









Die Disaster Recovery (DR)-Funktion von SASE Orchestrator verhindert den Verlust gespeicherter Daten und nimmt die SASE Orchestrator-Dienste im Falle eines System- oder Netzwerkausfalls wieder auf.
- Die Wiederherstellungszeit (Recovery Time Objective, RTO) richtet sich daher nach der expliziten Operator-Aktion, eine Heraufstufung der Standby-Instanz auszulösen.
- Das Recovery Point Objective (RPO) ist jedoch unabhängig von der Wiederherstellungszeit im Prinzip null, da die gesamte Konfiguration sofort repliziert wird. Überwachungsdaten, die während des Ausfalls gesammelt wurden, werden auf den Edges und Gateways zwischengespeichert, bis die Standby-Instanz hochgestuft wird.
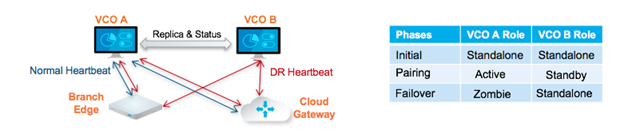
Aktiv/Standby-Paar
In einer SASE Orchestrator-DR-Bereitstellung werden zwei identische SASE Orchestrator-Systeme als ein Aktiv/Standby-Paar konfiguriert. Der Operator kann den Zustand der DR-Bereitschaft über die Web-Benutzeroberfläche auf einem der Server anzeigen. Edges und Gateways erkennen beide SASE Orchestrator-Instanzen, während sie jedoch nur von der aktiven SASE Orchestrator-Instanz Konfigurationsänderungen erhalten, senden sie regelmäßig DR-Taktsignale an beide Systeme, um ihre Ansicht beider Server zu melden und den DR-Systemstatus abzufragen. Wenn der Operator ein Failover auslöst, werden die Edges und Gateways über die Änderung ihres nächsten DR-Taktsignals informiert.
DR-Zustände
In der Ansicht eines Operators und der Edges und Gateways verfügt eine SASE Orchestrator-Instanz über einen der folgenden vier DR-Zustände:
| DR-Zustand | Beschreibung |
|---|---|
| Eigenständig (Standalone) | Kein DR konfiguriert. |
| Aktiv (Active) | DR wurde konfiguriert und fungiert als primärer SASE Orchestrator-Server. |
| Standby | DR wurde konfiguriert und fungiert als inaktiver SASE Orchestrator-Replikatserver. |
| Zombie | DR war früher konfiguriert und aktiv, fungiert aber nicht mehr als aktive oder Standby-Instanz. |
Laufzeitvorgang (Run-time Operation)
Wenn DR konfiguriert ist, wird der Standby-Server in einem eingeschränkten Modus ausgeführt und blockiert alle API-Aufrufe mit Ausnahme derer, die sich auf den DR-Zustand und die DR-Taktsignale beziehen. Wenn der Operator ein Failover aufruft, wird die Standby-Instanz heraufgestuft, um als eigenständiger Server vollständig funktionsfähig zu werden. Der zuvor aktive Server geht automatisch in den Zombie-Zustand über, wenn er reagiert und auf der heraufgestuften Standby-Instanz sichtbar ist. Im Zombie-Zustand werden die Verwaltungskonfigurationsdienste blockiert, und alle Kontakte von Edges und Gateways, die nicht auf die neue aktive SASE Orchestrator-Instanz weitergeleitet wurden, werden an den heraufgestuften Server umgeleitet.
Einrichten von SASE Orchestrator-Replizierung
Zwei installierte SASE Orchestrator-Instanzen sind erforderlich, um die Replizierung zu initiieren.
- Die ausgewählte Standby-Instanz wird in einen
STANDBY_CANDIDATE-Zustand versetzt, sodass sie vom aktiven Server konfiguriert werden kann. - Der aktive Server erhält anschließend die Adresse und die Anmeldedaten der Standby-Instanz und wechselt in den
ACTIVE_CONFIGURING-Zustand.
STANDBY_CONFIG_RQST-Anforderung von „Aktiv“ in „Standby“ vorgenommen wird, werden die beiden Server durch die Zustandsübergänge synchronisiert.
- Die Gateway-Zeitzone muss auf Etc/UTC festgelegt werden. Verwenden Sie den folgenden Befehl, um die NTP-Zeitzone anzuzeigen.
vcadmin@vcg1-example:~$ cat /etc/timezone Etc/UTC vcadmin@vcg1-example:~$
Wenn die Zeitzone nicht korrekt ist, verwenden Sie die folgenden Befehle, um die Zeitzone zu aktualisieren.
echo "Etc/UTC" | sudo tee /etc/timezone sudo dpkg-reconfigure --frontend noninteractive tzdata
- Der NTP-Versatz muss kleiner oder gleich 15 Millisekunden sein. Verwenden Sie den folgenden Befehl, um den NTP-Versatz anzuzeigen.
