









NSX unterstützt Bereitstellungen für mehrere Sites. Dabei können Sie alle Sites von einem zentralen NSX Manager-Cluster aus verwalten.
- Notfallwiederherstellung
- Aktiv-Aktiv
Das folgende Diagramm veranschaulicht eine Bereitstellung für die Notfallwiederherstellung.
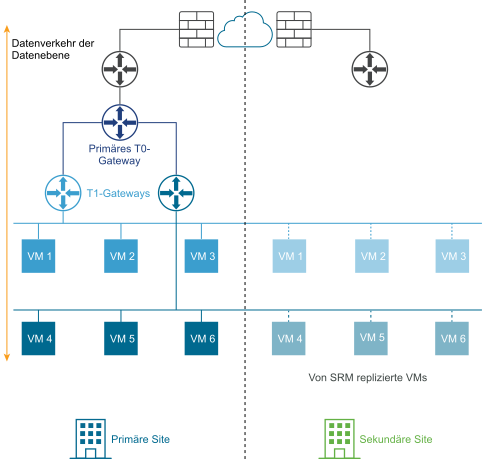
In einer Bereitstellung für die Notfallwiederherstellung verarbeitet NSX an der primären Site Netzwerke für das Unternehmen. Die sekundäre Site steht bereit, um zu übernehmen, wenn ein schwerwiegender Fehler an der primären Site auftritt.
Das folgende Diagramm veranschaulicht eine Aktiv-Aktiv-Bereitstellung.
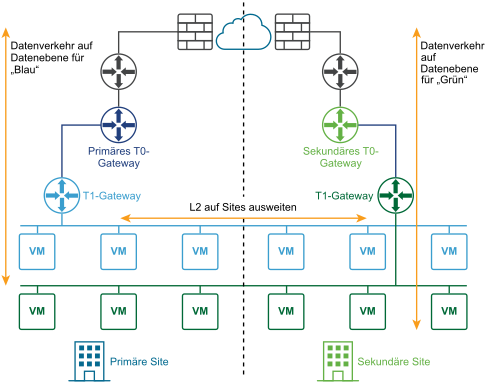
Sie können zwei Sites für die automatische oder manuelle/skriptbasierte Wiederherstellung der Management Plane und der Data Plane bereitstellen.
Automatische Wiederherstellung der Management Plane
- Ein ausgeweiteter vCenter-Cluster mit Konfiguration siteübergreifende HA.
- Ein ausgeweitetes Management-VLAN.
Der NSX Manager-Cluster wird im Management-VLAN bereitgestellt und befindet sich physisch in der primären Site. Wenn eine primäre Site ausfällt, werden die NSX Manager auf der sekundären Site von vSphere HA neu gestartet. Alle Transportknoten werden automatisch erneut mit den neu gestarteten NSX Managern verbunden. Dieser Vorgang dauert ca. 10 Minuten. Während dieser Zeit ist die Management Plane nicht verfügbar, aber die Data Plane wird nicht beeinträchtigt.
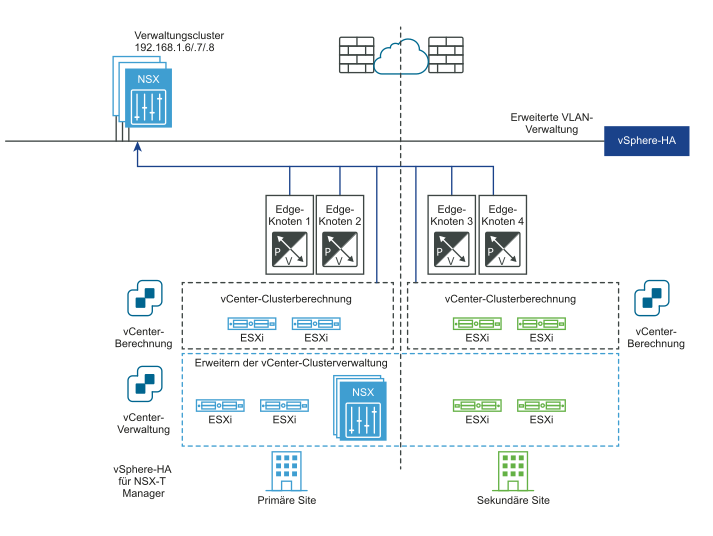
Das folgende Diagramm veranschaulicht die automatische Wiederherstellung der Management Plane.
