









Bereitstellen eines Arbeitslastclusters für spezialisierte Hardware
Tanzu Kubernetes Grid unterstützt die Bereitstellung von Arbeitslastclustern auf bestimmten Typen von GPU-fähigen Hosts auf vSphere 7.0 und höher.
Bereitstellen eines GPU-fähigen Arbeitslastclusters
Um einen Knoten mit einer GPU in einem vSphere-Arbeitslastcluster zu verwenden, müssen Sie den PCI-Passthrough-Modus aktivieren. Der Vorgang ermöglicht den direkten Zugriff auf die GPU durch den Cluster unter Umgehung des ESXi-Hypervisors, wodurch ein Leistungsniveau erreicht wird, das der Leistung der GPU auf einem nativen System ähnelt. Bei Verwendung des PCI-Passthrough-Modus ist jedes GPU-Gerät einer virtuellen Maschine (VM) des vSphere-Arbeitslastclusters zugeordnet.
HinweisUm GPU-fähige Knoten zu vorhandenen Clustern hinzuzufügen, verwenden Sie den Befehl
tanzu cluster node-pool set.
Voraussetzungen
- ESXi-Host mit einer NVIDIA V100- oder NVIDIA Tesla T4-GPU-Karte.
- vSphere 7.0 Update 3 und höher. Im Folgenden sind die Builds für 7.0u3 aufgeführt. Dies ist das Minimum, das für die Unterstützung dieser Version erforderlich ist.
- Tanzu Kubernetes Grid v1.6+.
- Helm, der Kubernetes-Paketmanager. Informationen zur Installation finden Sie unter Installieren von Helm in der Helm-Dokumentation.
Vorgehensweise
Um einen Arbeitslastcluster mit GPU-fähigen Hosts zu erstellen, führen Sie die folgenden Schritte aus, um PCI-Passthrough zu aktivieren, ein benutzerdefiniertes Systemimage zu erstellen, eine Clusterkonfigurationsdatei und Tanzu Kubernetes-Version zu erstellen, den Arbeitslastcluster bereitzustellen und einen GPU-Operator mithilfe von Helm zu installieren.
-
Fügen Sie die ESXi-Hosts mit den GPU-Karten zu Ihrem vSphere Client hinzu.
-
Aktivieren Sie PCI-Passthrough und notieren Sie die GPU-IDs wie folgt:
- Wählen Sie in Ihrem vSphere Client den zielseitigen ESXi-Host im
GPU-Cluster aus. - Wählen Sie Konfigurieren > Hardware > PCI-Geräte aus.
- Wählen Sie die Registerkarte Alle PCI-Geräte aus.
- Wählen Sie die gewünschte GPU in der Liste aus.
- Klicken Sie auf Passthrough umschalten.
- Notieren Sie sich unter "Allgemeine Informationen" die Geräte- und Anbieter-ID (in der Abbildung unten grün hervorgehoben). Die IDs sind für identische GPU-Karten identisch. Sie benötigen diese für die Clusterkonfigurationsdatei.