sudo ntpqvcadmin@vcg1-example:~$ sudo ntpq -p remote refid st t when poll reach delay offset jitter ============================================================================== *ntp1-us1.prod.v 74.120.81.219 3 u 474 1024 377 10.171 -1.183 1.033 ntp1-eu1-old.pr .INIT. 16 u - 1024 0 0.000 0.000 0.000 vcadmin@vcg1-example:~$Wenn der Zeitversatz nicht korrekt ist, verwenden Sie die folgenden Befehle, um den NTP-Zeitversatz zu aktualisieren.
sudo systemctl stop ntp sudo ntpdate <server> sudo systemctl start ntp
- Standardmäßig wird eine Liste der NTP-Server in der Datei „
/etc/ntpd.conf“ konfiguriert. Die Orchestrator-Instanzen, auf denen DR eingerichtet werden muss, müssen über eine Internetverbindung verfügen, um auf die Standard-NTP-Server zuzugreifen und sicherzustellen, dass die Uhrzeit auf beiden Orchestrator-Instanzen synchron ist. Kunden können auch ihren lokalen NTP-Server verwenden, der in ihrer Umgebung ausgeführt wird, um die Uhrzeit zu synchronisieren.
Einrichten des Standby-Orchestrators
Führen Sie die folgenden Schritte aus, um die Standby-Orchestrator-Instanz einzurichten:
- Klicken Sie im SD-WAN-Dienst des Unternehmensportals auf die Registerkarte Orchestrator und klicken Sie dann im linken Fensterbereich auf die Schaltfläche Replizierung (Replication), um den Bildschirm Orchestrator-Replizierung (Orchestrator Replication) anzuzeigen.
- Aktivieren Sie den Standby-Orchestrator, indem Sie die Optionsschaltfläche Standby (Replizierungsrolle (Replication Role)) auswählen.
- Klicken Sie auf die Schaltfläche Für Standby aktivieren (Enable for Standby).
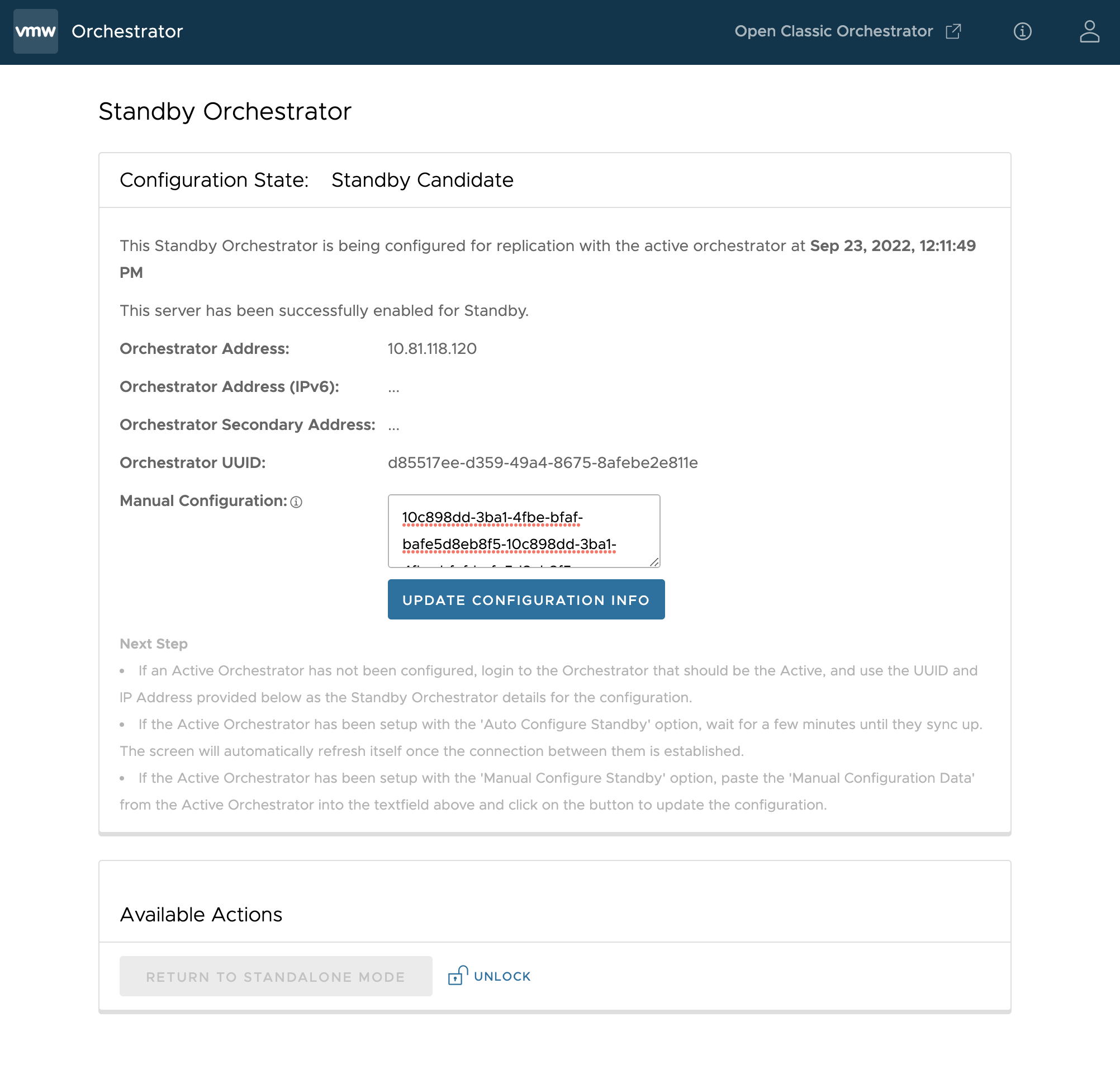
Die Seite „Standby-Orchestrator (Standby Orchestrator)“ wird angezeigt.