Vor dem Notfall:
Nach der Notfallwiederherstellung:
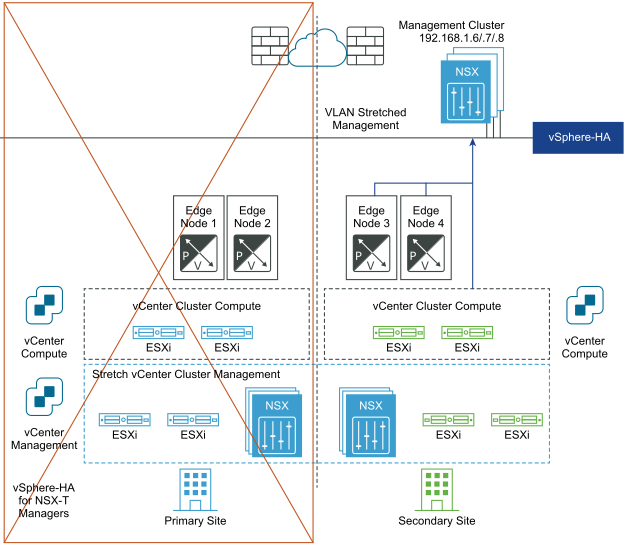
Automatische Wiederherstellung der Data Plane
Sie können Fehlerdomänen für Edge-Knoten konfigurieren, um die automatische Wiederherstellung der Datenebene zu erreichen. Sie können Edge-Knoten innerhalb eines Edge-Clusters in unterschiedlichen Fehlerdomänen bereitstellen. NSX Manager platziert automatisch ein neues aktives Tier-1-Gateway in der bevorzugten Fehlerdomäne und das Standby-Tier-1-Gateway in der anderen Domäne. Beachten Sie, dass ein T1, das vor den Erstellungen der Fehlerdomäne bereitgestellt wurde, seine ursprüngliche Edge-Knotenplatzierung behält und möglicherweise nicht an der gewünschten Position ausgeführt wird. Wenn Sie deren Platzierung korrigieren möchten, bearbeiten Sie T1 und wählen Sie die Edge-Knoten für T1-Aktiv und T1-Standby manuell aus.
- Die maximale Latenz zwischen Edge-Knoten beträgt 10 ms.
- Wenn das asymmetrische vertikale Routing nicht möglich ist, z. B. wenn eine physische Firewall in Northbound-Richtung zum NSX Edge-Knoten verwendet wird, muss der HA-Modus für das Tier-0-Gateway Aktiv/Standby sein und der Failover-Modus muss als „Vorbeugend“ festgelegt sein.
- Wenn asymmetrisches North-South-Routing möglich ist, z. B. wenn die beiden Standorte zwei Gebäude ohne zwischengeschaltete physische Firewall sind, kann der HA-Modus für das Tier-0-Gateway „Aktiv/Aktiv“ sein.
Die Edge-Knoten können VMs oder Bare Metal sein. Der Failover-Modus des Tier-1-Gateways kann „Vorbeugend“ oder „Nicht vorbeugend“ sein, aber „Vorbeugend“ wird empfohlen, um sicherzustellen, dass sich die Tier-0- und Tier-1-Gateways am selben Speicherort befinden.
- Erstellen Sie mithilfe der API Fehlerdomänen für die beiden Sites, z. B. FD1A-Preferred_Site1 und FD2A-Preferred_Site1.