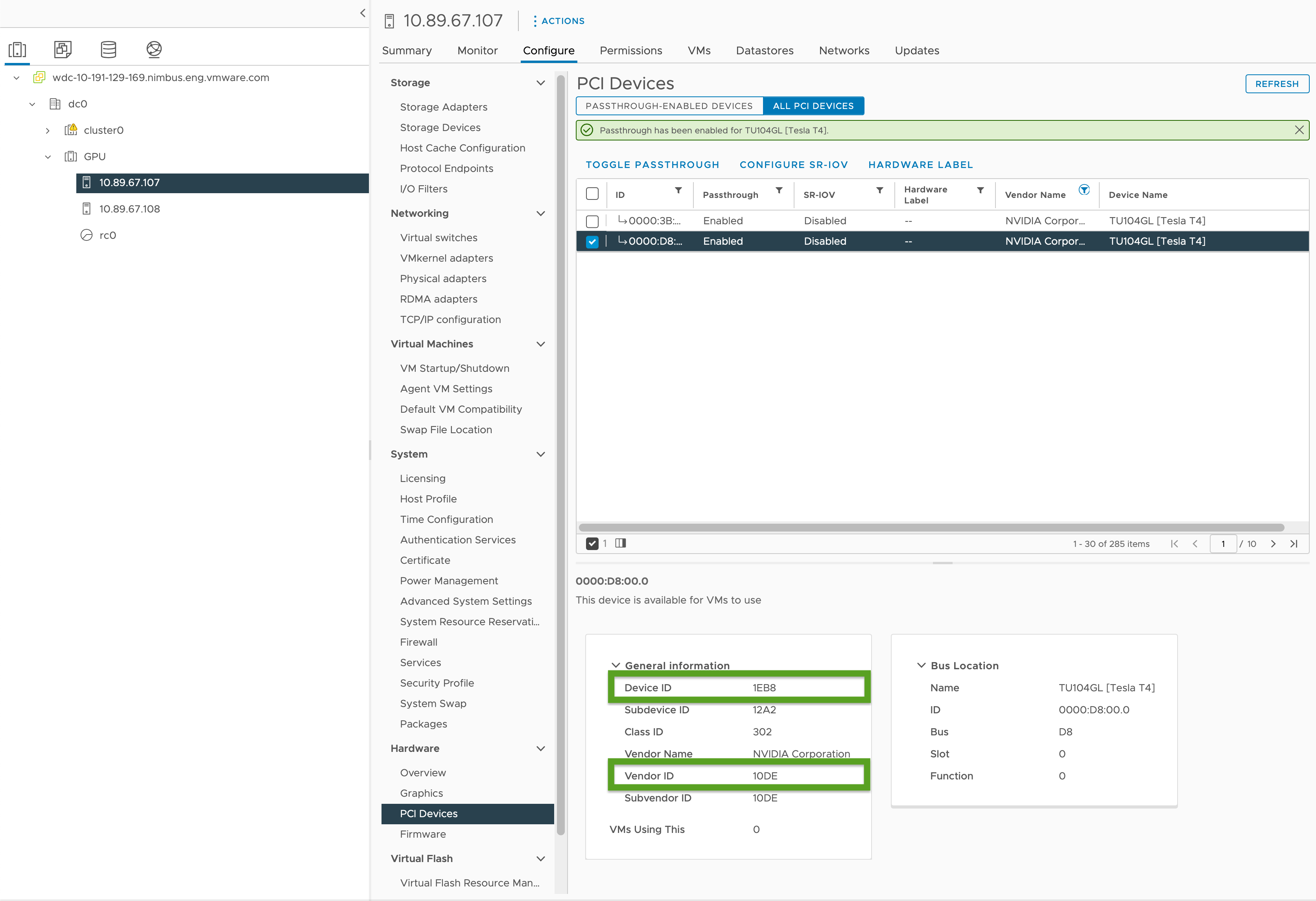
- Wählen Sie in Ihrem vSphere Client den zielseitigen ESXi-Host im
-
Erstellen Sie mithilfe der Vorlage in Workload-Clustervorlage eine Konfigurationsdatei für den Arbeitslastcluster und schließen Sie die folgenden Variablen ein:
... VSPHERE_WORKER_PCI_DEVICES: "0x<VENDOR-ID>:0x<DEVICE-ID>" VSPHERE_WORKER_CUSTOM_VMX_KEYS: 'pciPassthru.allowP2P=true,pciPassthru.RelaxACSforP2P=true,pciPassthru.use64bitMMIO=true,pciPassthru.64bitMMIOSizeGB=<GPU-SIZE>' VSPHERE_IGNORE_PCI_DEVICES_ALLOW_LIST: "<BOOLEAN>" VSPHERE_WORKER_HARDWARE_VERSION: vmx-17 WORKER_ROLLOUT_STRATEGY: "RollingUpdate"Dabei gilt:
<VENDOR-ID>und<DEVICE-ID>ist die Anbieter- und Geräte-ID, die Sie in einem vorherigen Schritt festgehalten haben. Wenn beispielsweise die Anbieter-ID10DEund die Geräte-ID1EB8lautet, lautet der Wert"0x10DE:0x1EB8".<GPU-SIZE>ist die Gesamtmenge der GB des Framebuffer-Arbeitsspeichers aller GPUs im Cluster, die auf die nächste Zweierpotenz aufgerundet wird.- Bei zwei 40 GB-GPUs ist die Gesamtmenge beispielsweise 80 GB, was auf 128 GB aufgerundet wird. Legen Sie den Wert auf
pciPassthru.64bitMMIOSizeGB=128fest. - Informationen zum Ermitteln des erforderlichen Arbeitsspeichers für die GPU-Karte finden Sie in der Dokumentation für Ihre spezifische NVIDIA GPU-Karte. Weitere Informationen finden Sie in der Tabelle Anforderungen für die Verwendung von vGPU auf GPUs, die 64 GB oder mehr MMIO-Speicherplatz mit VMs mit großem Arbeitsspeicher erfordern in der NVIDIA-Dokumentation.
