Erfahren Sie, wie Sie von Telegraf erfasste Supervisor-Metriken auf einer benutzerdefinierten Beobachtbarkeitsplattform streamen. Telegraf ist standardmäßig auf dem Supervisor aktiviert und erfasst Metriken im Prometheus-Format aus Supervisor-Komponenten, z. B. vom Kubernetes-API-Server, VM-Dienst, Tanzu Kubernetes Grid usw. Als vSphere-Administrator können Sie eine Beobachtbarkeitsplattform wie VMware Aria Operations for Applications, Grafana und andere konfigurieren, um die erfassten Supervisor-Metriken anzuzeigen und zu analysieren.
Telegraf ist ein serverbasierter Agent zum Erfassen und Senden von Metriken aus verschiedenen Systemen, Datenbanken und Internet der Dinge. Jede Supervisor-Komponente stellt einen Endpoint zur Verfügung, auf dem Telegraf eine Verbindung herstellt. Telegraf sendet dann die erfassten Metriken an eine Beobachtbarkeitsplattform Ihrer Wahl. Sie können ein beliebiges der von Telegraf unterstützten Ausgabe-Plug-Ins als Beobachtbarkeitsplattform für die Aggregierung und Analyse der Supervisor-Metriken konfigurieren. Informationen zu den unterstützten Ausgabe-Plug-Ins finden Sie in der Telegraf-Dokumentation.
Die folgenden Komponenten stellen Endpunkte zur Verfügung, auf denen Telegraf eine Verbindung herstellt und Metriken erfasst: Kubernetes-API-Server, etcd, kubelet, Kubernetes-Controller-Manager, Kubernetes-Scheduler, Tanzu Kubernetes Grid, VM-Dienst, VM-Imageservice, NSX Container Plug-in (NCP), Container Storage Interface (CSI), Zertifikatsmanager, NSX und verschiedene Hostmetriken wie CPU, Arbeitsspeicher und Speicher.
Anzeigen der Telegraf-Pods und -Konfiguration
Telegraf wird unter dem vmware-system-monitoring-System-Namespace auf dem Supervisor ausgeführt. So zeigen Sie die Telegraf-Pods und ConfigMaps an:
- Melden Sie sich bei der Supervisor-Steuerungsebene mit einem vCenter Single Sign-On-Administratorkonto an.
kubectl vsphere login --server <control planе IP> --vsphere-username [email protected]
- Verwenden Sie den folgenden Befehl, um die Telegraf-Pods anzuzeigen:
kubectl -n vmware-system-monitoring get pods
Die resultierenden Pods lauten wie folgt:telegraf-csqsl telegraf-dkwtk telegraf-l4nxk
- Verwenden Sie den folgenden Befehl, um die Telegraf-ConfigMaps anzuzeigen:
kubectl -n vmware-system-monitoring get cm
Die resultierenden ConfigMaps lauten wie folgt:default-telegraf-config kube-rbac-proxy-config kube-root-ca.crt telegraf-config
Die
default-telegraf-config-ConfigMap enthält die Telegraf-Standardkonfiguration und ist schreibgeschützt. Sie können sie als Fallback-Option verwenden, um die Konfiguration intelegraf-configwiederherzustellen für den Fall, dass die Datei beschädigt ist oder Sie einfach die Standardwerte wiederherstellen möchten. Die einzige bearbeitbare ConfigMap isttelegraf-config. Sie definiert, welche Komponenten Metriken an die Telegraf-Agenten senden und an welche Plattformen sie senden. - Anzeigen der
telegraf-config-ConfigMap:kubectl -n vmware-system-monitoring get cm telegraf-config -o yaml
inputs der ConfigMap
telegraf-config werden alle Endpunkte der
Supervisor-Komponenten definiert, von denen Telegraf Metriken sowie die Metriktypen selbst erfasst. Beispielsweise definiert die folgende Eingabe den Kubernetes-API-Server als Endpunkt:
[[inputs.prometheus]]
# APIserver
## An array of urls to scrape metrics from.
alias = "kube_apiserver_metrics"
urls = ["https://127.0.0.1:6443/metrics"]
bearer_token = "/run/secrets/kubernetes.io/serviceaccount/token"
# Dropping metrics as a part of short term solution to vStats integration 1MB metrics payload limit
# Dropped Metrics:
# apiserver_request_duration_seconds
namepass = ["apiserver_request_total", "apiserver_current_inflight_requests", "apiserver_current_inqueue_requests", "etcd_object_counts", "apiserver_admission_webhook_admission_duration_seconds", "etcd_request_duration_seconds"]
# "apiserver_request_duration_seconds" has _massive_ cardinality, temporarily turned off. If histogram, maybe filter the highest ones?
