









Tanzu Greenplum text enables processing mass quantities of raw text data (such as social media feeds or e-mail databases) into mission-critical information that guides business and project decisions. Tanzu Greenplum text joins the VMware Greenplum massively parallel-processing database server with Apache SolrCloud enterprise search. Tanzu Greenplum text includes powerful text search as well as support for text analysis. Tanzu Greenplum text supports business decision making by offering:
- Multiple kinds of data: Tanzu Greenplum text supports both semi-structured and unstructured data searches, which exponentially increases the kinds of information you can find.
- Multiple document sources: Tanzu Greenplum text can index documents stored in VMware Greenplum tables or documents retrieved from external stores, such as HTTP or FTP servers, Amazon S3 or other S3-compatible storage, or Hadoop hdfs. Most document formats are recognized automatically.
- Less schema dependence: Tanzu Greenplum text does not require static schemas to successfully locate information; schemas can change or be quite simple and still return targeted results.
- Natural language text processing: Tanzu Greenplum text provides NLP capabilities with the integrated Apache OpenNLP toolkit.
- Text analytics: You can use Apache MADlib in VMware Greenplum for advanced machine learning, graph, statistics and analytics in VMware Greenplum.
This chapter contains the following topics:
- Tanzu Greenplum Text System Architecture
- Tanzu Greenplum Text Sample Use Case
- Tanzu Greenplum Text Workflow
- Text Analysis
Tanzu Greenplum Text System Architecture
Tanzu Greenplum text combines a VMware Greenplum cluster with an Apache SolrCloud cluster. VMware Greenplum segments and Tanzu Greenplum text nodes can be deployed on the same hosts or on different hosts with network connectivity.
The following figure shows the process architecture of the combined VMware Greenplum and ApacheSolr clusters. The figure shows four cluster nodes with four Greenplum segments and four Solr instances deployed on each. An Apache ZooKeeper service manages the SolrCloud cluster. ZooKeeper nodes are deployed on three of the four hosts. VMware Greenplum users access SolrCloud services via Tanzu Greenplum text user-defined functions installed in VMware Greenplums and command-line utilities.
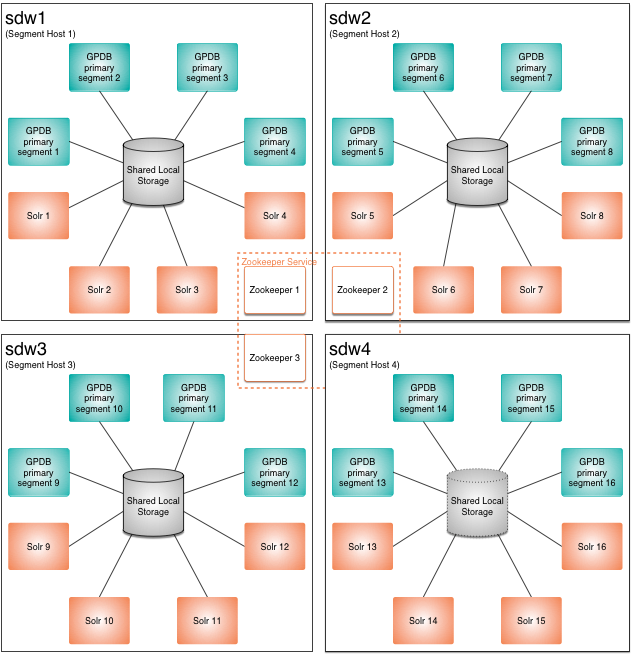
The figure omits the Greenplum master host, secondary master, and mirror segments for the Greenplum primary segments.
The Greenplum segments, Solr instances, and ZooKeeper nodes may all be deployed on separate hosts on the same network, depending on application and performance requirements.
The following sections describe how Tanzu Greenplum text integrates SolrCloud with VMware Greenplum and how the two clusters work together to provide parallel text search capabilities in VMware Greenplum and maintain high availability.
VMware Greenplum Cluster
A VMware Greenplum cluster is comprised of the following components:
- A master database instance, executing on a dedicated host, conventionally named
mdw. (Not illustrated) - A secondary master instance, on a host conventionally named
smdw, acting as a warm standby for the master instance. (Not illustrated) - An array of database primary segment instances and mirrors deployed on segment hosts, by convention
sdw1throughsdwn. A segment instance is an independent Postgres database server managing a portion of the distributed data. Each segment has a mirror (not illustrated) on another host in the cluster to provide uninterrupted service in case of a segment or segment host failure. The number of primary segments per host is determined by the hardware configuration—the number and type of processor cores, the amount of physical RAM, local storage capacity, and network capacity—as well as availability and performance requirements.