- Siehe auch:
- Bei zwei 40 GB-GPUs ist die Gesamtmenge beispielsweise 80 GB, was auf 128 GB aufgerundet wird. Legen Sie den Wert auf
<BOOLEAN>istfalse, wenn Sie die NVIDIA Tesla T4 GPU verwenden, undtrue, wenn Sie die NVIDIA V100 GPU verwenden.<VSPHERE_WORKER_HARDWARE_VERSION>ist die Hardwareversion der virtuellen Maschine, auf die ein Upgrade der VM durchgeführt werden soll. Die für GPU-Knoten erforderliche Mindestversion sollte 17 sein.WORKER_ROLLOUT_STRATEGYistRollingUpdate, wenn Sie zusätzliche PCI-Geräte haben, die von den Worker-Knoten während Upgrades verwendet werden können. Andernfalls verwenden SieOnDelete.
Hinweis
Sie können nur einen GPU-Typ pro VM verwenden. Sie können beispielsweise nicht sowohl NVIDIA V100 als auch NVIDIA Tesla T4 auf einer einzelnen VM verwenden, aber Sie können mehrere GPU-Instanzen mit derselben Anbieter- und Geräte-ID verwenden.
Die
tanzu-CLI lässt das Aktualisieren derWORKER_ROLLOUT_STRATEGY-Spezifikation auf demMachineDeploymentnicht zu. Wenn das Cluster-Upgrade aufgrund nicht verfügbarer PCI-Geräte hängen bleibt, schlägt VMware vor, dieMachineDeployment-Strategie mithilfe derkubectl-CLI zu bearbeiten. Die Rollout-Strategie wird unterspec.strategy.typedefiniert.Eine vollständige Liste der Variablen, die Sie für GPU-fähige Cluster konfigurieren können, finden Sie unter GPU-fähige Cluster in Referenz für die Variablen der Konfigurationsdatei.
-
Erstellen Sie den Arbeitslastcluster, indem Sie Folgendes ausführen:
tanzu cluster create -f CLUSTER-CONFIG-NAMEDabei ist
CLUSTER-CONFIG-NAMEder Name der Clusterkonfigurationsdatei, die Sie in den vorherigen Schritten erstellt haben. -
Fügen Sie das NVIDIA Helm-Repository hinzu:
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia \ && helm repo update -
Installieren Sie den NVIDIA GPU-Operator:
helm install --kubeconfig=./KUBECONFIG --wait --generate-name -n gpu-operator --create-namespace nvidia/gpu-operatorDabei ist
KUBECONFIGder Name und der Speicherort derkubeconfigfür Ihren Arbeitslastcluster. Weitere Informationen finden Sie unter Abrufen vonkubeconfigfür Arbeitslastcluster.Informationen zu den Parametern in diesem Befehl finden Sie unter Installieren des GPU-Operators in der NVIDIA-Dokumentation.
