









Once the Greenplum cluster is up and running, the ESXi hosts will need maintenance from time to time. VMware vSphere features a maintenance mode supported by the ESXi hosts for such planned downtime.
In order to ensure that the Greenplum cluster service is not interrupted during the planned maintenance time, and that the maintenance window can fit into your SLA requirements, there are some settings you must specify when putting a host into maintenance mode:
The Data Evacuation mode, or vSAN Data Migration mode, must be set to Ensure accessibility. This is the default mode and it ensures that all accessible master hosts and segment hosts running on the host that is going down for maintenance remain accessible.
The checkbox Move powered-off and suspended virtual machines to other hosts in the cluster must be enabled, so any powered-off virtual machines can still be available during the maintenance window if needed.
Bringing the ESXi Host Down
In the VMware vSphere Client home page, navigate to Home > Hosts and Clusters and select your host.
Right-click the host and select Maintenance Mode > Enter Maintenance Mode.
By default, the check box Move powered-off and suspended virtual machines to other hosts will be enabled. Make sure it stays enabled.
Click the drop down menu next to vSAN Data Migration and select Ensure Accessibility.
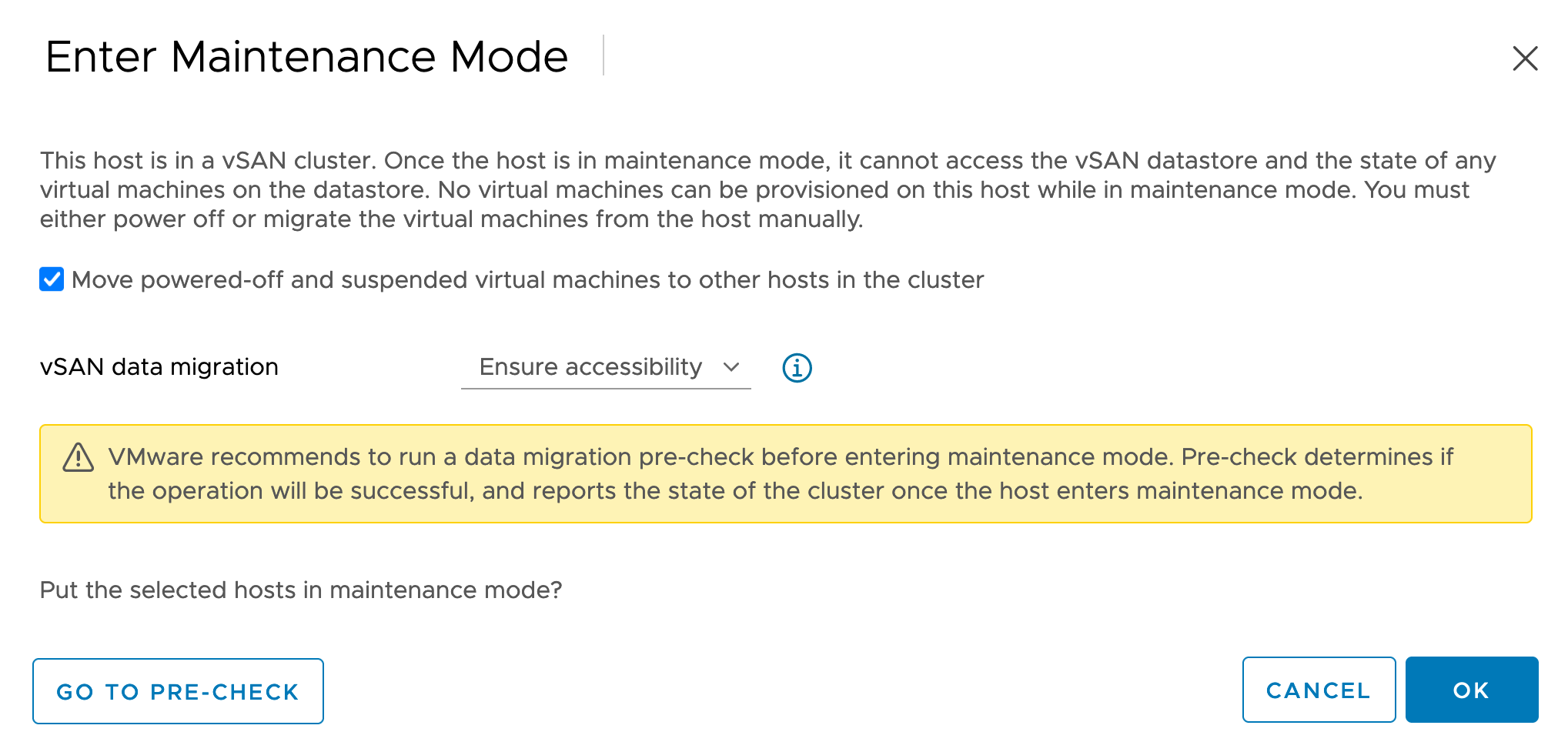
In the confirmation dialog box, click OK.
The above steps ensure that the entire maintenance process is transparent to the Greenplum workloads.
Bringing the ESXi Host Back Up
In order to bring the host back from maintenance mode, simply right click on the host, select Maintenance Mode, then Exit maintenance mode.
Performance Impact of Host Maintenance
The impact will depend on the overall load on the VMware vSphere cluster. Assuming that you have followed the High Availability guidelines, and N being the number of ESXi hosts:
- There will be a bandwidth reduction of
1/Nfor the Greenplum internal networksgp-virtual-internal, andgp-virtual-etl-bar. - The vSAN storage capacity will be reduced by
1/N, however this will not impact Greenplum storage capacity, as both the master hosts and segment hosts disks are thick provisioned. - Since VMware vSphere HA reserved
1/Nof the compute resources, the cluster will not be affected by compute resource degradation. For example, for a 4 node cluster with 96 vcores on each host, each host reserves 24 vcores and uses 72 vcores. When a single ESXi host goes down, the 72 reserved vcores will replace the capacity of the downed host. - Since you configured your environment with Failures To Tolerate (FTT) set to 1, if you bring one host down on maintenance mode, the FTT will be 0, so if another host goes down this will result in service interruption.
