









Command Center allows you create and manage Greenplum Streaming Server (GPSS) client jobs for loading data from external sources into Greenplum Database. Currently, the only external data source type supported is Amazon S3.
You access Command Center's data loading feature via the Data Loading> Jobs view.
Prerequisites for Data Loading Feature
The following are the prerequisites for using the Command Center data loading feature:
You must configure GPSS server access before creating jobs. See Configuring GPSS Server Access for details.
You must install GPSS server version 1.7.0 or higher and configure it correctly.
The GPSS extension must be registered on the target database.
Creating Jobs
There are two different workflows for creating your job:
The "Default Creation Workflow", in which you enter data in the UI via a 5-step process. This approach requires that your source data have fewer than 30 columns of data.
The YAML file workflow, in which you upload a YAML file specifying the properties of your desired job configuration.
Creating a Job with the Default Creation Workflow
Follow these steps to create a data loading job by entering data in the UI:
Click Create.
The "Default Creation Workflow" radio button is already selected; simply click Next.
Fill in the fields as follows:
Enter the Job Name
The Source Type defaults to S3, the only supported source type at this time
Enter the S3 File Location. The S3 File Location should be in this format:
s3://s3."Region".amazonaws.com/"bucket-name"/"key-name", for examples3://s3.us-west-2.amazonaws.com/mybucket/mydata.csv. For more information, see this section in the Greenplum Database Administrator Guide.Enter the S3 Access Key
Enter the S3 Secret Key
The File Type defaults to CSV, the only supported file type at this time
Under "Advanced File Options", choose CSV options
Click Next.
Define the input columns for your source data; this includes the column name and datatype for each column.
NOTE: You must add every column from the data source file; for example, if there are 30 columns in the data source file there must be 30 rows added to this page. Otherwise, data loading will fail.
Click Next.
Enter information about the Greenplum Database table you want to load data into. This information includes:
the mode: the choices are INSERT, UPDATE, or MERGE
the database name
the schema name
the table name
the error limit, which determines the number of errors that can occur before the data loading job must be stopped. This can be a number or a percentage.
the hostname or IP address of the master host
the username of the GPDB user loading the data into the database
the password of the GPDB user loading the data into the database
Click Next.
Command Center populates the Column Name and Type columns with data from the table you provided in Step 7. Use the Expression column to enter expressions for transforming the data extracted from the S3 data source into column data for the Greenplum Database table you're loading data into. For details on how to set up mappings of source columns to output columns, see the filesource-v3.yaml topic.
NOTE: Command Center will discard any row data for output rows whose Expression column you leave blank.
Click Next to bring up the "Review and Start" screen.
At this point you have one of three choices:
Click Submit to submit the load to the GPSS server instance; GPSS then registers the job in its job list. The job now has a status of "Submitted."
Click Dry Run to perform a trial load without writing to Greenplum Database.
Click Start Now to start up the job. The job now has a status of "Started."
Creating a Job by Uploading a YAML File
Follow these steps to create a data loading job using a YAML file:
Click Create.
Click the radio button in the "Upload YAML Fiile" box.
Click Next to bring up the "Choose Input Source" screen.
Enter a job name. The job name is composed of:
- A prefix, which is made up of "gpcc_
" followed by an another underscore. - The remainder of the job name. The default for this portion is the current GPCC login user name followed by an underscore, followed by a timestamp.
Here is a sample job name: `gpcc_msvm_gpmon_202204070412`
Choose a YAML file to upload, by clicking CHOOSE FILE and entering a path to the YAML file you want to upload. To create a YAML file, you can refer to this sample YAML, which is a sample GPSS load configuration file for loading data from an S3 data source.
Click Next to bring up the "Review and Start" screen.
At this point you have one of three choices:
Click Submit to submit the load to the GPSS server instance; GPSS then registers the job in its job list. The job now has a status of "Submitted."
Click Dry Run to perform a trial load without writing to Greenplum Database.
Click Start Now to start up the job. The job now has a status of "Started."
