









The design of physical infrastructure resources for private AI ready infrastructure for VMware Cloud Foundation include hardware components and features to support AI workloads on a virtualized platform.
Global SR-IOV
Single Root I/O Virtualization (SR-IOV) is a specification that allows a single PCIe physical device under a single root port to appear as multiple separate Virtual Functions to the hypervisor or the guest operating system.
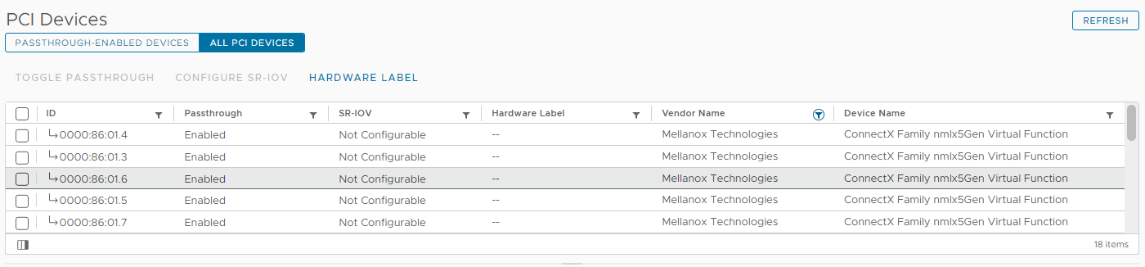
SR-IOV is required for this validated solution to enable virtual functions from a NIC and HBA and is also required for both MIG and time-slicing modes of NVIDIA vGPU. For MIG, a vGPU is associated with a virtual function at boot time. For example, for a Mellanox ConnectX-6 NIC, you have the following virtual functions available:
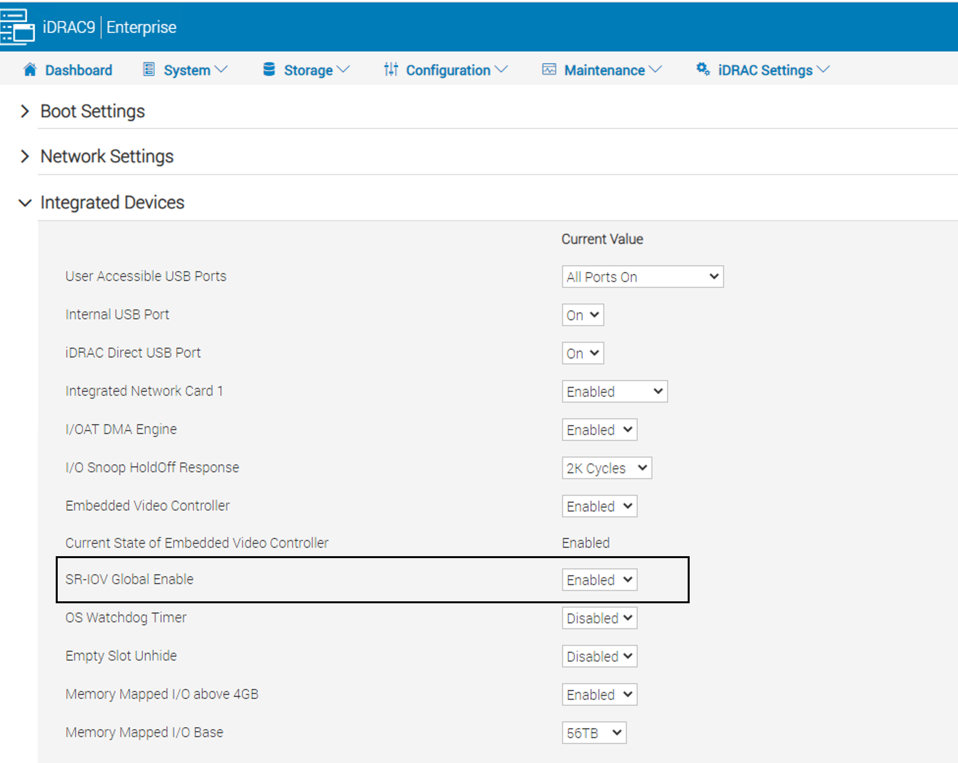
For information on how to enable SR-IOV at the BIOS/UEFI level, see the documentation from your server vendor. For example, you set Global SR-IOV by using Dell iDRAC in the following way:
NVIDIA GPUDirect RDMA, NVLink, and NVSwitch
The combination of GPUDirect RDMA (Remote Direct Memory Access), NVLINK, and NVSwitch are suitable for generative AI.
- GPUDirect RDMA enables direct GPU-to-GPU memory access through network devices, efficiently reducing latency and amplifying data sharing capabilities.
- NVLINK serves as a high-speed, low-latency bridge between GPUs, suitable for managing extensive datasets.
- NVSwitch orchestrates communication in multi-GPU configurations, offering a foundation for scaling generative AI.