Hinweis: Wenn Sie möchten, dass alle Tier-1-Gateways mit T1-Aktiv in den Edge-Knoten und T1-Standby in anderen Edge-Knoten Teil derselben Fehlerdomäne sind (FD1A-Preferred_Site1 und FD2A-Preferred_Site1), müssen Sie zuerst Tier-1 mit der Option „Vorbeugend“ und dann Ihre primäre Fehlerdomäne (FD1A-Preferred_Site1) erstellen, die auf
preferred_active_edge_services = truefestgelegt ist. Beispiel:POST /api/v1/failure-domains { "display_name": "FD1A-Preferred_Site1", "preferred_active_edge_services": "true" } POST /api/v1/failure-domains { "display_name": "FD2A-Preferred_Site1", "preferred_active_edge_services": "false" } - Konfigurieren Sie mithilfe der API einen Edge-Cluster, der über die beiden Sites ausgedehnt ist. Beispielsweise verfügt der Cluster über die Edge-Knoten EdgeNode1A und EdgeNode1B auf der primären Site und die Edge-Knoten EdgeNode2A und EdgeNode2B auf der sekundären Site. Die aktiven Tier-0- und Tier-1-Gateways werden auf EdgeNode1A und EdgeNode1B ausgeführt. Die Tier-0- und Tier-1-Gateways im Standby werden auf EdgeNode2A und EdgeNode2B ausgeführt.
- Verknüpfen Sie mithilfe der API jeden Edge-Knoten mit der Fehlerdomäne für die Site. Rufen Sie zuerst die
GET /api/v1/transport-nodes/<transport-node-id>-API auf, um die Daten über den Edge-Knoten abzurufen. Verwenden Sie das Ergebnis der GET-API als Eingabe für diePUT /api/v1/transport-nodes/<transport-node-id>-API, wobei die zusätzliche Eigenschaft failure_domain_id entsprechend festgelegt ist. Beispiel:GET /api/v1/transport-nodes/<transport-node-id> Response: { "resource_type": "TransportNode", "_revision": 15" "description": "Updated NSX configured Test Transport Node", "id": "77816de2-39c3-436c-b891-54d31f580961", ... } PUT /api/v1/transport-nodes/<transport-node-id> { "resource_type": "TransportNode", "_revision": 15" "description": "Updated NSX configured Test Transport Node", "id": "77816de2-39c3-436c-b891-54d31f580961", ... "failure_domain_id": "<UUID>", } - Konfigurieren Sie mithilfe der API den Edge-Cluster, um Knoten basierend auf der Fehlerdomäne zuzuteilen. Rufen Sie zuerst die
GET /api/v1/edge-clusters/<edge-cluster-id>-API auf, um die Daten über den Edge-Cluster abzurufen. Verwenden Sie das Ergebnis der GET-API als Eingabe für diePUT /api/v1/edge-clusters/<edge-cluster-id>-API, wobei die zusätzliche Eigenschaft allocation_rules entsprechend festgelegt ist. Beispiel:GET /api/v1/edge-clusters/<edge-cluster-id> Response: { "_revision": 0, "id": "bf8d4daf-93f6-4c23-af38-63f6d372e14e", "resource_type": "EdgeCluster", ... } PUT /api/v1/edge-clusters/<edge-cluster-id> { "_revision": 0, "id": "bf8d4daf-93f6-4c23-af38-63f6d372e14e", "resource_type": "EdgeCluster", ... "allocation_rules": [ { "action": { "enabled": true, "action_type": "AllocationBasedOnFailureDomain" } } ], } - Erstellen Sie Tier-0- und Tier-1-Gateways mithilfe der API oder der NSX Manager-Benutzeroberfläche.
Im Falle eines vollständigen Ausfalls der primären Site übernehmen das Tier-0- und Tier-1-Standby auf der sekundären Site automatisch und werden zu den neuen aktiven Gateways.
Die folgenden Diagramme veranschaulichen die automatische Wiederherstellung der Datenebene.