-
Stellen Sie sicher, dass der NVIDIA GPU-Operator ausgeführt wird:
kubectl --kubeconfig=./KUBECONFIG get pods -ADie Ausgabe entspricht:
NAMESPACE NAME READY STATUS RESTARTS AGE gpu-operator gpu-feature-discovery-szzkr 1/1 Running 0 6m18s gpu-operator gpu-operator-1676396573-node-feature-discovery-master-7795vgdnd 1/1 Running 0 7m7s gpu-operator gpu-operator-1676396573-node-feature-discovery-worker-bq6ct 1/1 Running 0 7m7s gpu-operator gpu-operator-84dfbbfd8-jd98f 1/1 Running 0 7m7s gpu-operator nvidia-container-toolkit-daemonset-6zncv 1/1 Running 0 6m18s gpu-operator nvidia-cuda-validator-2rz4m 0/1 Completed 0 98s gpu-operator nvidia-dcgm-exporter-vgw7p 1/1 Running 0 6m18s gpu-operator nvidia-device-plugin-daemonset-mln6z 1/1 Running 0 6m18s gpu-operator nvidia-device-plugin-validator-sczdk 0/1 Completed 0 22s gpu-operator nvidia-driver-daemonset-b7flb 1/1 Running 0 6m38s gpu-operator nvidia-operator-validator-2v8zk 1/1 Running 0 6m18s
Testen Ihres GPU-Clusters
Um Ihren GPU-fähigen Cluster zu testen, erstellen Sie ein Pod-Manifest für das Beispiel cuda-vector-add aus der Kubernetes-Dokumentation und stellen Sie es bereit. Der Container lädt eine CUDA-Berechnung mit der GPU herunter und führt diese aus.
-
Erstellen Sie eine Datei mit dem Namen
cuda-vector-add.yamlund fügen Sie Folgendes hinzu:apiVersion: v1 kind: Pod metadata: name: cuda-vector-add spec: restartPolicy: OnFailure containers: - name: cuda-vector-add # https://github.com/kubernetes/kubernetes/blob/v1.7.11/test/images/nvidia-cuda/Dockerfile image: "registry.k8s.io/cuda-vector-add:v0.1" resources: limits: nvidia.com/gpu: 1 # requesting 1 GPU -
Wenden Sie die Datei an:
kubectl apply -f cuda-vector-add.yaml -
Führen Sie sie aus:
kubectl get po cuda-vector-addDie Ausgabe entspricht:
cuda-vector-add 0/1 Completed 0 91s -
Führen Sie sie aus:
kubectl logs cuda-vector-addDie Ausgabe entspricht:
[Vector addition of 50000 elements] Copy input data from the host memory to the CUDA device CUDA kernel launch with 196 blocks of 256 threads Copy output data from the CUDA device to the host memory Test PASSED Done
Bereitstellen eines Arbeitslastclusters auf einer Edge-Site
Tanzu Kubernetes Grid v1.6+ unterstützt die Bereitstellung von Arbeitslastclustern auf VMware ESXi-Edge-Hosts. Sie können diesen Ansatz verwenden, wenn Sie viele Kubernetes-Cluster an verschiedenen Speicherorten ausführen möchten, die alle von einem zentralen Verwaltungscluster verwaltet werden.
Topologie: Sie können Edge-Arbeitslastcluster in der Produktion mit einem einzelnen Steuerungsebenenknoten und nur einem oder zwei Hosts ausführen. Obwohl dies weniger CPU, Arbeitsspeicher und Netzwerkbandbreite benötigt, verfügen Sie nicht über dieselben Stabilitäts- und Wiederherstellungseigenschaften wie Standardproduktions-Tanzu Kubernetes Grid-Cluster. Weitere Informationen finden Sie unter Referenzarchitektur 1.0 zur VMware Tanzu Edge-Lösung.
Lokale Registrierung: Um Kommunikationsverzögerungen zu minimieren und die Stabilität zu maximieren, sollte jeder Edge-Cluster über eine eigene lokale Harbor-Container-Registrierung verfügen. Eine Übersicht über diese Architektur finden Sie unter Container-Registrierung in Architekturübersicht. Informationen zum Installieren einer lokalen Harbor-Registrierung finden Sie unter Bereitstellen einer Offline-Harbor-Registrierung auf vSphere.
