









Private AI ready infrastructure requires multiple networks. The network design includes choosing the physical network devices and creating physical network setup for running AI workloads.
The requirement for network devices for AI workloads depend on the specific task, dataset size, model complexity, or performance expectations.
| Category |
Hardware |
Description |
Example of Optimal Configuration (Based on NVIDIA DGX) |
|---|---|---|---|
| Management network |
|
|
|
| Workloads and VMware services such as vSphere vMotion, vSAN, network overlays, and so on. |
LLM inference and fine-tuning within a single host is sufficient with standard 2*25 Gbps Ethernet ports. For fine-tuning models larger than 40B parameters, efficient multi-node communication requires low latency, and optimal performance requires 100 Gbps or higher RDMA network (for example, RoCE or InfiniBand). |
|
Management Domain VLANs
For the management network, each network type is associated with a specific VLAN. See VMware Cloud Foundation Design Guide.
Workload Domain Network VLANs
The workload network on the workload cluster is configured with dedicated switch and network adapters for optimal performance. You deploy all vSphere with Tanzu workloads to overlay-backed NSX segments. NSX Edge nodes in the shared edge and workload vSphere cluster are deployed to VLAN-backed port groups.
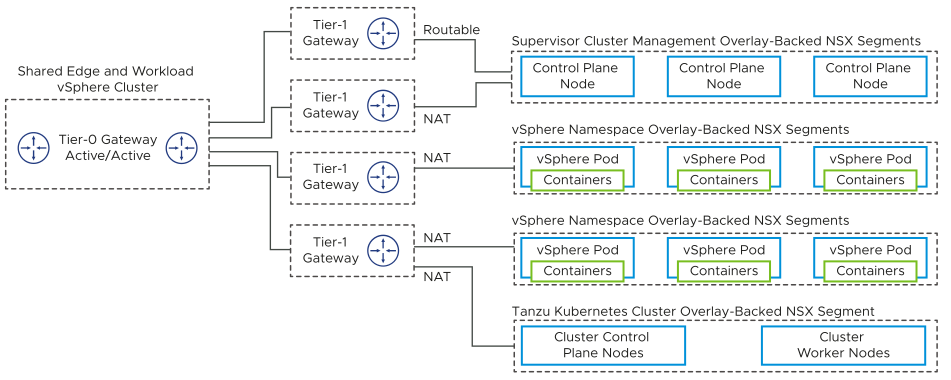
| Network |
Routable / NAT |
Usage |
|---|---|---|
| Supervisor Control Plane network |
Routable |
Used by the Supervisor control plane nodes. |
| Pod Networks |
NAT |
Used by Kubernetes pods that run in the cluster. Any Tanzu Kubernetes Grid Clusters instantiated in the Supervisor also use this pool.
|
| Service IP Pool Network |
NAT |
Used by Kubernetes applications that need a service IP address. |
| Ingress IP Pool Network |
Routable |
Used by NSX to create an IP pool for load balancing. |
| Egress IP Pool Network |
Routable |
Used by NSX to create an IP pool for NAT endpoint use. |
| Namespace Networks |
NAT |
When you create a namespace, a /28 overlay-backed NSX segment and corresponding IP pool is instantiated to service pods in that namespace. If that IP space runs out, an additional /28 overlay-backed NSX segment and IP pool are instantiated. |
| Tanzu Kubernetes Grid Networks |
NAT |
When you create a Tanzu Kubernetes Grid cluster, an NSX Tier-1 Gateway is instantiated in NSX. On that NSX Tier-1 Gateway, a /28 overlay-backed NSX segment and IP pool is also instantiated. |
Design Decisions on the Network Design for Private AI Ready Infrastructure
Decision ID |
Design Decision |
Design Justification |
Design Implication |
|---|---|---|---|
AIR-TZU-NET-001 |
Set up networking for 100 Gbps or higher if possible. |
100 Gbps networking provides enough bandwidth and very low latency for inference and fine-tuning use cases backed by vSAN ESA. |
The cost of the solution is increased. |
AIR-TZU-NET-002 |
Add a /28 overlay-backed NSX segment for use by the Supervisor control plane nodes. |
Supports the Supervisor control plane nodes. |
You must create the overlay-backed NSX segment. |
AIR-TZU-NET-003 |
Use a dedicated /20 subnet for pod networking. |
A single /20 subnet is sufficient to meet the design requirement of 2000 pods. |
You must set up a private IP space behind a NAT that you can use in multiple Supervisors. |
AIR-TZU-NET-004 |
Use a dedicated /22 subnet for services. |
A single /22 subnet is sufficient to meet the design requirement of 2000 pods. |
Private IP space behind a NAT that you can use in multiple Supervisors. |
AIR-TZU-NET-005 |
Use a dedicated /24 or larger subnet on your corporate network for ingress endpoints. |
A /24 subnet is sufficient to meet the design requirement of 2000 pods in most cases. |
This subnet must be routable to the rest of the corporate network. A /24 subnet will be sufficient for most use cases, but you should evaluate your ingress needs before deployment. |
AIR-TZU-NET-006 |
Use a dedicated /24 or larger subnet on your corporate network for egress endpoints. |
A /24 subnet is sufficient to meet the design requirement of 2000 pods in most cases. |
This subnet must be routable to the rest of the corporate network. A /24 subnet will be sufficient for most use cases, but you should evaluate your egress needs before to deployment. |
