









Beim NSX Controller-Cluster handelt es sich um ein verteiltes Scale-Out-System, bei dem jedem Controller-Knoten ein Satz an Rollen zugewiesen ist. Diese Rollen legen die Art von Aufgaben fest, die der Knoten implementieren kann. Um die Ausfallsicherheit und die Leistung zu erhöhen, sollte die Bereitstellung der Controller-VMs auf drei unterschiedlichen Hosts erfolgen.
Mithilfe der horizontalen Fragmentierung („Sharding“) werden Arbeitslasten auf alle NSX Controller-Clusterknoten verteilt. Beim Sharding werden NSX Controller-Arbeitslasten in kleine Datensätze aufgeteilt, damit jede NSX Controller-Instanz dieselbe Arbeitslast verarbeiten muss.
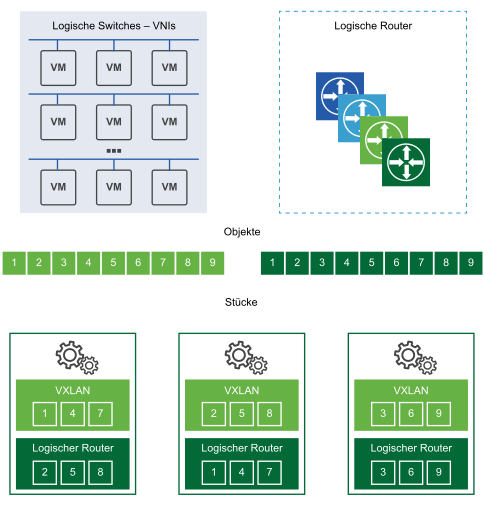
Dies zeigt, dass einzelne Controller-Knoten als Master für bestimmte Instanzen wie logisches Switching, logisches Routing und andere Dienste auftreten können. Nachdem eine Master-NSX Controller-Instanz für eine Rolle ausgewählt wurde, teilt dieser NSX Controller die unterschiedlichen logischen Switches und Router unter allen verfügbaren NSX Controller-Instanzen in einem Cluster auf.
Jedes nummerierte Kästchen in einem Shard steht für die Datensätze, die der Master zum Aufteilen der Arbeitslasten verwendet. Der logische Master-Switch teilt die logischen Switches in Shards auf und weist diese Datensätze den unterschiedlichen NSX Controller-Instanzen zu. Der logische Master-Router teilt die logischen Router ebenfalls in Shards auf und weist diese Datensätze den unterschiedlichen NSX Controller-Instanzen zu.
Diese Datensätze werden den unterschiedlichen NSX Controller-Instanzen in diesem Cluster zugewiesen. Der Master für eine Rolle legt fest, welche NSX Controller-Instanzen welchem Datensatz zugewiesen werden. Wenn Router-Shard 3 eine Anforderung erhält, bekommt dieser Datensatz den Befehl, eine Verbindung zur dritten NSX Controller-Instanz herzustellen. Wenn der Shard 2 der logischen Switches eine Anforderung erhält, wird diese von der zweiten NSX Controller-Instanz verarbeitet.
Wenn eine der NSX Controller-Instanzen in einem Cluster ausfällt, verteilen die Master für die Rollen die Datensätze auf den verbleibenden verfügbaren Clustern. Einer der Controller-Knoten wird als Master für jede Rolle ausgewählt. Dieser Master ist für die Zuteilung der Datensätze zu den einzelnen Controller-Knoten zuständig. Er kann feststellen, ob ein Knoten ausgefallen ist, und teilt die Datensätze auf die verbleibenden Knoten auf. Der Master informiert außerdem die ESXi-Hosts über den Ausfall des Clusterknotens.
Für die Auswahl des Masters für jede Rolle ist eine Mehrheitswahl aller aktiven und inaktiven Knoten im Cluster erforderlich. Das ist der hauptsächliche Grund dafür, dass ein Controller-Cluster immer eine ungerade Anzahl an Knoten enthalten muss.
ZooKeeper
ZooKeeper ist eine Clientserverarchitektur, die für den NSX Controller-Clustermechanismus verantwortlich ist. Der Controller-Cluster wird mit ZooKeeper erkannt und erstellt. Wenn ein Cluster gestartet wird, bedeutet das, dass ZooKeeper auf allen Knoten gestartet wird. Die ZooKeeper-Knoten durchlaufen den Wahlvorgang, um den Controller-Cluster zu bilden. Im Cluster muss ein ZooKeeper-Master-Knoten vorhanden sein. Dieser wird unter den Knoten ausgewählt.