Zeitüberschreitungen: Wenn sich der Verwaltungscluster eines Edge-Arbeitslastclusters ortsfern in einem Hauptdatencenter befindet, müssen Sie möglicherweise bestimmte Zeitüberschreitungen anpassen, damit der Verwaltungscluster genügend Zeit hat, um eine Verbindung mit den Arbeitslastcluster-Rechnern herzustellen. Informationen zum Anpassen dieser Zeitüberschreitungen finden Sie unter Verlängern der Zeitüberschreitungen, damit Edge-Cluster höhere Latenzen bewältigen können unten.
Angeben einer lokalen VM-Vorlage
Wenn Ihre Edge-Arbeitslastcluster ihren eigenen isolierten Speicher und nicht den gemeinsam genutzten vCenter-Speicher verwenden, müssen Sie sie so konfigurieren, dass sie Knoten-VM-Vorlagen-Images als OVA-Dateien vom lokalen Speicher abrufen.
HinweisSie können
tanzu cluster upgradenicht verwenden, um ein Upgrade der Kubernetes-Version eines Edge-Arbeitslastclusters mit einer lokalen VM-Vorlage durchzuführen. Führen Sie stattdessen ein Upgrade des Clusters durch, indem Sie das Upgrade eines Edge-Clusters mit einer lokalen VM-Vorlage im Thema Upgrade von Arbeitslastclustern durchführen.
So geben Sie eine einzelne VM-Vorlage für den Cluster oder verschiedene Vorlagen für die Bereitstellung von Worker- und Steuerungsebenen-Maschinen an:
-
Erstellen Sie die Clusterkonfigurationsdatei und generieren Sie das Clustermanifest als Schritt 1 des zweistufigen Prozesses, der unter Erstellen eines klassenbasierten Clusters beschrieben wird.
-
Stellen Sie sicher, dass die VM-Vorlagen für den Cluster:
- über eine gültige Kubernetes-Version für TKG verfügen.
- über eine gültige OVA-Version verfügen, die mit der Eigenschaft
spec.osImageseines TKr übereinstimmt. - auf das lokale vCenter hochgeladen werden und einen gültigen Bestandspfad haben, zum Beispiel
/dc0/vm/ubuntu-2004-kube-v1.26.8+vmware.1-tkg.1.
-
Bearbeiten Sie die
Cluster-Objektspezifikation im Manifest wie folgt, je nachdem, ob Sie eine clusterweite VM-Vorlage oder mehrere VM-Vorlagen definieren:-
Clusterweite VM-Vorlage:
- Legen Sie unter
annotationsrun.tanzu.vmware.com/resolve-vsphere-template-from-pathauf die leere Zeichenfolge fest. - Legen Sie im
vcenter-Block unterspec.topology.variablestemplateauf den Bestandspfad für die VM-Vorlage fest. -
Beispiel:
annotations: run.tanzu.vmware.com/resolve-vsphere-template-from-path: "" ... spec: topology: class: tkg-vsphere-default-v1.0.0 variables: - name: vcenter value: cloneMode: fullClone datacenter: /dc0 datastore: /dc0/datastore/sharedVmfs-0 folder: /dc0/vm/folder0 network: /dc0/network/VM Network resourcePool: /dc0/host/cluster0/Resources/rp0 ... template: VM-TEMPLATE ...Dabei ist
VM-TEMPLATEder Pfad zur VM-Vorlage für den Cluster.
- Legen Sie unter
-
Mehrere VM-Vorlagen pro
machineDeployment:- Legen Sie unter
annotationsrun.tanzu.vmware.com/resolve-vsphere-template-from-pathauf die leere Zeichenfolge fest. - Fügen Sie in
variables.overridesfür jedenmachineDeployments-Block unterspec.topology.workerundcontrolplaneeine Zeile fürvcenterhinzu, in dertemplatefür den Bestandspfad für die VM-Vorlage festgelegt wird. -
Beispiel:
annotations: run.tanzu.vmware.com/resolve-vsphere-template-from-path: "" ... spec: workers: machineDeployments: - class: tkg-worker metadata: annotations: run.tanzu.vmware.com/resolve-os-image: image-type=ova,os-name=ubuntu name: md-1 replicas: 2 variables: overrides: - name: vcenter value: ... datacenter: /dco template: VM-TEMPLATE ...Dabei ist
VM-TEMPLATEder Pfad zur VM-Vorlage für diemachineDeployment.