- Geben Sie die Parameter manuelle Konfiguration (manual configuration) ein und klicken Sie auf die Schaltfläche Konfigurationsinformationen aktualisieren (Update configuration info).
Nachdem der Standby-Orchestrator für die Replizierung konfiguriert wurde, konfigurieren Sie die aktive Orchestrator-Instanz gemäß den folgenden Anweisungen.
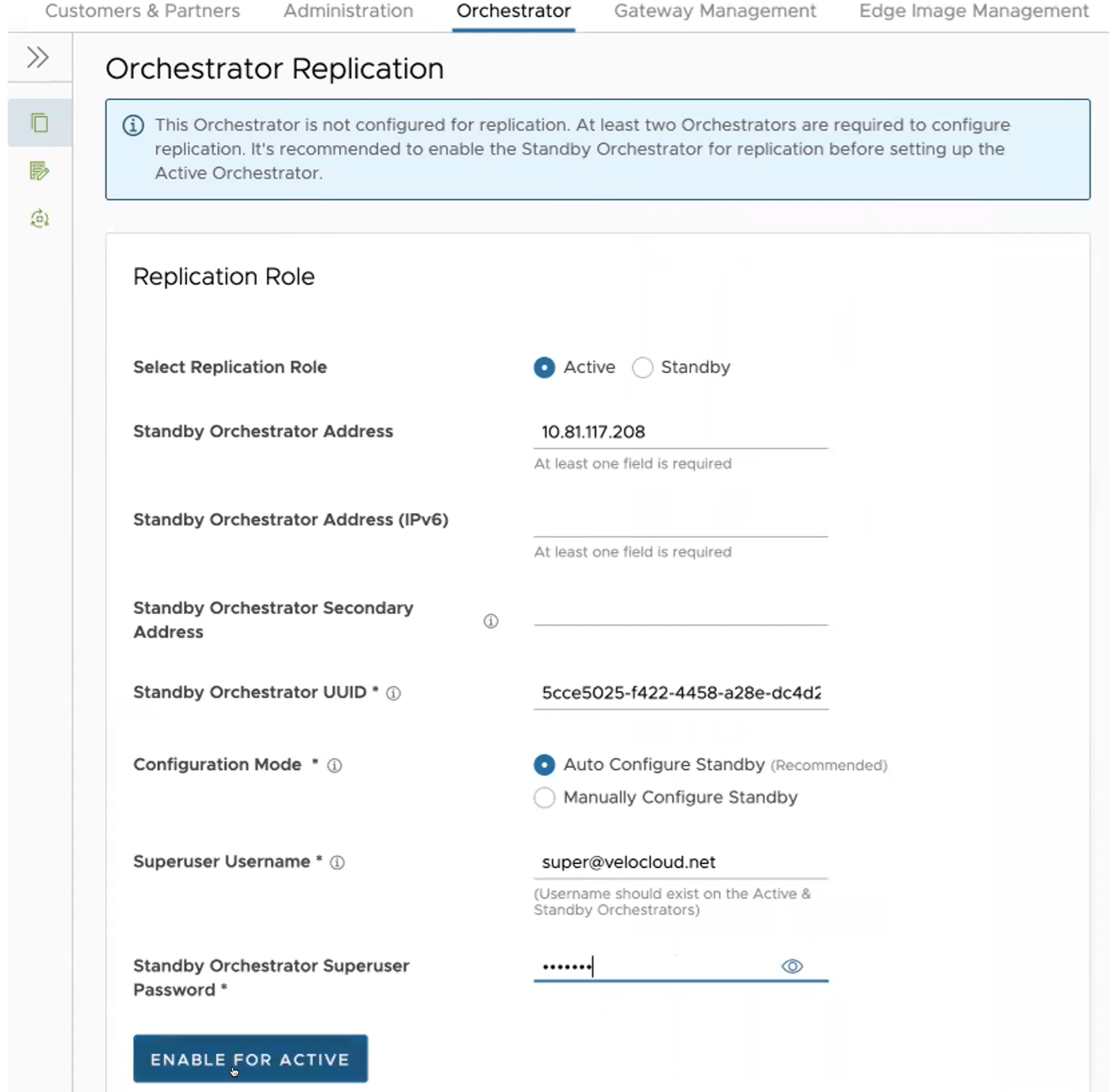
Einrichten des aktiven Orchestrators
Um den aktiven Orchestrator einzurichten, wählen Sie die Replizierungsrolle als „Aktiv (Active)“ aus und konfigurieren Sie Folgendes
| Option | Beschreibung |
|---|---|
| Replizierungsrolle auswählen (Select Replication Role) | Wählen Sie das Optionsfeld Aktiv (Active) für die Replizierungsrolle aus. |
| Adresse der Standby-Orchestrator-Instanz (Standby Orchestrator Address) | Geben Sie die IP-Adresse des primären Standby-Orchestrators ein. |
