an, der eine hohe Festplattennutzung meldet.
#viossh ${node} - Überprüfen Sie die Festplattennutzung mit
df -h. - Entfernen Sie nicht verwendete Dateien auf dem Knoten.
- Um den Status dieses Problems erneut zu überprüfen, führen Sie
viocli check health -n kubernetesaus.
Evicted werden, wenden Sie sich an den VMware Support, um Abhilfe zu schaffen.
- Melden Sie sich beim Knoten mit hoher Inode-Nutzung an.
#viossh ${node} - Überprüfen Sie die Inode-Nutzung mit
df -i /. - Entfernen Sie nicht verwendete Dateien auf dem Knoten.
- Um den Status dieses Problems erneut zu überprüfen, führen Sie
viocli check health -n kubernetesaus.
Knoten mit Snapshot
- Melden Sie sich bei vCenter an und entfernen Sie die Snapshots, die für die VMware Integrated OpenStack-Controller-Knoten erstellt wurden.
- Wenn der Fehler Verbindung mit vCenter fehlgeschlagen gemeldet wird, müssen Sie die vCenter-Verbindungsinformationen in VMware Integrated OpenStack überprüfen.
- Um den Status dieses Problems erneut zu überprüfen, führen Sie
viocli check health -n kubernetesaus.
FQDN kann nicht aufgelöst werden
- Überprüfen Sie über den VMware Integrated OpenStack-Verwaltungsknoten die DNS-Auflösung mit den folgenden Befehlen:
#viosshcmd ${node_name} -c "nslookup ${reported_host}" #toolbox -c "dig $host +noedns +tcp" - Wenn dies fehlschlägt, überprüfen Sie den im VMware Integrated OpenStack-Knoten (/etc/resolve.conf) konfigurierten DNS-Server.
- Um den Status dieses Problems erneut zu überprüfen, führen Sie
viocli check health -n connectivityaus.
NTP im Knoten nicht synchronisiert
Weitere Informationen zum NTP-Knoten finden Sie unter KB 78565. Um den Status dieses Problems erneut zu überprüfen, führen Sie viocli check health -n connectivity aus.
LDAP nicht erreichbar
Überprüfen Sie die Verbindung von den VMware Integrated OpenStack-Knoten zum angegebenen LDAP-Server und stellen Sie sicher, dass die LDAP-Einstellung (Benutzer, Anmeldedaten) in VMware Integrated OpenStack korrekt ist. Um den Status dieses Problems erneut zu überprüfen, führen Sie viocli check health -n connectivity aus.
vCenter nicht erreichbar
Wenn vCenter nicht erreichbar ist, überprüfen Sie die Verbindung von den VMware Integrated OpenStack-Knoten zum angegebenen vCenter und stellen Sie sicher, dass die vCenter-Einstellung (Benutzer, Anmeldedaten) in VMware Integrated OpenStack korrekt ist. Um den Status dieses Problems erneut zu überprüfen, führen Sie viocli check health -n connectivity aus.
NSX nicht erreichbar
Wenn NSX nicht erreichbar ist, überprüfen Sie die Verbindung von den VMware Integrated OpenStack-Knoten zum angegebenen NSX-Server und stellen Sie sicher, dass die NSX-Einstellung (Benutzer, Anmeldedaten) korrekt ist. Um den Status dieses Problems erneut zu überprüfen, führen Sie viocli check health -n connectivity aus.
- Sie müssen alle im Dokument Integrieren von VMware Integrated OpenStack mit vRealize Log Insight aufgeführten Voraussetzungen bereithalten.
- Um den Status dieses Problems erneut zu überprüfen, führen Sie
viocli check health -n connectivityaus.
- Stellen Sie sicher, dass der DNS-Server mit dem VMware Integrated OpenStack-API-Zugriffsnetzwerk kommunizieren kann.
- Sie müssen über alle im Dokument Aktivieren der Designate-Komponente aufgeführten Voraussetzungen verfügen.
- Um den Status dieses Problems erneut zu überprüfen, führen Sie
viocli check health -n connectivityaus.