- Legen Sie unter
-
-
Verwenden Sie die geänderte Konfigurationsdatei, um den Cluster als Schritt 2 des unter Erstellen eines klassenbasierten Clusters beschriebenen Prozesses zu erstellen.
Verlängern der Zeitüberschreitungen, damit Edge-Cluster höhere Latenzen bewältigen können
Wenn Ihr Verwaltungscluster auf Edge-Sites ausgeführte Arbeitslastcluster remote verwaltet oder mehr als 20 Arbeitslastcluster verwaltet, können Sie bestimmte Zeitüberschreitungen anpassen, sodass die Cluster-API Maschinen, die vorübergehend offline sind oder länger als 12 Minuten mit ihrem Remoteverwaltungscluster kommunizieren, nicht blockiert oder beschneidet, insbesondere wenn Ihre Infrastruktur unterversorgt ist.
Es gibt drei Einstellungen, die Sie anpassen können, um den Edge-Clustern zusätzliche Zeit für die Kommunikation mit ihrer Steuerungsebene zu verschaffen:
-
MHC_FALSE_STATUS_TIMEOUT: Erweitern Sie den Standardwert12mauf beispielsweise40m, um zu verhindern, dass derMachineHealthCheck-Controller die Maschine neu erstellt, wenn die zugehörigeReady-Bedingung mehr als 12 Minuten aufFalsefestgelegt bleibt. Weitere Informationen zu Systemzustandsprüfungen von Maschinen finden Sie unter Konfigurieren von Maschinenintegritätsprüfungen für Tanzu Kubernetes-Cluster. -
NODE_STARTUP_TIMEOUT: Erweitern Sie den Standardwert20mauf beispielsweise60m, um zu verhindern, dass derMachineHealthCheck-Controller neue Maschinen daran hindert, dem Cluster beizutreten, da deren Start länger als 20 Minuten dauerte, was als fehlerhaft betrachtet wird. -
etcd-dial-timeout-duration: Verlängern Sie die Standard-10mbeispielsweise auf40sim Manifestcapi-kubeadm-control-plane-controller-manager, um zu verhindern, dassetcd-Clients auf dem Verwaltungscluster beim Prüfen der Integrität vonetcdauf den Arbeitslastclustern vorzeitig fehlschlagen. Der Verwaltungscluster nutzt seine Fähigkeit zur Herstellung der Verbindung mitetcdals Maßstab für die Maschinenintegrität. Beispiel:-
Führen Sie in einem Terminal Folgendes aus:
kubectl edit capi-kubeadm-control-plane-controller-manager -n capi-system -
Ändern Sie den Wert für
--etcd-dial-timeout-duration:- args: - --leader-elect - --metrics-bind-addr=localhost:8080 - --feature-gates=ClusterTopology=false - --etcd-dial-timeout-duration=40s command: - /manager image: projects.registry.vmware.com/tkg/cluster-api/kubeadm-control-plane-controller:v1.0.1_vmware.1
-
Darüber hinaus sollten Sie Folgendes beachten:
-
capi-kubedm-control-plane-manager : Wenn er aus irgendeinem Grund von den Arbeitslastclustern "abgetrennt" wird, müssen Sie ihn möglicherweise einem neuen Knoten zuweisen, damit er
etcdin Arbeitslastclustern ordnungsgemäß überwachen kann. -
Pinniped-Konfigurationen in TKG gehen alle davon aus, dass Ihre Arbeitslastcluster mit Ihrem Verwaltungscluster verbunden sind. Im Falle einer Trennung sollten Sie sicherstellen, dass Arbeitslast-Pods Administrator- oder Dienstkonten verwenden, um mit dem API-Server auf Ihren Edge-Sites zu kommunizieren. Andernfalls beeinträchtigt die Trennung vom Verwaltungscluster, dass sich Ihre Edge-Sites über Pinniped bei ihren lokalen Arbeitslast-API-Servern authentifizieren können.