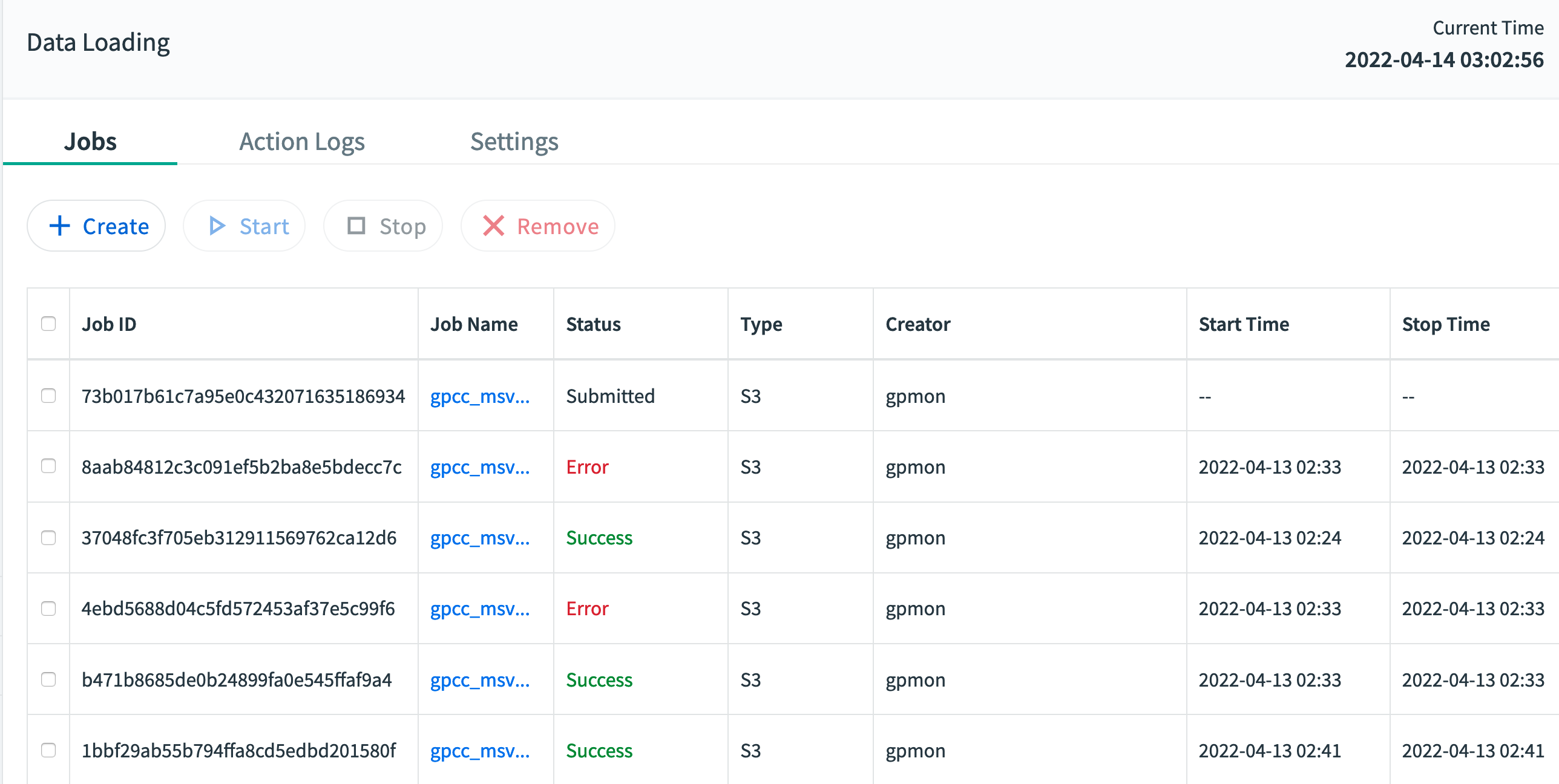
Managing Jobs
In addition to creating new jobs, you may start, stop, or remove existing jobs:
To start a job, select the job and click Start.
To stop a job, select the job you want to stop and click Stop.
To remove a job, select the job you want to remove and click Remove.
To perform an operation on multiple jobs, select the desired jobs and then click Start, Stop, or Remove.
Permissions Required for Job Management
All users can view, start, stop, remove, and view logs for jobs they created. However, the superuser -- known as "Admin" -- role is required to perform these actions on jobs created by other users.
About Job IDs
Once a job is created, it is assigned a job ID. A job's ID is determined by its data source and the target (database name plus schema name plus table name).
IMPORTANT: The same combination of a data source and a target always produces the same job ID. This means that if a user creates a job with the same data source and target with an existing job, then the job is not created as a new job. Instead, the existing job is updated because the ID is identical.