Falsche Netzwerkpartition im rabbitmq-Knoten
- Um die erneute Erstellung des
rabbitmq-Knotens zu erzwingen, starten Sie eine Ausführung auf dem VMware Integrated OpenStack-Verwaltungsknoten.#osctl delete pod ${reported_rabbitmq_node} - Um den Status dieses Problems erneut zu überprüfen, führen Sie
viocli heath check -n rabbitmqaus.
WSREP-Cluster-Problem
viocli get deployment verwendet wird, wenden Sie sich an den VIO-Support. Folgen Sie andernfalls den folgenden Anweisungen.
- Führen Sie den folgenden Befehl auf dem VMware Integrated OpenStack Manager-Knoten aus:
#kubectl -n openstack exec -ti mariadb-server-0 -- mysql --defaults-file=/etc/mysql/admin_user.cnf --connect-timeout=5 --host=localhost -B -N -e "show status;" #kubectl -n openstack exec -ti mariadb-server-1 -- mysql --defaults-file=/etc/mysql/admin_user.cnf --connect-timeout=5 --host=localhost -B -N -e "show status;" #kubectl -n openstack exec -ti mariadb-server-2 -- mysql --defaults-file=/etc/mysql/admin_user.cnf --connect-timeout=5 --host=localhost -B -N -e "show status;"
- Wenn die Ausgabe
wsrep_cluster_sizevonmariadb-server-xnicht 3 ist, erstellen Sie denmariadb-Knoten neu mit:#kubectl -n openstack delete pod mariadb-server-x
- Wenn es eine große Lücke von
wsrep_last_commitedzwischen den drei Knoten gibt, starten Sie den oder diemariadb-Knoten mit einer kleineren Zahl mitwsrep_last_committedneu.#kubectl -n openstack delete pod mariadb-server-x
- Um den Status dieses Problems erneut zu überprüfen, führen Sie
viocli check health -n mariadbaus.
Große Tabellen in der OpenStack-Datenbank
nova.instancesSiehe KB 83768.
glance.imagesStandardmäßig sind Cron-Jobs aktiviert, um vorläufig gelöschte Datensätze in der Glance-Datenbank automatisch zu bereinigen.
Überprüfen Sie, ob der Cron-Job „db purge“ aktiviert ist und ordnungsgemäß ausgeführt wird.
viocli update glance jobs: db_purge: age_in_days: 60 max_rows: 1000 db_purge_images: age_in_days: 60 max_rows: 1000 manifests: cron_job_db_purge: true cron_job_db_purge_images: truecron_job_db_purgewird verwendet, um die DB-Bereinigung für die Glance-Tabelle, jedoch nicht der „image“-Tabelle, zu aktivieren.cron_job_db_purge_imageswird verwendet, um die DB-Bereinigung für die „image“-Glance-Tabelle zu aktivieren.--age_in_days NUMbereinigt nur Zeilen, die für länger als NUM Tage gelöscht waren. Die Standardeinstellung ist 30 Tage.--max_rows NUMbereinigt maximal NUM Zeilen aus jeder Tabelle. Die Standardeinstellung lautet 100.cinder.volumesundcinder.volume_attachmentManuelle Schritte zum Bereinigen der Cinder-Datenbank
- Sichern Sie die Cinder-DB.
osctl exec -ti mariadb-server-0 -- mysqldump --defaults-file=/etc/mysql/admin_user.cnf -R cinder > /tmp/cinder_backup.sql
- Melden Sie sich beim cinder-api-xxxxx-Pod an.
osctl exec -ti deploy/cinder-api bash
- Bereinigen Sie die Cinder-Datenbank.
cinder-manage db purge 60
Hinweis:Befehlssyntax: cinder-manage db purge
age_in_days.Positionsargumente:
age_in_daysBereinigen gelöschter Zeilen, die älter als das Alter in Tagen sind.Möglicherweise müssen Sie
age_in_daysanpassen, um mehr vorläufig gelöschte Datensätze in der Cinder-Datenbank zu bereinigen.