The VMware Greenplum master instance, which stores no user data, coordinates the work of the segment instances. Database users log in to the master instance and submit SQL queries. The master instance creates a plan for executing the query, distributes the work to the segments, and gathers and returns the results to the user.
Apache SolrCloud
Apache Solr is a server providing access to Apache Lucene full-text indexes. Apache SolrCloud is a highly available, fault tolerant cluster of Apache Solr servers. The term Tanzu Greenplum text cluster is another way to refer to a SolrCloud cluster deployed by Tanzu Greenplum text for use with a VMware Greenplum system.
A SolrCloud cluster is comprised of the following components:
- An Apache ZooKeeper cluster to manage the SolrCloud cluster. SolrCloud uses ZooKeeper to manage server and index configurations and to coordinate the cluster's activities. Tanzu Greenplum text can install a ZooKeeper cluster that is bound to the Tanzu Greenplum text cluster, or it can share an existing ZooKeeper cluster. If Tanzu Greenplum text installs the ZooKeeper cluster, it can be managed using Tanzu Greenplum text functions and utilities. The ZooKeeper cluster can be deployed on VMware Greenplum cluster hosts or, for best performance, on separate hosts accessible to the VMware Greenplum cluster.
- Multiple SolrCloud server instances deployed on the Greenplum segment hosts or on other hosts on the same network. Each instance is a JVM process running Solr server. SolrCloud instances use local storage, which may be the same local storage volumes that store VMware Greenplum data. The number of SolrCloud instances per host can be the same as the number of Greenplum primary segments per host, but this is not a requirement. The number of instances to execute per host is specified during Tanzu Greenplum text installation.
Tanzu Greenplum text provides document indexing and search capabilities for VMware Greenplum with user-defined functions (UDFs) that access Solr APIs from within database queries.
Tanzu Greenplum text UDFs perform the following tasks:
- create and manage Tanzu Greenplum text indexes
- provide status information about indexes
- insert documents into indexes from database tables or, for Tanzu Greenplum text external indexes, from documents stored outside of VMware Greenplum
- search indexes
There are also Tanzu Greenplum text UDFs and command-line utilities to configure, monitor, and manage the SolrCloud cluster, and to manage replicas, SolrCloud's high-availability mechanism. (More on replicas in the next section.)
Parallelism in Tanzu Greenplum Text Indexing and Searching
SolrCloud distributes document indexes in slices called shards. Each shard is managed by a SolrCloud instance and ZooKeeper ensures that the shards are distributed evenly among the SolrCloud instances. The SolrCloud instances and Greenplum segments are not required to be on the same hosts.
With Tanzu Greenplum text, the default number of shards for an index is the number of VMware Greenplum segments, so that each segment operates on an equal portion of the index. Optionally, a lesser number of shards can be specified when you create a Tanzu Greenplum text index, allowing indexing workloads to be scaled for performance requirements and resource usage.
High Availability for Tanzu Greenplum Text Indexes
SolrCloud provides high availability by maintaining replicas of shards and providing automatic failover if a shard fails or becomes unavailable. One replica of each shard is the lead replica and any changes to it are applied to the other replicas. The replication factor, which determines the number of replicas to maintain for each shard, is set when the index is created. Replicas may also be added or dropped later using Tanzu Greenplum text UDFs or command-line utilities.
ZooKeeper determines the locations of shard replicas among the Solr nodes and hosts. When adding a replica using a Tanzu Greenplum text UDF or command-line utility, a new shard can be explicitly placed on a SolrCloud instance.
Tanzu Greenplum Text Sample Use Case
Forensic financial analysts need to locate communications among corporate executives that point to financial malfeasance in their firm. The analysts use the following workflow:
- Load the email records into a VMware Greenplum.
- Create a Solr index of the email records.
- Run queries that look for text strings and their authors.
- Refine the queries until they pair a dummy company name with top three or four executives corresponding about suspect offshore financial transactions. With this data, the analysts can focus the investigation on specific individuals rather than the thousands of authors in the initial data sample.
Tanzu Greenplum Text Workflow
Tanzu Greenplum text works with VMware Greenplum and Apache SolrCloud to store and index big data for information retrieval (query) purposes. High-level workflows include data loading and indexing, and data querying.
This topic describes the following information:
Data Loading and Indexing Workflow
The following diagram shows the Tanzu Greenplum text workflow for loading and indexing data.