GPUDirect RDMA on VMware vSphere
GPUDirect on vSphere works by using the NVIDIA vGPU technology and RDMA-capable network adapters like NVIDIA ConnectX-6. For virtual machines, to enable peer-to-peer communication between the PCIe devices on the same PCIe Root Complex, relax Access Control Services (ACS) in the virtual machine configuration settings and configure NUMA (Non-Uniform Memory Access) affinity or device groups. Device groups are supported with Tanzu Kubernetes Grid Service and you can configure the ACS relax setting by using advanced parameters in a VM class.
Using Device Groups in vSphere with NVIDIA GPUs and NVLink
In vSphere 8, device groups simplify the use of virtual machines with complementary hardware devices. These groups can include hardware devices connected via a common PCIe switch or direct interconnect. They are identified at the hardware level and presented to vSphere as a unified entity, which can be added to virtual machines and VM classes by using the standard workflow for adding a PCI device. Both vSphere DRS and vSphere HA recognize device groups and ensure virtual machine placement aligns with device group requirements.
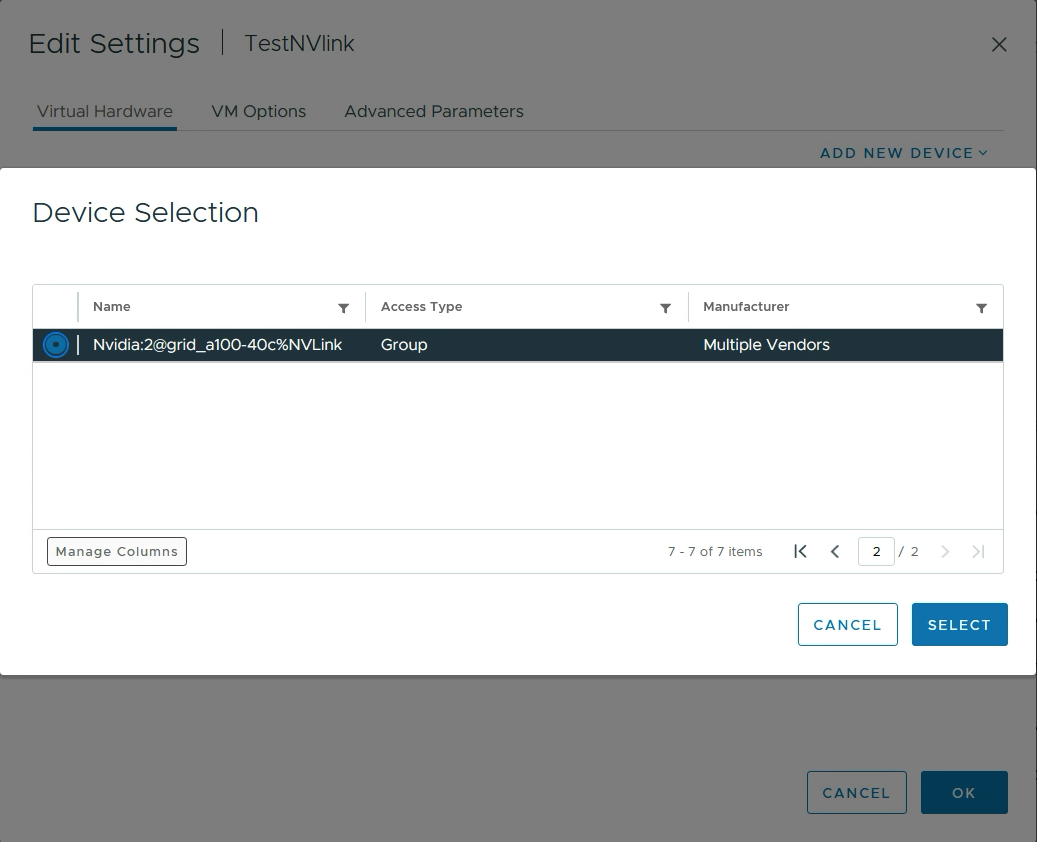
A device group can comprise at least two GPUs connected by NVIDIA NVLink, enhancing inter-GPU communication vital for ML/AI performance. NVLinks enable GPUs to share high bandwidth memory (HBM), facilitating larger machine learning models. NVLink can be programmatically activated or deactivated to form new device groups.
Typically, machine learning models are trained with Floating-Point 32-bit precision due to its high numerical precision, which helps in accurately representing complex mathematical computations during training. However, when it comes to deploying these models for inference tasks, especially in production environments, there's often a need to optimize for computational efficiency and resource utilization, this is achieved by converting to lower precisions such as Floating-Point 16-bit, Brain Floating Point 16 (BF16), or 8-bit Integer Precision (Int8) for inference deployment. This conversion reduces model size and computational demands, enabling deployment on fewer GPUs for inference as well as faster inferencing times.