Wenn ein neuer Controller-Knoten erstellt wird, schlägt NSX Manager dem aktuellen Cluster die Knoteninformationen, einschließlich Knoten-IP und -ID, vor. Daher kennt jeder Knoten die Gesamtzahl an Knoten, die für das Clustering zur Verfügung stehen. Bei der Wahl des ZooKeeper-Masters gibt jeder Knoten eine Stimme für die Wahl des Master-Knotens ab. Die Wahl wird erneut ausgelöst, bis ein Knoten die Mehrheit aller Stimmen erhalten hat. In einem Cluster aus drei Knoten muss der Master beispielsweise mindestens zwei Stimmen erhalten.
- Wenn der erste Controller bereitgestellt wird, handelt es sich um einen Sonderfall und der erste Controller wird Master. Daher muss bei der Controller-Bereitstellung auch erst die Bereitstellung des ersten Knotens abgeschlossen sein, bevor weitere Knoten hinzugefügt werden.
- Wenn der zweite Controller hinzugefügt wird, handelt es sich ebenfalls um einen Sonderfall, da die Anzahl an Knoten zu diesem Zeitpunkt gerade ist.
- Wenn der dritte Knoten hinzugefügt wird, erreicht der Cluster einen unterstützten stabilen Status.
ZooKeeper unterstützt jeweils nur einen Ausfall. Das heißt, dass bei Ausfall eines Controller-Knotens der Knoten wiederhergestellt werden muss, bevor ein weiterer Ausfall auftritt. Andernfalls kann es zu Problemen mit der Funktionstüchtigkeit des Clusters geben.
Domänenmanager der zentralen Kontrollebene (Central Control Plane, CCP)
Dabei handelt es sich um die Ebene über ZooKeeper, die die Konfiguration für den Start von ZooKeeper auf allen Knoten bereitstellt. Der Domänenmanager aktualisiert die Konfiguration zwischen allen Knoten im Cluster und fordert dann remote den Start des ZooKeeper-Prozesses an.
Der Domänenmanager ist für das Starten aller Domänen verantwortlich. Um dem Cluster beizutreten, muss die CCP-Domäne mit den CCP-Domänen auf anderen Rechnern kommunizieren. Die Komponente der CCP-Domäne, die die Clusterinitialisierung unterstützt, ist zk-cluster-bootstrap.
Controller-Beziehung zu anderen Komponenten
Der Controller-Cluster ist für die Verwaltung und Bereitstellung von Informationen zu logischen Switches, logischen Routern und VTEPs für die ESXi-Hosts verantwortlich.
Wenn ein logischer Switch erstellt wird, legen die Controller-Knoten im Cluster fest, welcher Knoten im Cluster Master oder Besitzer für diesen logischen Switch wird. Dasselbe gilt, wenn ein logischer Router hinzugefügt wird.
Sobald der Besitzer für einen logischen Switch bzw. Router festgelegt wurde, sendet der Knoten diese Besitzinformationen an die ESXi-Hosts, die zur Transportzone dieses Switches bzw. Routers gehören. Die gesamte Auswahl des Besitzes und das Vorschlagen der Besitzinformationen für die Hosts wird als „Sharding“ bezeichnet. Beachten Sie: Besitz bedeutet, dass der Knoten für alle NSX-Vorgänge für diesen logischen Switch bzw. Router verantwortlich ist. Die anderen Knoten führen keine Vorgänge für diesen logischen Switch aus.
Es darf nur ein Besitzer die Informationsquelle für einen logischen Switch und Router sein. Wenn in einem Controller-Cluster zwei oder mehr Knoten als Besitzer für einen logischen Switch bzw. Router gewählt werden, hat möglicherweise jeder Host im Netzwerk unterschiedliche Informationen zur Informationsquelle für diesen logischen Switch bzw. Router. In diesem Fall kommt es zu einem Netzwerkausfall, da Vorgänge auf der Kontroll- und Datenebene nur eine Informationsquelle aufweisen können.
Wenn ein Controller-Knoten ausfällt, führen die verbleibenden Knoten im Cluster ein Resharding durch, um die Zuständigkeit für den logischen Switch und das logische Routing zu ermitteln.