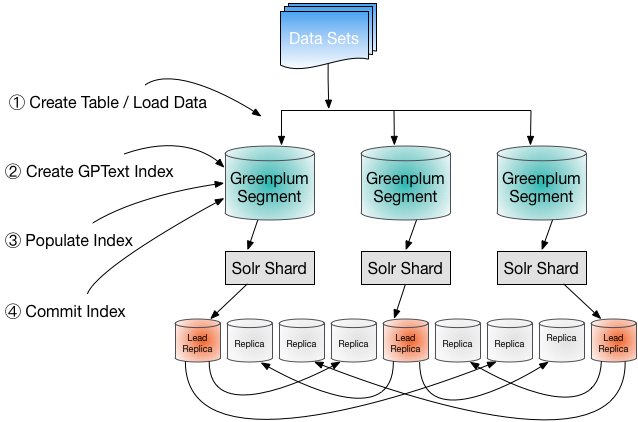
All client interaction with the system is through the Greenplum master instance.
Load data into your VMware Greenplum system.
Create a database table to hold data and then add the data to the table. Greenplum provides parallel data loading utilities and protocols that help to transform and load external data in various formats and from various sources. For details, see the VMware Greenplum Administrator Guide, at http://gpdb.docs.pivotal.io.
You can also create an external index for documents you retrieve from a web server, an ftp server, Amazon S3 or other S3-compatible storage, or Hadoop.
Create and configure an empty Tanzu Greenplum text index.
Use the
gptext.create_index()user-defined function (UDF) to create an empty Tanzu Greenplum text index for a database table. Tanzu Greenplum text stores configuration files for the index in ZooKeeper.Customize the index, if desired, by editing the index configuration files with the
gptext-configcommand-line utility. You can customize the way document text is tokenized, filtered, and transformed before storing in the index and how query text is prepared to search the index.Populate the index with data from the database table or external data source.
Use the
gptext.index()orgptext.index_external()UDF to add data to the index. These UDFs work by dispatching SQL queries to execute on each Greenplum segment. The segments execute the queries and add the results to the index using Solr APIs.Commit changes to the index.
Commit changes to the Tanzu Greenplum text index by calling the
gptext.commit_index()UDF. Until the changes are committed, queries executed on the index cannot access any data added to the index withgptext.index(). If needed, uncommitted changes can be rolled back. SolrCloud replicates changes committed to the lead replica to the shards' non-lead replicas.
Querying Data Workflow
The following diagram shows the high-level Tanzu Greenplum text query process workflow:
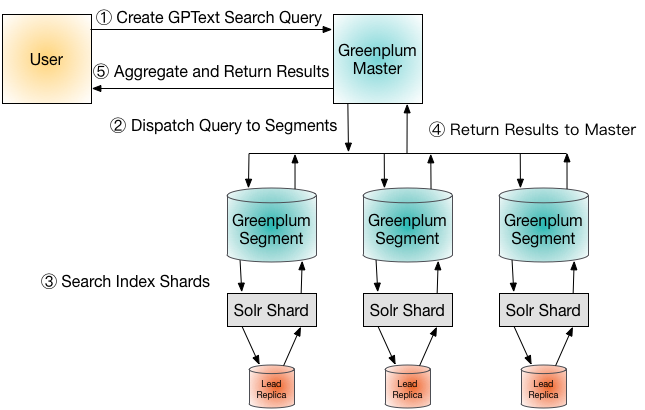
A user submits a SQL query designed to search the indexed data.
A Tanzu Greenplum text search query is a SQL
SELECTstatement on a Tanzu Greenplum text search UDF that contains full-text search expressions.The Greenplum master dispatches the query to the VMware Greenplum segments.
Each segment executes the query, using the Solr API to search its index shard.
Solr analyzes and executes the search query on the lead replica for the shard.
The VMware Greenplum segments return the results of the search query to the VMware Greenplum master.
The VMware Greenplum master aggregates the results from all segments and returns them to the client.
Text Analysis
Tanzu Greenplum text enables analysis of Solr indexes with Apache MADlib, an open source library for scalable in-database analytics. MADlib provides data-parallel implementations of mathematical, statistical, and machine learning methods for structured and unstructured data. You can use Tanzu Greenplum text to perform a variety of MADlib analyses.
Learn more about Apache MADlib at http://madlib.apache.org. A gppkg package for MADlib is available on VMware network at http://network.pivotal.io.
The Apache OpenNLP toolkit provides advanced machine learning tools for tokenizing, recognizing, and tagging natural language text that you can enable for Tanzu Greenplum text indexing and searching. See Natural Language Processing with Tanzu Greenplum text Indexes for more information.