| Adresse der Standby-Orchestrator-Instanz (IPv6) (Standby Orchestrator Address (IPv6)) | Geben Sie die IPv6-Adresse des Standby-Orchestrators ein. |
| Sekundäre Adresse der Standby-Orchestrator-Instanz (Standby Orchestrator Secondary Address) | Geben Sie die Adresse der sekundären Schnittstelle des Standby-Orchestrators ein. Diese Adresse wird für die Replizierung verwendet, wenn die Standby-Instanz auf „Aktiv (Active)“ heraufgestuft wird. Benutzer können hier IPv4-, IPv6- oder FQDN-Adressen hinzufügen. |
| Standby-Orchestrator-UUID (Standby Orchestrator UUID) | Geben Sie die UUID des Standby-Orchestrators ein. |
| Konfigurationsmodus (Configuration Mode) | Wählen Sie je nach Anforderung das Optionsfeld Standby automatisch konfigurieren (Auto Configure Standby) oder Standby manuell konfigurieren (Manually Configure Standby) aus. Fügen Sie bei manueller Konfiguration einen Zeichenfolgenwert von ACTIVE VCO bis STANDBY_WAIT ein . |
| Superuser-Benutzername (Superuser Username) | Geben Sie den Anzeigenamen für den Orchestrator-Superuser ein. |
| Standby-Orchestrator-Kennwort für Superuser (Standby Orchestrator Superuser Password) | Geben Sie das Kennwort für den Orchestrator-Superuser ein. |
- Klicken Sie auf die Schaltfläche Als aktive Instanz aktivieren (Enable for Active), um die Replizierungsrolle zu aktivieren.
Nach Abschluss der Konfiguration sind beide Orchestrator (Standby- und aktiver Orchestrator) synchronisiert.
Synchronisierter Standby-Orchestrator
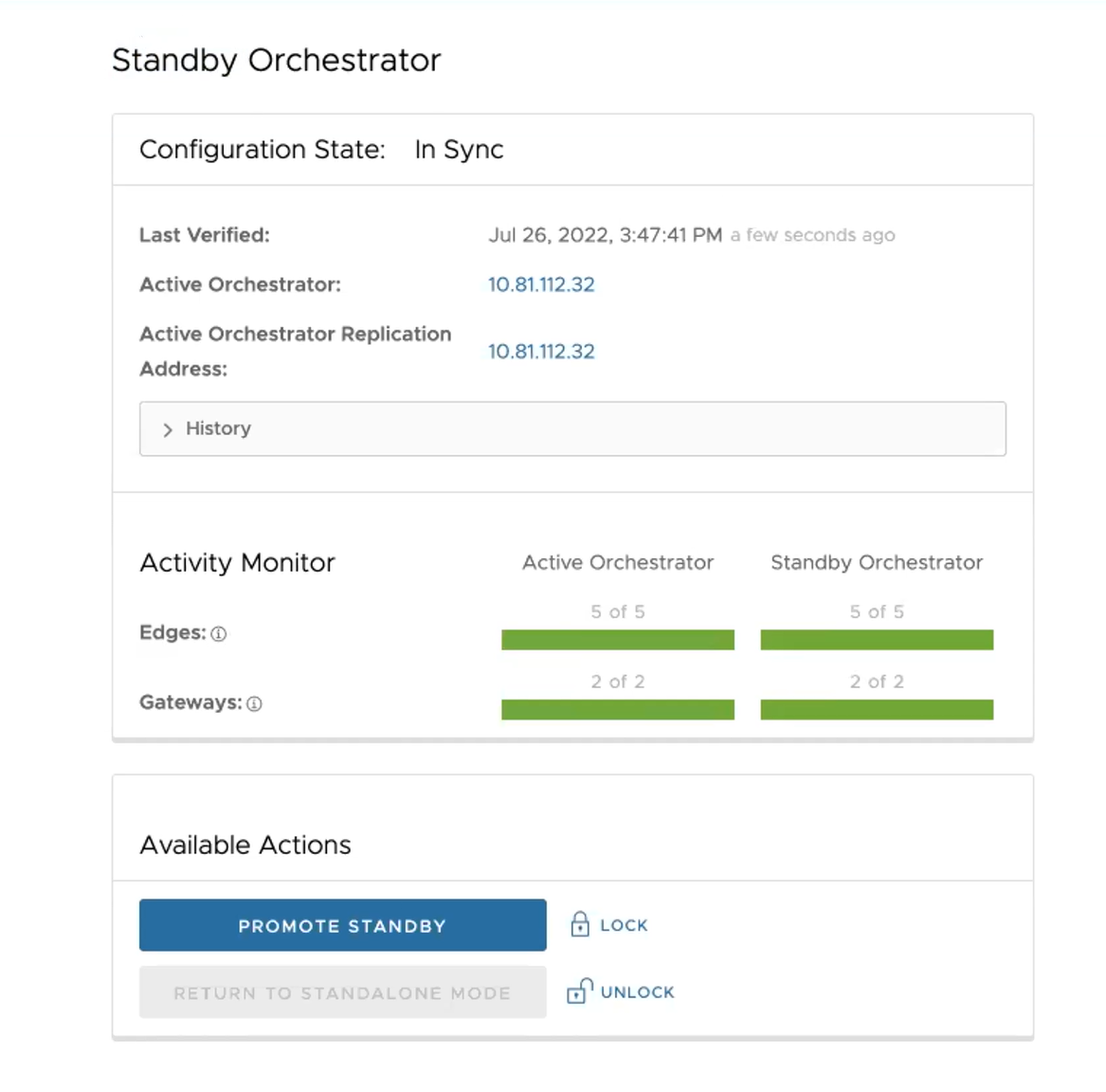
Synchronisierter aktiver Orchestrator
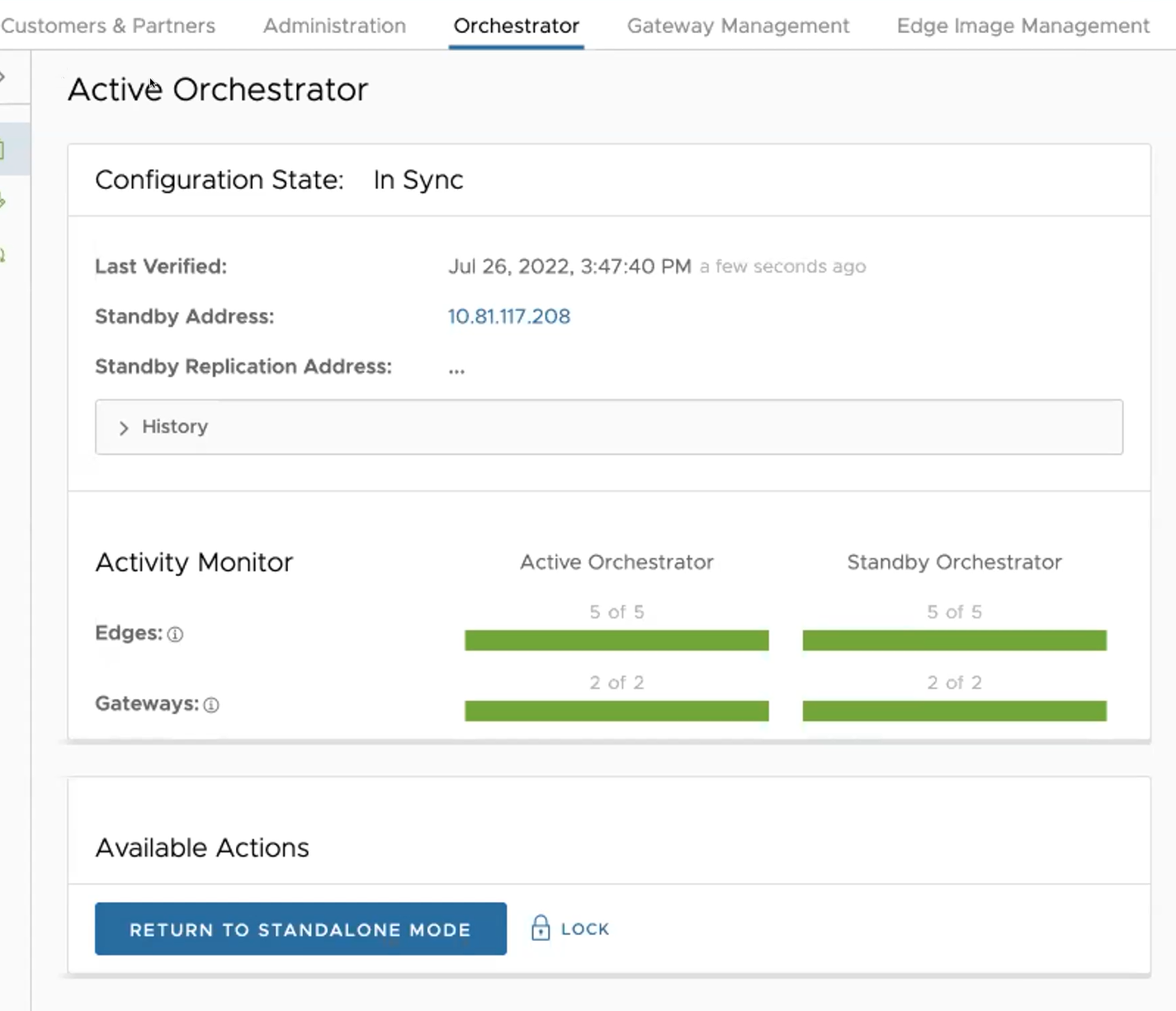
Failover-Test
Die folgenden Failover-Testszenarien sind erzwungene Failovers für beispielhafte Zwecke. Sie können diese Aktionen im Bereich Verfügbare Aktionen (Available Actions) der Bildschirme Active (Aktiv) und Standby ausführen.