Vor dem Notfall:
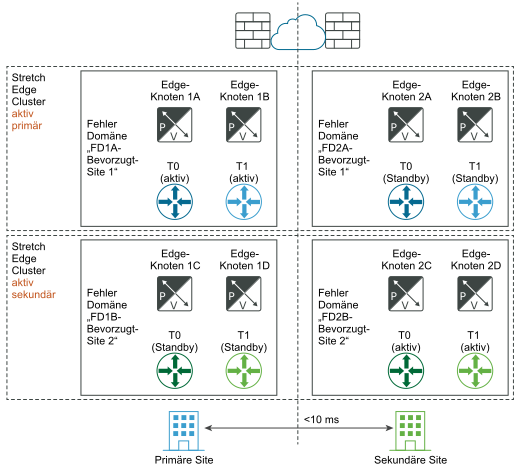
Nach der Notfallwiederherstellung:
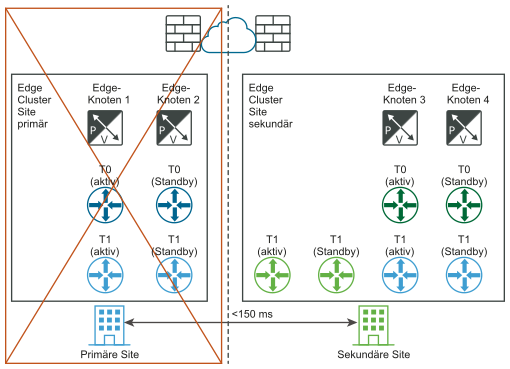
Wichtig: Dasselbe Prinzip gilt, wenn einer der Edge-Knoten auf der primären Site, aber nicht die gesamte Site ausfällt. Beispiel: Im Diagramm „Vor dem Ausfall“ wird davon ausgegangen, dass Edge-Knoten 1B „tier-1“(blau) aktiv hostet und dass Edge-Knoten 2B „tier-1“ (blau) im Standby-Modus hostet. Wenn der Edge-Knoten 1B ausfällt, übernimmt das im Standby-Modus gehostete Gateway „Tier-1“ (blau) auf Edge-Knoten 2B und wird zum neuen aktiven Gateway „Tier-1“ (blau).
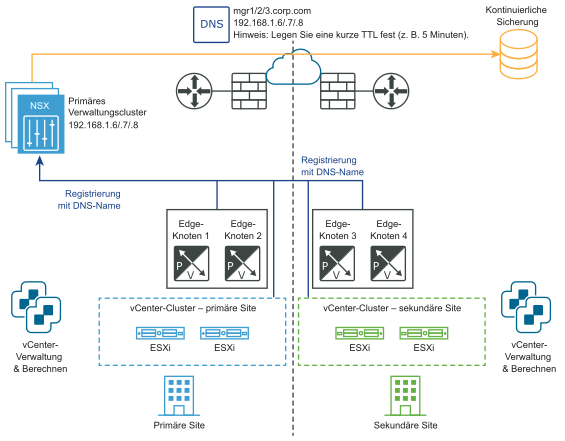
Manuelle/skriptbasierte Wiederherstellung der Management Plane
- DNS für NSX Manager mit einer kurzen TTL (z. B. 5 Minuten).
- Kontinuierliche NSX Manager-Sicherung.
Weder vSphere HA noch ein ausgeweitetes Management-VLAN sind erforderlich. NSX Manager müssen mit einem DNS-Namen mit einer kurzen TTL verknüpft sein. Alle Transportknoten (Edge-Knoten und Hypervisoren) müssen mit ihrem DNS-Namen eine Verbindung mit dem NSX Manager herstellen. Um Zeit zu sparen, können Sie optional einen NSX Manager-Cluster auf der sekundären Site vorab installieren.
- Ändern des DNS-Eintrags, sodass der NSX Manager-Cluster unterschiedliche IP-Adressen hat.
- Wiederherstellen des NSX Manager-Clusters aus einer Sicherung.
- Verbinden der Transportknoten mit dem neuen NSX Manager-Cluster.
Die folgenden Diagramme veranschaulichen die manuelle/skriptbasierte Wiederherstellung der Management Plane.
Vor dem Notfall:
Nach dem Ausfall:
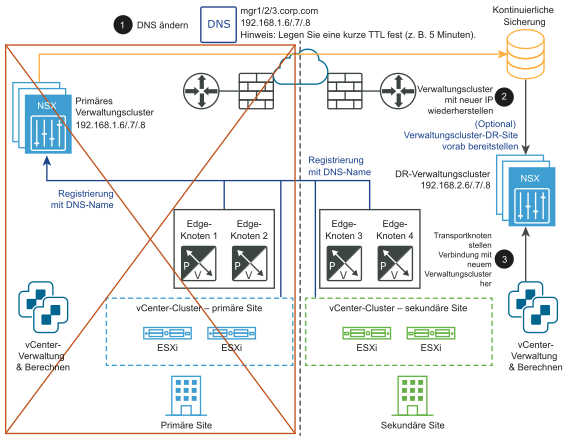
Manuelle/skriptbasierte Wiederherstellung der Data Plane
Anforderung: Die maximale Latenz zwischen Edge-Knoten beträgt 150 ms.
Die Edge-Knoten können VMs oder Bare Metal sein. Die Tier-0-Gateways an jedem Standort können „Aktiv/Standby“ oder „Aktiv/Aktiv“ sein. Edge-Knoten-VMs können auf unterschiedlichen vCenter-Servern installiert werden. vSphere HA ist nicht erforderlich.
- Aktualisieren Sie für alle „tier-1“-Instanzen auf der primären Site (blau) die Edge-Clusterkonfiguration als sekundäre Edge-Cluster-Site.
- Verbinden Sie sie alle „tier-1“-Instanzen auf der primären Site (blau) erneut mit der sekundären Site „T0“ (grün).
Die folgenden Diagramme veranschaulichen die manuelle/skriptbasierte Wiederherstellung der Datenebene sowohl mit der logischen als auch mit der physischen Netzwerkansicht.
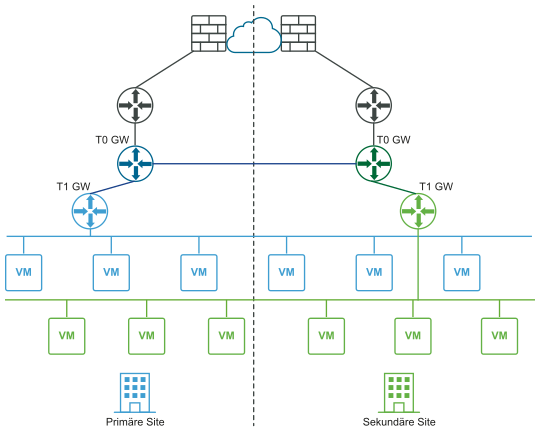
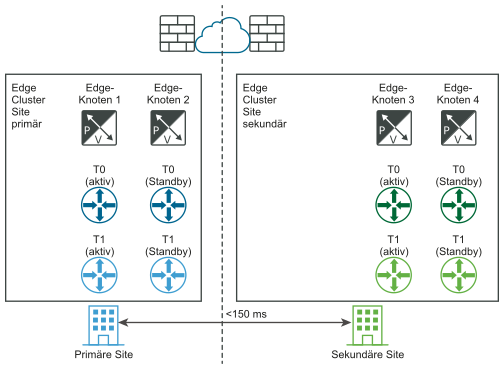
Vor dem Ausfall (logische und physische Ansichten):
Nach dem Ausfall (logische und physische Ansichten):
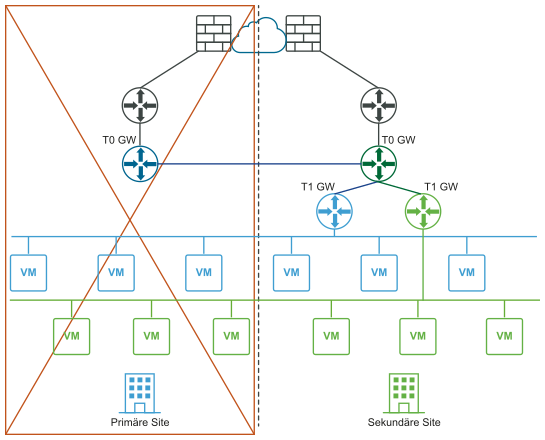
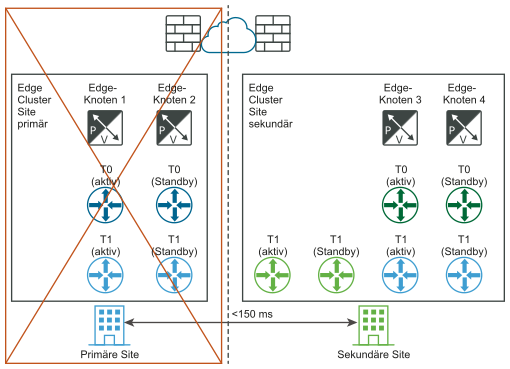
Voraussetzungen für Bereitstellungen für mehrere Sites
- Die Bandbreite muss mindestens 1 GBit/s betragen und die Latenz (RTT) muss kleiner als 150 ms sein.
