









The Client node sends requests to the blockchain nodes and receives the results of running the requests.

The external application sends commands to the Daml Ledger API component of the Client node. The Daml Ledger API component forwards the command to a pool of the BFT clients, which sends the requests to the Replica Network to be executed and waits to collect the results from the Replica nodes. The BFT client forwards the results back to the Daml Ledger API. The Daml Ledger API receives the command execution results using the PostgreSQL notification.
When the Replica node thin-replica protocol sends the result to the Client nodes subscribed to receive these updates, the Client node thin-replica protocol receives the update and writes it into the local client PostgreSQL. After data is written to PostgreSQL, a notification that the update was written in the local DB is sent to the Daml Ledger API.
The PostgreSQL DB stores a materialized view of the Replica Network, which is the data that the specific Client node is permitted to view in a processed format.
BFT Client Protocol
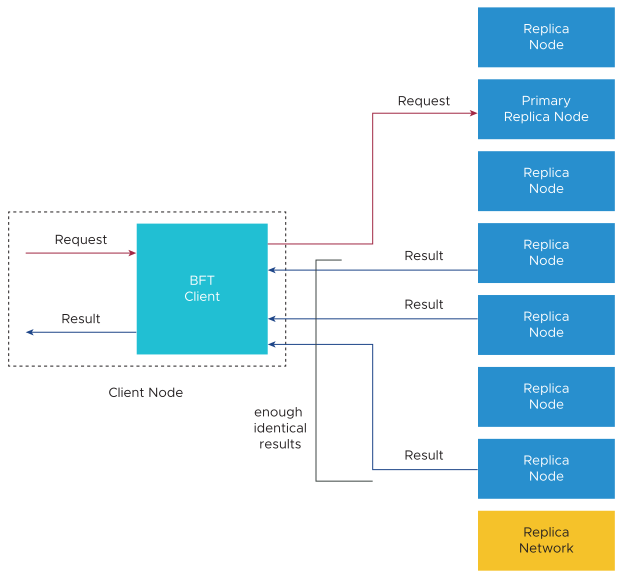
The BFT client must ensure the validity of the data collected from the Replica Network before sending it back to the application.
The BFT client collects and compares the results received from each Replica node. For example, when the BFT client receives an application request, this request is sent from the BFT client to the Replica Network. After each Replica node executes the request, each node sends the result back to the BFT client. When the BFT client collects sufficient replies, it can return the result to the application. The Client node waits for 2f+1 identical results before returning a reply (the Client node does not need to wait for n identical results).
The BFT client usually communicates with the primary Replica node. The BFT client sends requests to the primary Replica node. The primary Replica node then forwards the request to the rest of the Replica nodes to be executed, and these nodes in the network send the execution result directly back to the Client node.
If the BFT client does not know the primary Client node, it sends the request to all the Replica nodes in the network. The results returned by the Replica nodes include the primary Replica node ID. After f+1 results are returned, the BFT client can identify the primary Replica node and send the request only to that primary Replica node.
If a view change occurs and another Replica node becomes the primary, then the Client node might need to broadcast the request to all the Replica nodes in the network. Then, the Client node waits for the results to discover the new Replica primary node.
A view change can occur when the primary Replica node is down and directly connected to the primary Replica node times out. In this case, the BFT client reverts to sending the request to all the Replica nodes. The timeout is computed dynamically and set to the average measured communication speed plus three standard deviations.
Request Execution
After the Replica nodes reach a consensus on the execution order of the requests, each Damle on the Replica node executes the requests and creates a write set to be added to the local storage of the Replica node.
The write set is a list of key plus values that result from the request execution. This result must be persisted in the local key-value store (RocksDB) and returned to the BFT client, which initially requested the request execution.
After each request execution, a new block is added to the blockchain. Every write set added to the local store constitutes a new block in the blockchain. The block includes the previous block hash, which connects the new block to the previous block. As a result, the term blockchain. The hash is obtained by reading the previous block stored in the key-value store and computing its hash.
Each application data key in the authenticated key-value ledger has an Access Control List (ACL) that determines which Client node can receive this key through the thin-replica protocol. The Damle maintains the association of the ACL to an application data key. Thus, during the Daml party allocation process on a Client node, an association between that party and the Client node is made and stored on the blockchain.
This association also results in the Client node being assigned a unique logical ID that forms how the state updates are filtered from the Replica Network to the Client nodes. The Replica node thin-replica protocol sends the updates to the Client nodes subscribed to receive these updates.
Pre-Interpretation Process
The Client node performs some pre-interpretation of the request it receives before forwarding it to the Replica Network. The pre-interpretation resultsin a request with a list of Read keys. The Daml execution engine (Damle) must read the key values before executing the request on the Replica nodes.
The output of each pre-interpretation is sent to the Replica Network using one of the BFT clients in the client pool. The Client node can aggregate several requests into a batch before sending the requests to the Replica Network. The number of requests in a batch depends on several parameters. For example, the total batch size must not exceed some maximum, and the batch must be closed after a specific timeout.
The Damle opens the batch request on each Replica node, and each request in the batch is executed in a separate thread. The total time it takes to execute a batch depends on the slowest command in that batch. If the pre-execution process is turned on, it is more efficient for the Replica nodes to batch executions, and the Client node batching is therefore turned off.
Client Node Groups
Each physical Client node has a client ID. You can deploy different Client nodes with the same client ID. Clients with the same client ID are called duplicate clients.
Since Client nodes are subscribed to receive updates from the Replica Network based on their thin-replica ID, all the duplicate Client nodes receive the same updates whenever the Replica Network state changes. See the party allocation process in Request Execution.
The application can use duplicate Client nodes to load balance the Daml Ledger API calls and as a High Availability (HA) capability to switch from one duplicate Client node to another when a Client node malfunctions.
For example, load balancing helps overcome the limit on each physical Client node's maximum number of concurrent connections. HA between the duplicate Client nodes is used by having duplicate Client nodes on a different data center. When a Client node on one data center is not responding, the application can switch to the duplicate one on another data center.
The application receives all the duplicate Client nodes IP addresses and handles the load-balancing and HA between them.
The Client nodes do not synchronize, and the synchrony between the duplicate Client nodes is performed in a best-effort mode. One implication of this implementation is that one duplicate Client node might have received updates that one of the other duplicates has not yet received.
Therefore, if an application uses one duplicate Client node and switches over to another duplicate Client node, the application might refer to the values that the other duplicate Client node has not received. In such a case, the Client node returns an OUT_OF_RANGE error message, and the application must wait. After retry, the newer duplicate Client node is updated with the previous Client node's data. See Daml documentation https://docs.daml.com/.
Pre-Execution Process
When the primary Replica node receives a request, each Replica node applies pre-execution, meaning that multiple requests are executed in parallel by the Damle.
After the request execution, the Replica node sends the resulting Read-Write set to the primary Replica node. The primary Replica node waits for f+1 identical Read-Write set results. These results are aggregated into a batch and sent through the consensus protocol to have all the Replica nodes agree on the batch execution order.
After the batch execution order is complete, the batch is unpacked at each Replica node. The post-execution process starts with a contention test where the version of each Read in the Read-set is checked. If the value is the same as the current value in the local store, then the Write-set can be written into the RocksDB local store. If there are Reads with different values,an error message is returned to the Daml Ledger API.
The pre-execution process provides the following benefits:
Significant improvement for system performance because the system does not wait for the long-running requests to be approved to start the consensus protocol. Slow-running requests and long-running requests are run in parallel.
Safeguard against non-deterministic code errors during the execution phase. Requests submitted to the Replica Network are pre-executed and not committed before consensus and ordering.