Hochstufen einer Standby-Orchestrator-Instanz
In diesem Abschnitt wird beschrieben, wie Sie eine Standby-Orchestrator-Instanz hochstufen.
So stufen Sie eine Standby-Orchestrator-Instanz hoch:
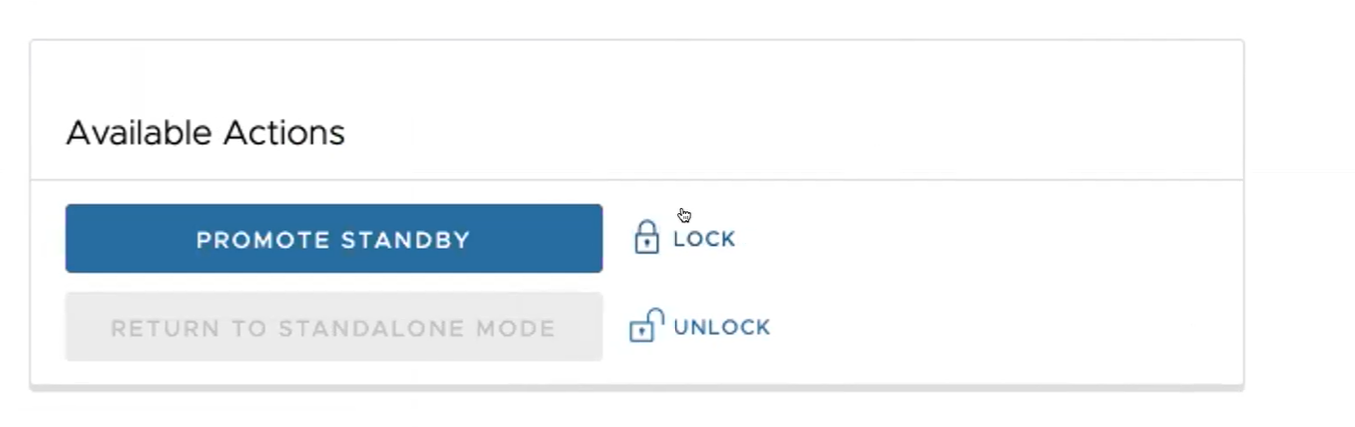
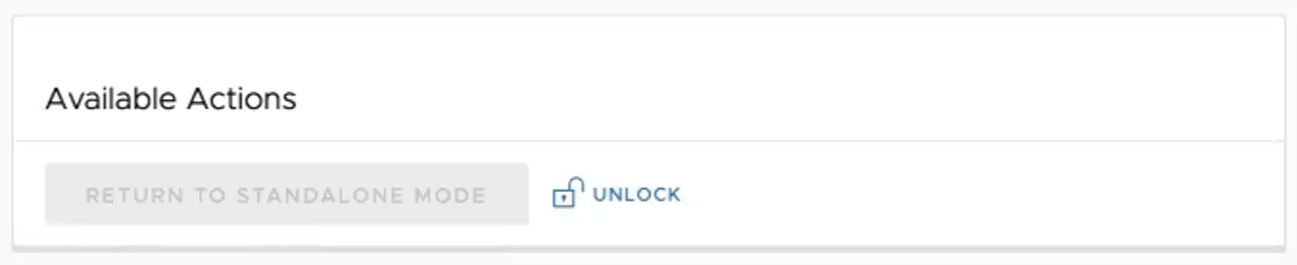
- Klicken Sie auf den Link entsperren (unlock).
- Klicken Sie im Standby-Orchestrator-Bildschirm im Bereich Verfügbare Aktionen (Available Actions) auf die Schaltfläche Standby hochstufen (Promote Standby).
Im folgenden Dialogfeld werden Sie darauf hingewiesen, dass Administratoren SASE Orchestrator nicht mehr mit der vorherigen aktiven Orchestrator-Version verwalten können, wenn Sie Ihre Standby-Orchestrator-Instanz hochstufen.