Zu viele Legacy-Netzwerkressourcen in der Steuerungskomponente
Eine Lösung finden Sie unter Fehler beim Aktivieren des Ceilometer, wenn 10.000 Neutron-Mandantennetzwerke vorhanden sind in den Versionshinweisen zu VMware Integrated OpenStack 7.1.
OpenStack Keystone funktioniert nicht ordnungsgemäß
- Sie müssen versuchen, sich von der Toolbox aus als Admin-Benutzer bei OpenStack anzumelden und Befehle wie
openstack user listundopenstack user showauszuführen. Wenn die Anmeldung fehlschlägt, erfassen und überprüfen Sie die Keystone-Protokolle auf Fehlermeldungen. - Rufen Sie die Liste der keystone-api-Pods ab:
#osctl get pod | grep keystone-api
- Erfassen Sie die Protokolle:
#osctl logs keystone-api-xxxx -c keystone-api >keystone-api-xxxx.log
- Um den Status dieses Problems zu überprüfen, führen Sie
viocli check health -n keystoneaus.
Leere Netzwerk-ID in Neutron-Datenbank
Informationen zu einer Lösung finden Sie unter KB 76455. Um den Status dieses Problems zu überprüfen, führen Sie viocli check health -n neutron aus.
Falsche vCenter-Referenz in Neutron
- Rufen Sie den Namen
vioclusterab.Wennosctl get viocluster
viocluster1zurückgegeben wird, fahren Sie mit dem nächsten Schritt fort. Andernfalls handelt es sich um einen falschen Alarm. Wenden Sie sich an den VMware Support, um eine dauerhafte Lösung zu finden. - Rufen Sie die
viocluster-vCenter-Konfiguration ab.# osctl get viocluster viocluster1 -oyaml
- Sichern Sie die Neutron-Konfiguration.
osctl get neutron -oyaml > neutron-<time-now>.yml
- Bearbeiten Sie Neutron CR
cmd:osctl edit neutron neutron-xxxund ändern Sie dann die CR-Spezifikation, indem Sie die in Schritt 1 befindliche vCenter-Referenz ersetzen.spec: conf: plugins: nsx: dvs: dvs_name: vio-dvs host_ip: .VCenter:vcenter812:spec.hostname <---- change the vcenter instance to viocluster refered host_password: .VCenter:vcenter812:spec.password <---- same above host_username: .VCenter:vcenter812:spec.username <---- insecure: .VCenter:vcenter812:spec.insecure <---- - Um den Status dieses Problems zu überprüfen, führen Sie
viocli check health -n neutronaus.
- Rufen Sie den Nova-Pod ab.
osctl get pod | grep nova
Überprüfen Sie, ob sich der Nova-Pod nicht im Status Wird ausgeführt befindet.
- Löschen Sie den Pod mit:
osctl delete pod xxx.Warten Sie, bis der neue Pod den Status Wird ausgeführt hat.
- Um den Status dieses Problems zu überprüfen, führen Sie
viocli check health -n novaaus.
Veralteter Nova-Dienst
Informationen zum veralteten Nova-Dienst finden Sie unter KB 78736. Um den Status dieses Problems zu überprüfen, führen Sie viocli check health -n nova aus.
- Melden Sie sich bei der Toolbox an und versuchen Sie, den redundanten Nova-Dienst und einige Nova-Dienste ohne Endpoints zu finden und zu löschen.
# openstack catalog list

# openstack service list

- Ermitteln Sie den verwendeten Nova-Dienst.
# openstack endpoint list |grep nova
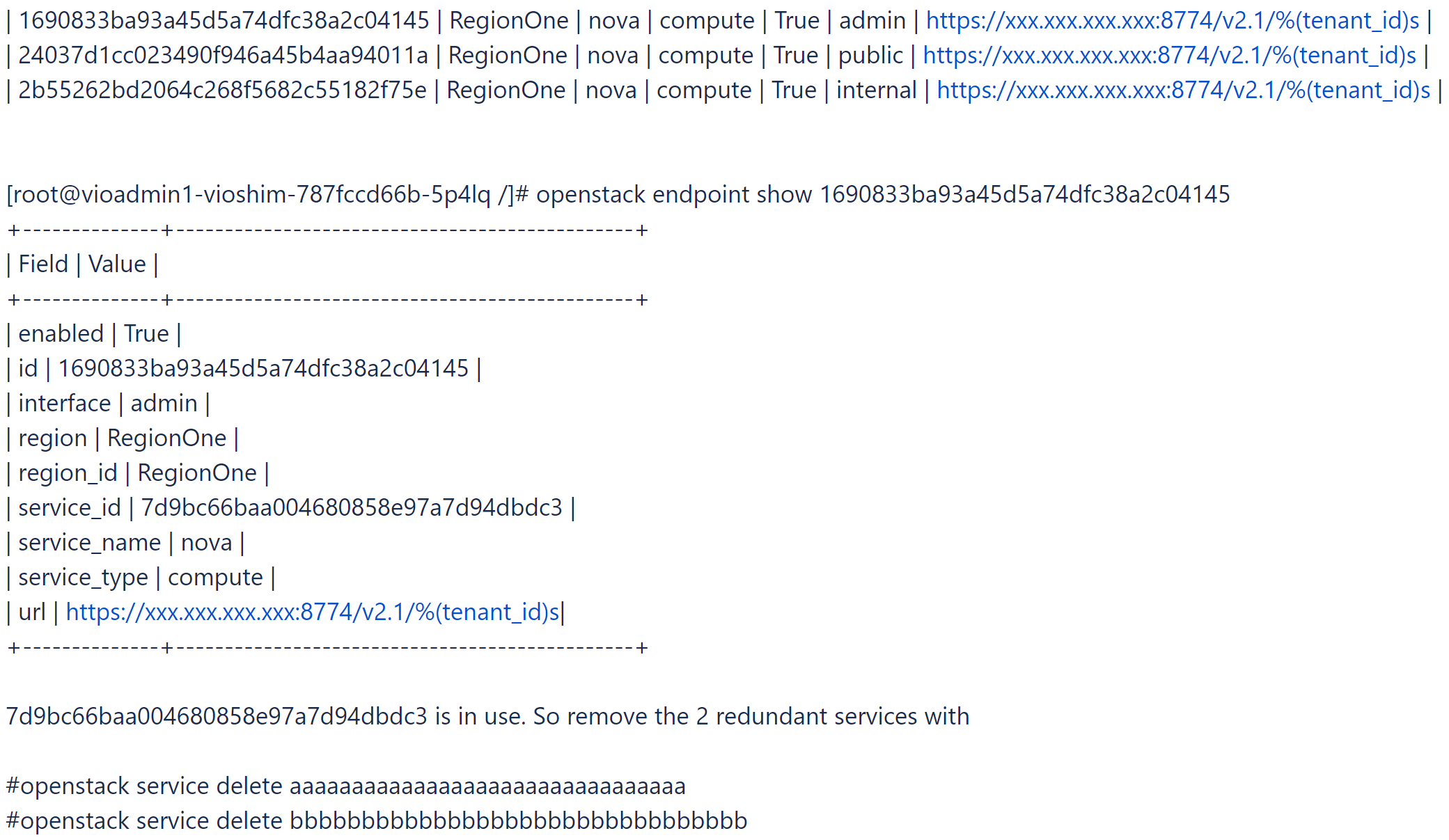
- Um den Status dieses Problems zu überprüfen, führen Sie
viocli check health -n novaaus.
Bestimme Nova Compute-Pods werden aufgrund einer Zeitüberschreitung beim Start weiterhin neu gestartet
Dieser Alarm weist darauf hin, dass sich bestimmte Nova Compute-Pods gegebenenfalls in einem fehlerhaften Zustand befinden. Wenden Sie sich an den VMware Support, um eine Lösung zu finden. Um den Status des Problems zu überprüfen, führen Sie viocli check health -n nova aus.
Glance-Datenspeicher nicht erreichbar
- Rufen Sie die Glance-Dienstliste ab.
osctl get glance
- Rufen Sie die Informationen zu den Glance-Datenspeichern ab.
osctl get glance $glance-xxx -o yaml
- Suchen Sie nach Informationen zur Datenspeicherverbindung.
spec: conf: backends: vmware_backend: vmware_datastores: xxxx vmware_server_host: xxxx vmware_server_password: xxxx vmware_server_username: .xxxx - Wenn die Informationen falsch sind, überprüfen Sie die vCenter- und Datenspeicherverbindung und aktualisieren Sie sie entsprechend mit
osctl update glance $glance-xxx. - Um den Status dieses Problems zu überprüfen, führen Sie
viocli check health -n glanceaus.
Glance-Image(s) mit falschem Speicherortformat
Die Meldung weist darauf hin, dass bestimmte Glance-Images ein falsches Speicherortformat aufweisen. Wenden Sie sich an den VMware Support, um eine Lösung zu finden. Um den Status des Problems zu überprüfen, führen Sie viocli check health -n glance aus.
Cinder-Dienste nicht verfügbar
- Rufen Sie den Cinder-Pod ab.
osctl get pod | grep cinder | grep -v Completed
Überprüfen Sie, ob sich der Cinder-Pod nicht im Status Wird ausgeführt befindet.
- Löschen Sie den Pod mit:
osctl delete pod xxx.Warten Sie, bis für den neuen Pod der Status Wird ausgeführt angezeigt wird.
- Um den Status dieses Problems zu überprüfen, führen Sie
viocli check health -n cinderaus.
- Melden Sie sich beim
cinder-volume-Pod an.#osctl exec -ti cinder-volume-0 bash
- Überprüfen und listen Sie veraltete Cinder-Dienste auf.
#cinder-manage service list
Beispiel:#cinder-manage service list
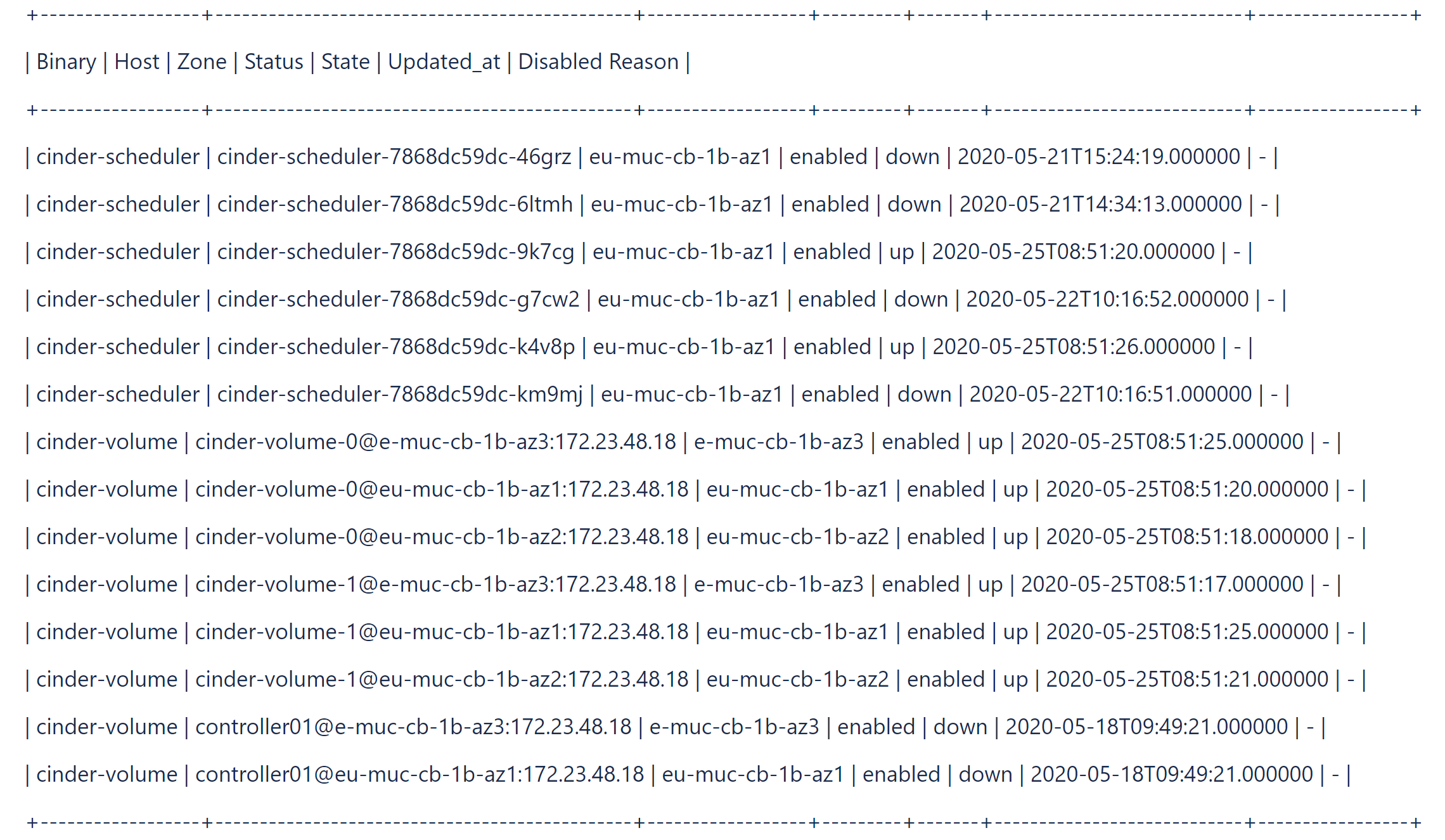
- Entfernen Sie veraltete Cinder-Dienste mit dem Befehl
cinder-manageimcinder-volume-Pod.# cinder-manage service remove cinder-scheduler cinder-scheduler-7868dc59dc-km9mj # cinder-manage service remove cinder-volume controller01@e-muc-cb-1b-az3:172.23.48.18