# Similarly, maybe filters to _only_ allow error code related metrics through?
## Optional TLS Config
tls_ca = "/run/secrets/kubernetes.io/serviceaccount/ca.crt"
Die alias-Eigenschaft gibt die Komponente an, aus der Metriken erfasst werden. Die namepass-Eigenschaft gibt an, welche Komponentenmetriken von den Telegraf-Agenten offengelegt bzw. erfasst werden.
Obwohl die ConfigMap telegraf-config bereits eine breite Palette von Metriken enthält, können Sie dennoch zusätzliche Metriken definieren. Weitere Informationen finden Sie unter Metriken für Kubernetes-Systemkomponenten und Kubernetes-Metrikreferenz.
Konfigurieren der Beobachtbarkeitsplattform für Telegraf
Im Abschnitt outps von telegraf-config können Sie konfigurieren, wo Telegraf die erfassten Metriken streamt. Es gibt mehrere Optionen wie outputs.file, outputs.wavefront, outputs.prometheus_client und outps-https. Im Abschnitt outps-https können Sie die Beobachtungsplattformen konfigurieren, die Sie für die Zusammenfassung und Überwachung der Supervisor-Metriken verwenden möchten. Sie können Telegraf so konfigurieren, dass Metriken an mehr als eine Plattform gesendet werden. Um die ConfigMap telegraf-config zu bearbeiten und eine Beobachtbarkeitsplattform zum Anzeigen von Supervisor-Metriken zu konfigurieren, führen Sie die folgenden Schritte aus:
- Melden Sie sich bei der Supervisor-Steuerungsebene mit einem vCenter Single Sign-On-Administratorkonto an.
kubectl vsphere login --server <control planе IP> --vsphere-username [email protected]
- Speichern Sie die ConfigMap
telegraf-configim lokalen kubectl-Ordner:kubectl get cm telegraf-config -n vmware-system-monitoring -o jsonpath="{.data['telegraf\.conf']}">telegraf.confSpeichern Sie die
telegraf-config-ConfigMap in einem Versionskontrollsystem, bevor Sie Änderungen daran vornehmen, falls Sie eine vorherige Version der Datei wiederherstellen möchten. Wenn Sie die Standardkonfiguration wiederherstellen möchten, können Sie die Werte aus derdefault-telegraf-config-ConfigMap verwenden. - Fügen Sie
outputs.http-Abschnitte mit den Verbindungseinstellungen der Beobachtbarkeitsplattformen Ihrer Wahl hinzu, indem Sie einen Texteditor verwenden, z. B. VIM:vim telegraf.config
Sie können die Auskommentierung des folgenden Abschnitts direkt aufheben und die Werte entsprechend bearbeiten oder nach Bedarf neueoutputs.http-Abschnitte hinzufügen.#[[outputs.http]] # alias = "prometheus_http_output" # url = "<PROMETHEUS_ENDPOINT>" # insecure_skip_verify = <PROMETHEUS_SKIP_INSECURE_VERIFY> # data_format = "prometheusremotewrite" # username = "<PROMETHEUS_USERNAME>" # password = "<PROMETHEUS_PASSWORD>" # <DEFAULT_HEADERS>So sieht beispielsweise eineoutputs.http-Konfiguration für Grafana aus:[[outputs.http]] url = "http://<grafana-host>:<grafana-metrics-port>/<prom-metrics-push-path>" data_format = "influx" [outputs.http.headers] Authorization = "Bearer <grafana-bearer-token>"
Weitere Informationen zum Konfigurieren von Dashboards und zur Nutzung von Metriken von Telegraf finden Sie unter Streamen von Metriken von Telegraf zu Grafana.
Im Folgenden finden Sie nun ein Beispiel mit VMware Aria Operations for Applications (ehemals Wavefront):[[outputs.wavefront]] url = "http://<wavefront-proxy-host>:<wavefront-proxy-port>"Die empfohlene Methode zur Erfassung von Metriken für Aria Operations for Applications ist Proxy-basiert. Weitere Informationen dazu finden Sie unter Wavefront-Proxies .