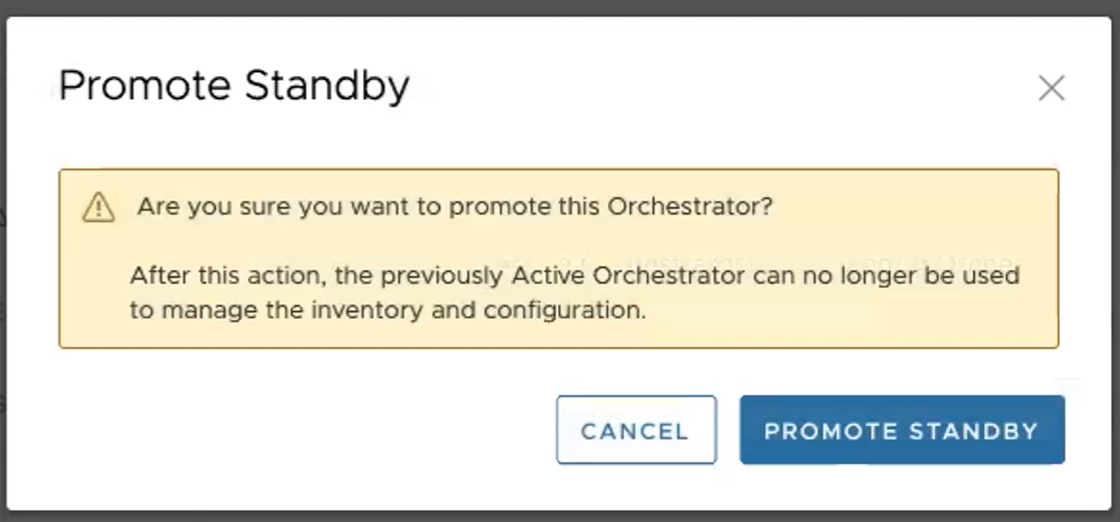
- Klicken Sie auf die Schaltfläche Standby hochstufen (Promote Standby), um die Standby-Orchestrator-Instanz hochzustufen.
- Klicken Sie auf Heraufstufung der Standby-Instanz erzwingen (Force Promote Standby), um den Orchestrator hochzustufen.
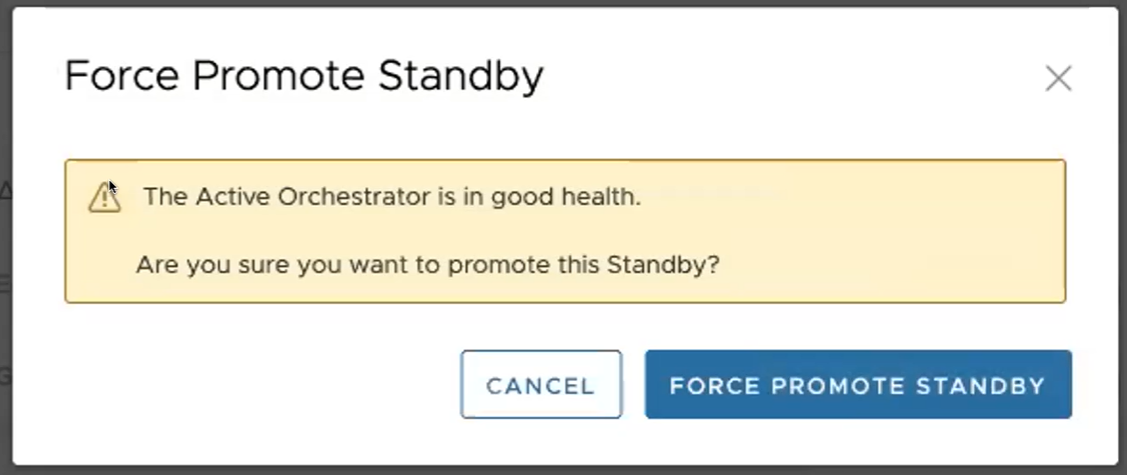
In einem abschließend angezeigten Dialogfeld wird angegeben, dass es sich bei Orchestrator nicht mehr um eine Standby-Version handelt. Orchestrator wird nun im eigenständigen Modus neu gestartet.

Wenn Sie eine Standby-Orchestrator-Instanz hochstufen, wird sie im eigenständigen Modus neu gestartet.
Wenn die Standby-Instanz mit der ehemals aktiven Orchestrator-Instanz kommunizieren kann, versetzt sie Orchestrator in einen Zombie-Zustand. Im Zombie-Zustand teilt die Orchestrator-Instanz ihren Clients (Edges, Gateways, UI/API) mit, dass sie nicht mehr aktiv ist und dass sie mit der neu hochgestuften Orchestrator-Instanz kommunizieren müssen. Wenn die heraufgestufte Standby-Instanz nicht mit der ehemals aktiven Orchestrator-Instanz kommunizieren kann, sollte der Operator, falls möglich, die ehemals aktive Orchestrator-Instanz manuell herabstufen.
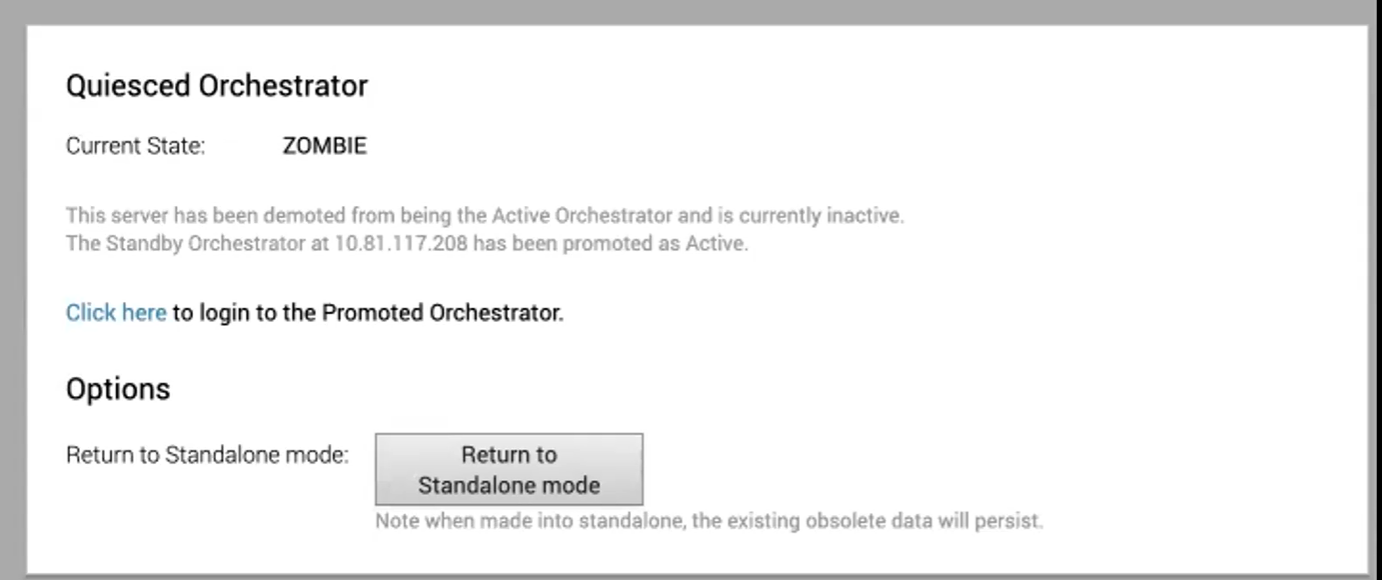
Zurückkehren zum eigenständigen Modus
Um den Zombie wieder in den eigenständigen Modus zu versetzen, klicken Sie im Bildschirm Aktiver Orchestrator (Active Orchestrator) oder Standby-Orchestrator (Standby Orchestrator) im Bereich „Verfügbare Aktionen (Available Actions)“ auf die Schaltfläche Zurückkehren zum eigenständigen Modus (Return to Standalone Mode).
Orchestrator kann nach der in der Systemeigenschaft „vco.disasterRecovery.zombie.expirySeconds“ angegebenen Zeit (Standardeinstellung: 1800 Sekunden) vom Zombie-Status wieder in den eigenständigen Modus versetzt werden.
Fehlerbehebung bei SASE Orchestrator-DR
In diesem Abschnitt werden die Fehlerzustände des Systems beschrieben. Diese werden auch auf der Benutzeroberfläche zusammen mit einer ausführlicheren Beschreibung des jeweiligen Fehlers aufgelistet. Zusätzliche Informationen sind im VMware-Protokoll verfügbar.
Behebbare Fehler
Bei den folgenden Fehlern handelt es sich um behebbare Fehler, die eintreten können, wenn SASE Orchestrator-DR den Zustand der Synchronisierung erreicht. Wenn das Problem, das diese Fehler verursacht, behoben wird, kehrt SASE Orchestrator-DR automatisch zum normalen Betrieb zurück.
FAILURE_SYNCING_FILESFAILURE_GET_STANDBY_STATUSFAILURE_MYSQL_ACTIVE_STATUSFAILURE_MYSQL_STANDBY_STATUS
Nicht behebbare Fehler
Die folgenden Fehler können bei der Konfiguration der SASE Orchestrator-DR entstehen. SASE Orchestrator-DR wird nach diesen Fehlern nicht automatisch wiederhergestellt.
FAILURE_ACTIVE_CONFIGURINGFAILURE_LAUNCHING_STANDBYFAILURE_STANDBY_CONFIGURINGFAILURE_COPYING_DBFAILURE_COPYING_FILESFAILURE_SYNC_CONFIGURINGFAILURE_GET_STANDBY_CONFIGFAILURE_STANDBY_CANDIDATEFAILURE_STANDBY_UNCONFIGFAILURE_STANDBY_PROMOTIONFAILURE_ACTIVE_DEMOTION