- Um den Status dieses Problems zu überprüfen, führen Sie
viocli check health -n cinderaus.
- Um den erforderlichen Befehl auf dem VMware Integrated OpenStack-Verwaltungsknoten zu installieren, führen Sie
tdnf install xxxaus. - Um den Status dieses Problems zu überprüfen, führen Sie
viocli check health -n basicaus.
Leere Kubernetes-Knotenliste oder Knoten nicht erreichbar
Führen Sie osctl get nodes über den VMware Integrated OpenStack-Verwaltungsknoten aus und überprüfen Sie, ob die korrekte Ausgabe erfasst werden kann. Um den Status dieses Problems zu überprüfen, führen Sie viocli check health -n basic aus.
Kein ausgeführter Pod
Führen Sie osctl get pod |grep xxx über den VMware Integrated OpenStack-Verwaltungsknoten aus und prüfen Sie, ob ein laufender Pod aus der Ausgabe erfasst werden kann. Um den Status dieses Problems zu überprüfen, führen Sie viocli check health -n basic aus.
Pod nicht erreichbar
Führen Sie osctl exec -it $pod_name Bash vom VMware Integrated OpenStack-Verwaltungsknoten aus und überprüfen Sie, ob Sie sich beim Pod anmelden können. Um den Status dieses Problems zu überprüfen, führen Sie viocli check health -n basic aus.
Befehlsausführung im Pod
Überprüfen Sie die Protokolldatei /var/log/viocli_health_check.log auf Details und versuchen Sie, den Befehl vom VMware Integrated OpenStackVerwaltungsknoten aus erneut auszuführen. Um den Status dieses Problems zu überprüfen, führen Sie viocli check health -n basic aus.
- Melden Sie sich bei der Toolbox an und führen Sie einige OpenStack-Befehle aus, z. B.
openstack catalog list, und prüfen Sie, ob der Befehl die korrekte Rückgabe erfassen kann. - Für weitere Meldungen aktivieren Sie die Debug-Option. Beispiel:
openstack catalog list --debug
- Um den Status dieses Problems zu überprüfen, führen Sie
viocli check health -n basicaus.