- Ersetzen Sie die vorhandene
telegraf-config-Datei auf dem Supervisor durch die Datei, die Sie in Ihrem lokalen Ordner bearbeitet haben:kubectl create cm --from-file telegraf.conf -n vmware-system-monitoring telegraf-config --dry-run=client -o yaml | kubectl replace -f -
- Überprüfen Sie, ob die neue Konfiguration erfolgreich gespeichert wurde:
- Zeigen Sie die neue telegraf-config-ConfigMap an:
kubectl -n vmware-system-monitoring get cm telegraf-config -o yaml
- Überprüfen Sie, ob alle Telegraf-Pods ausgeführt werden:
kubectl -n vmware-system-monitoring get pods
- Wenn einige der Telegraf-Pods nicht ausgeführt werden, überprüfen Sie die Telegraf-Protokolle für diesen Pod, um eine Fehlerbehebung durchzuführen:
kubectl -n vmware-system-monitoring logs <telegraf-pod>
- Zeigen Sie die neue telegraf-config-ConfigMap an:
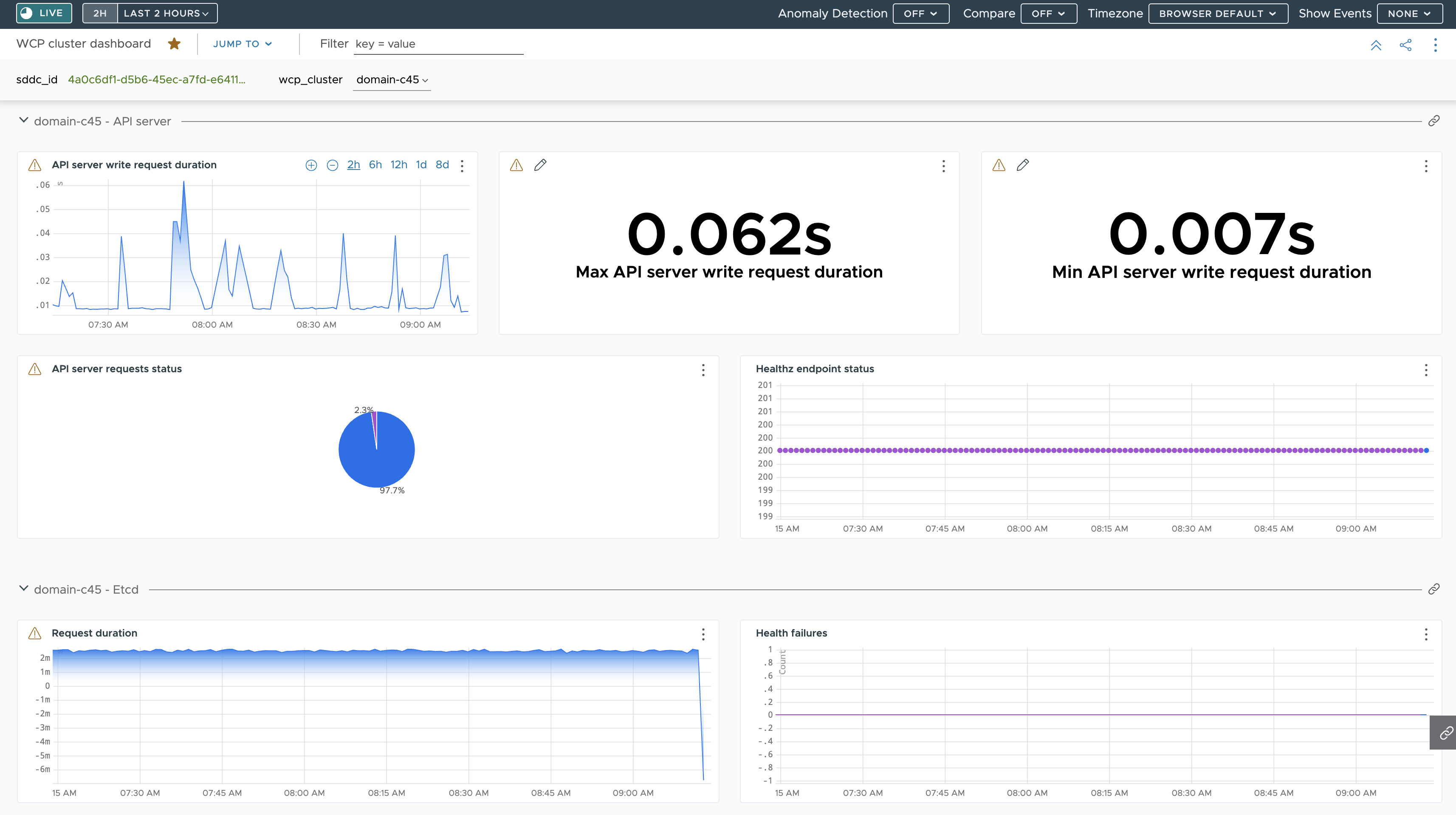
Beispiel-Dashboards für Operations for Applications
Im Folgenden wird ein Dashboard mit einer Übersicht für die Metriken gezeigt, die vom API-Server und von etcd auf einem Supervisor über Telegraf empfangen wurden:
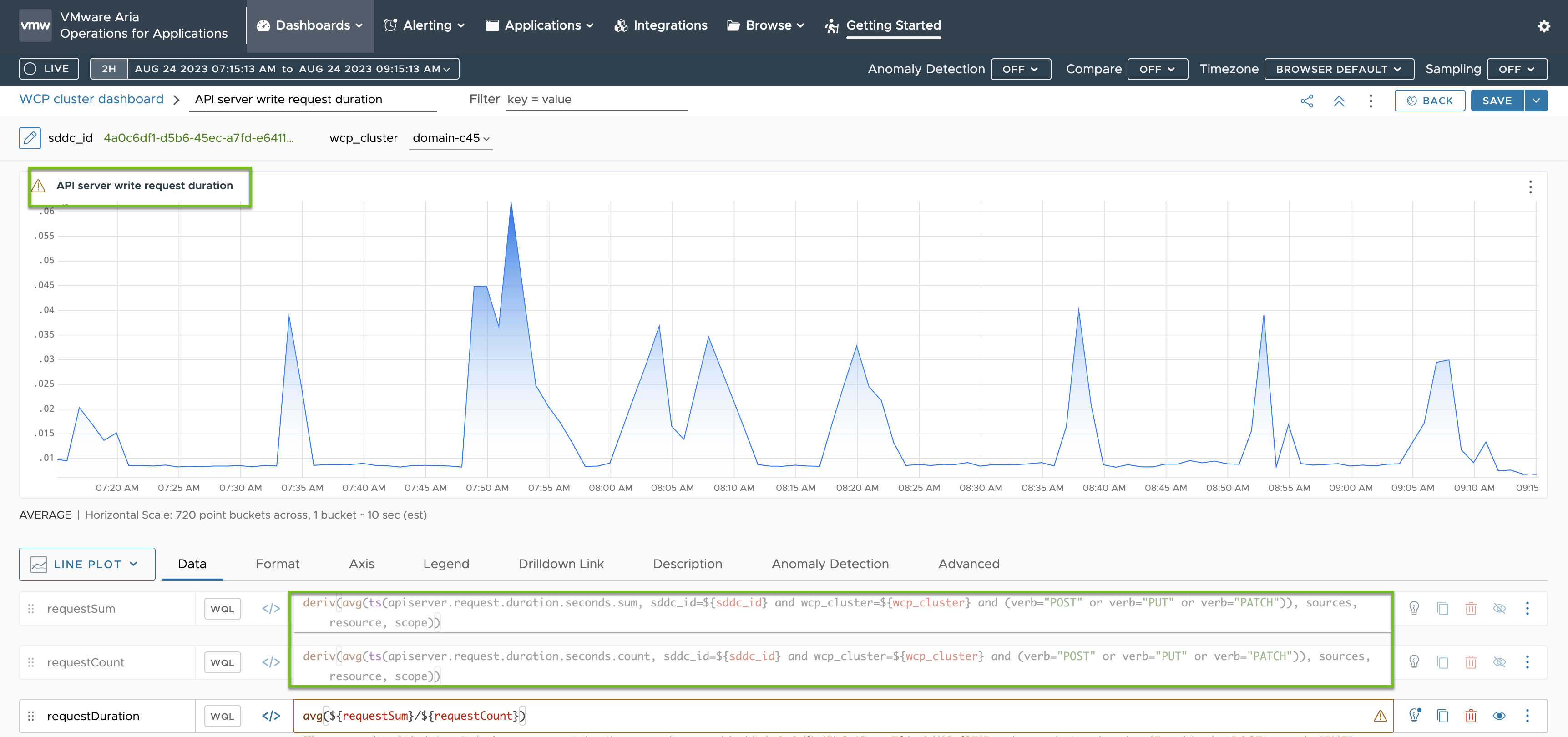
Die Metriken für die Dauer der API-Server-Schreibanforderung basieren auf den Metriken, die in der ConfigMap telegraf-config angegeben sind. Sie sind grün hervorgehoben: