









Das Unternehmen ACME Enterprise hat zwei private Datencenter-Sites in den USA, eines in Palo Alto und ein anderes in Austin. Während einer geplanten Wartung oder eines unvorhergesehenen Ausfalls der Site in Palo Alto stellt das Unternehmen alle Anwendungen auf der Austin-Site wieder her.
- Erneute Zuordnung der Gateway-IP-Adresse
- Synchronisieren der Sicherheitsrichtlinien
- Aktualisieren anderer Dienste, die die Anwendungs-IP-Adressen verwenden, z. B. DNS, Sicherheitsrichtlinien und andere Dienste
Dieser herkömmliche Ansatz für die Notfallwiederherstellung verbraucht viel zusätzliche Zeit, um die Wiederherstellung auf der Site in Austin zu 100 % abzuschließen. Um eine schnelle Notfallwiederherstellung mit minimalen Ausfallzeiten zu erzielen, entscheidet sich ACME Enterprise für die Bereitstellung von NSX Data Center 6.4.5 oder höher in einer Cross-vCenter-Umgebung, wie im folgenden logischen Topologie-Diagramm gezeigt.
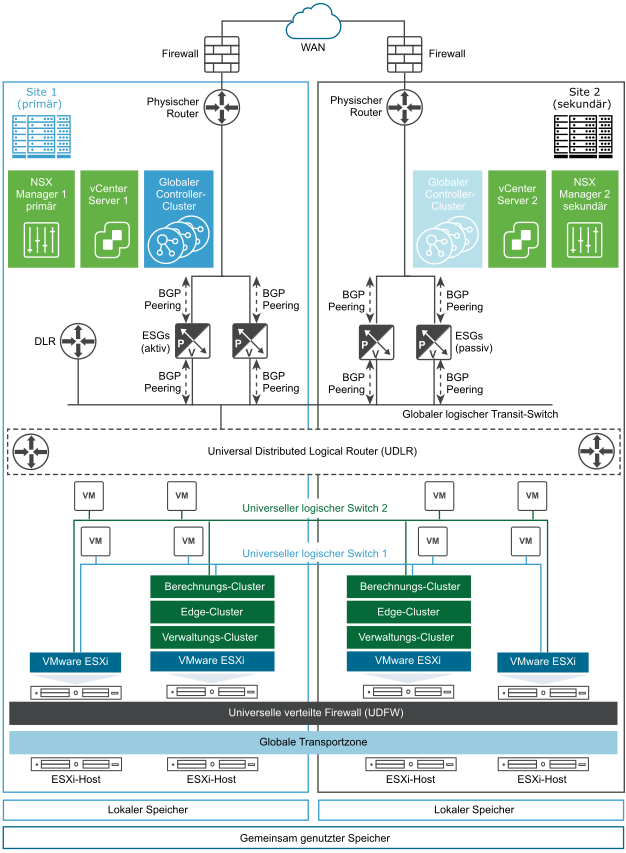
In dieser Topologie ist Site 1 in Palo Alto das primäre (geschützte) Datencenter und Site 2 in Austin ist das sekundäre (Wiederherstellungs-)Datencenter. Jede Site verfügt über einen einzigen vCenter Server, der mit dem eigenen NSX Manager gekoppelt ist. NSX Manager auf Site 1 (Palo Alto) wird die Rolle des primären NSX Manager zugewiesen und NSX Manager auf Site 2 (Austin) die des sekundären NSX Manager.
ACME Enterprise stellt Cross-vCenter NSX auf beiden Sites in einem Aktiv/Passiv-Modus bereit. 100 % der Anwendungen (Workloads) werden auf Site 1 in Palo Alto und 0 % auf Site 2 in Austin ausgeführt. Das heißt, standardmäßig befindet sich Site 2 im passiven oder Standby-Modus.
Beide Sites verfügen über eigene Computing-, Edge- und Verwaltungs-Cluster und ESGs, die für diese Site lokal sind. Da der lokale Ausgang auf dem UDLR deaktiviert ist, wird nur eine einzige UDLR-Steuerungs-VM auf der primären Site bereitgestellt. Die UDLR-Kontroll-VM ist mit dem logischen Universal Transit-Switch verbunden.
Der NSX-Administrator erstellt universelle Objekte, die zwei vCenter-Domänen auf Site 1 und 2 umfassen. Die globalen logischen Netzwerke verwenden universelle Netzwerk- und Sicherheitsobjekte, z. B. Universal Logical Switches (ULS), Universal Distributed Logical Router (UDLR) und Universal Distributed Firewall (UDFW).
- Erstellt eine globale Transportzone aus dem primären NSX Manager.
- stellt einen universellen Controller-Cluster mit drei Controller-Knoten bereit
- Fügt die lokalen Computing-, Edge- und Management-Cluster zur globalen Transportzone aus den primären NSX Managern hinzu.
- Deaktiviert den lokalen Ausgang und ermöglicht ECMP sowie Graceful Restart auf der UDLR-Kontroll-VM (Edge-Appliance-VM).
- Konfiguriert das dynamische Routing mit BGP zwischen den Edge Services Gateways (ESGs) und der UDLR-Kontroll-VM.
- deaktiviert ECMP und aktiviert Graceful Restart auf beiden ESGs
- Deaktiviert die Firewall auf beiden ESGs, da ECMP auf den UDLR-Kontroll-VM aktiviert ist und um sicherzustellen, dass jeder Datenverkehr zugelassen wird.
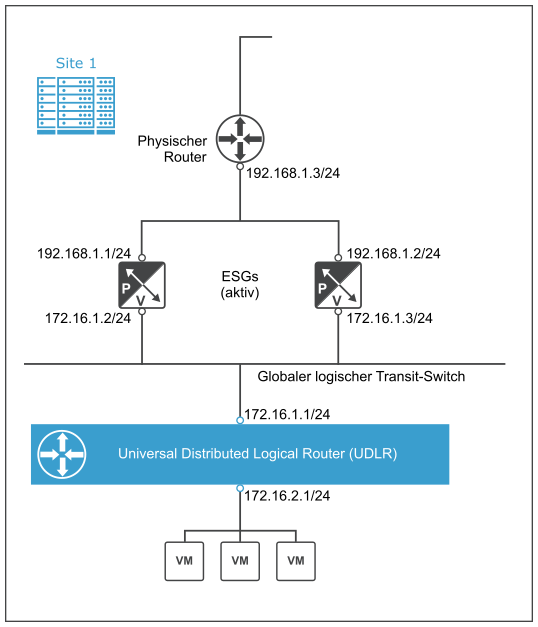
Das folgende Diagramm zeigt eine Beispielkonfiguration der Uplink- und Downlink-Schnittstellen auf den ESGs und UDLRs auf Site 1.
- Fügt die lokalen Computing-, Edge- und Management-Cluster zur globalen Transportzone aus den sekundären NSX Managern hinzu.
- Gibt ähnliche Downlink-Schnittstellen auf den ESGs an, wie sie auf Site 1-ESGs konfiguriert sind.
- Gibt eine ähnliche BGP-Konfiguration auf den ESGs an, wie sie auf Site 1-ESGs konfiguriert ist.
- Schaltet die ESGs auf der sekundären Site aus, wenn Site 1 aktiv ist.
- Szenario 1: Geplanter vollständiger Site-Ausfall auf Site 1
- Szenario 2: Ungeplanter vollständiger Site-Ausfall auf Site 1
- Szenario 3: Vollständiges Failback auf Site 1