- Rufen Sie das OpenStack-Administratorkennwort ab und vergleichen Sie es mit
OS_PASSWORD.osctl get secret keystone-keystone-admin -o jsonpath='{.data.OS_PASSWORD} - Wenn in
keystone-keystone-adminkein Wert gespeichert ist, aktualisieren Sie ihn mitosctl edit secret keystone-keystone-admin. - Um den Status dieses Problems zu überprüfen, führen Sie
viocli check health -n basicaus.
vCenter-Cluster ist überlastet/Hosts sind stark ausgelastet
Überprüfen Sie die vCenter-Hosts für die VIO-Steuerungsebene und fügen Sie weitere Ressourcen hinzu, oder bereinigen Sie bestimmte nicht verwendete Instanzen, um die Auslastung der Ressourcen zu verringern.
- Überprüfen Sie das Protokoll „/var/log/viocli_health_check.log“ und suchen Sie nach der aktuellen Meldung für
check_vio_cert_expire, um herauszufinden, wie lange das Zertifikat bereits abgelaufen ist oder wann das Zertifikat abläuft. - Informationen zum Aktualisieren des Zertifikats finden Sie unter Aktualisieren des Zertifikats für VMware Integrated OpenStack.
- Um den Status des Problems erneut zu überprüfen, führen Sie
viocli check health -n connectivityaus.
LDAP-Zertifikat abgelaufen/läuft demnächst ab
- Überprüfen Sie das Protokoll „/var/log/viocli_health_check.log“ und suchen Sie nach der aktuellen Meldung für
check_ldap_cert_expire, um herauszufinden, wie lange das Zertifikat bereits abgelaufen ist oder wann das Zertifikat abläuft. - Informationen zum Aktualisieren des Zertifikats finden Sie unter Aktualisieren des Zertifikats für LDAP-Server.
Hinweis: Wenn LDAP nicht konfiguriert ist, wird die Prüfung mit der Protokollmeldung
No LDAP Certificate foundübersprungen. - Um den Status des Problems erneut zu überprüfen, führen Sie
viocli check health -n connectivityaus.
vCenter-Zertifikat abgelaufen/läuft demnächst ab
- Überprüfen Sie das Protokoll „/var/log/viocli_health_check.log“ und suchen Sie nach der aktuellen Meldung für
check_vcenter_cert_expire, um herauszufinden, wie lange das Zertifikat bereits abgelaufen ist oder wann das Zertifikat abläuft. - Informationen zum Aktualisieren des Zertifikats finden Sie unter Konfigurieren von VMware Integrated OpenStack mit aktualisiertem vCenter- oder NSX-T-Zertifikat.
Hinweis: Wenn das vCenter für die Verwendung einer unsicheren Verbindung konfiguriert ist, wird die Prüfung mit der Protokollmeldung
Use insecure connectionübersprungen. - Um den Status des Problems erneut zu überprüfen, führen Sie
viocli check health -n connectivityaus.
NSX-Zertifikat ist abgelaufen/läuft demnächst ab
- Überprüfen Sie das Protokoll „/var/log/viocli_health_check.log“ und suchen Sie nach der aktuellen Meldung für
check_nsx_cert_expire, um herauszufinden, wie lange das Zertifikat bereits abgelaufen ist oder wann das Zertifikat abläuft. - Informationen zum Aktualisieren des Zertifikats finden Sie unter Konfigurieren von VMware Integrated OpenStack mit aktualisiertem vCenter- oder NSX-T-Zertifikat.
Hinweis: Wenn NSX für die Verwendung einer unsicheren Verbindung konfiguriert ist, wird die Prüfung mit der Protokollmeldung
Use insecure connectionübersprungen. - Um den Status des Problems erneut zu überprüfen, führen Sie
viocli check health -n connectivityaus.
Dienst xxx beendet
Führen Sie viocli start xxx aus, um den Dienst zu starten. Um den Status dieses Problems zu überprüfen, führen Sie viocli check health -n lifecycle_manager aus.
- Überprüfen Sie das Protokoll „/var/log/viocli_health_check.log“ und durchsuchen Sie die aktuelle Meldung für
check_cluster_workload, die Details zur Ressourcennutzung enthält. - Beheben Sie die gemeldeten Ressourcenprobleme und überprüfen Sie den Status dann erneut durch Ausführen von
viocli check health -n kubernetes.