- Die MTU muss mindestens 1600 betragen. 9000 wird empfohlen.
- Mit automatischer Wiederherstellung der Management Plane mit einer VLAN-Verwaltung, die sich über mehrere Sites erstreckt. vSphere HA über Sites hinweg für NSX Manager-VMs.
- Mit manueller/skriptgestützter Wiederherstellung der Management Plane mit VLAN-Verwaltung, die sich über mehrere Sites erstreckt. VMware SRM für NSX Manager VMs.
- Mit manueller/skriptbasierter Wiederherstellung der Management Plane, ohne dass die VLAN-Verwaltung zwischen den Sites ausgeweitet wird.
- Kontinuierliche NSX Manager-Sicherung.
- NSX Manager muss eingerichtet werden, um FQDN verwenden zu können.
- Derselbe Internetanbieter muss verwendet werden, wenn öffentliche IP-Adressen über Dienste wie NAT oder den Load Balancer verfügbar gemacht werden.
- Mit automatischer Wiederherstellung der Management Plane
- Die maximale Latenz zwischen Standorten beträgt 10 ms.
- Der HA-Modus für das Tier-0-Gateway muss „Aktiv/Standby“ sein und der Failover-Modus muss „Vorbeugend“ sein, um ein asymmetrisches Routing garantiert auszuschließen.
- Der HA-Modus für das Tier-0-Gateway kann „Aktiv/Aktiv“ sein, wenn asymmetrisches Routing akzeptabel ist (z. B. verschiedene Gebäude in einer Metropolregion).
- Bei manueller/skriptbasierter Wiederherstellung der Management Plane
- Die maximale Latenz zwischen Standorten beträgt 150 ms.
- Das CMS muss ein NSX-Plug-In unterstützen. In dieser Version erfüllen VMware Integrated OpenStack (VIO) und vRealize Automation (vRA) diese Anforderung.
Einschränkungen
- Keine lokalen Egress-Funktionen. Der gesamte Nord-Süd-Datenverkehr muss innerhalb derselben Site stattfinden.
- Die Software für die Notfallwiederherstellungsberechnung muss NSX unterstützen, z. B. VMware SRM 8.1.2 oder höher.
- Führen Sie beim Wiederherstellen des NSX Managers in einer Umgebung mit mehreren Sites auf der sekundären/primären Site die folgenden Schritte aus:
- Nachdem der Wiederherstellungsvorgang im Schritt AddNodeToCluster angehalten wurde, müssen Sie zuerst die vorhandene VIP entfernen und die neue virtuelle IP auf der Seite -Benutzeroberfläche festlegen, bevor Sie zusätzliche Managerknoten hinzufügen.
- Fügen Sie einem wiederhergestellten Cluster mit einem Knoten neue Knoten hinzu, nachdem die VIP aktualisiert wurde.
