









Distributed Resource Scheduler (DRS) is responsible for moving virtual machines across ESXi hosts using VMware vSphere vMotion and following a given policy, based on VMware vSphere Anti-Affinity rules. The VMware vSphere Anti-Affinity rules for this reference architecture are configured as part of the automated deployment. The same rules will apply for the Greenplum master and standby master.
High Availability (HA) is responsible for restarting virtual machines on other VMware vSphere hosts in the cluster without manual intervention when a host outage is detected.
Combined, the two features ensure that the Greenplum Database cluster keeps running in case of an ESXi host outage. See Managing Single Host Failures in Dell EMC VxRail for more information.
Enabling DRS
On the VMware vSphere Client Home page, navigate to vCenter → Select your Cluster → Configure → Services → vSphere DRS.
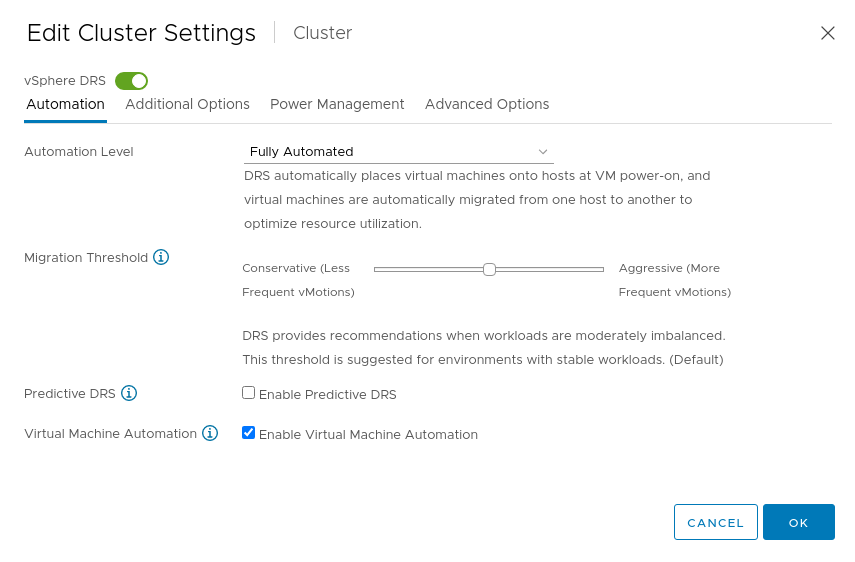
Click the Edit button and enable VMware vSphere DRS, then configure the following settings:
- Automation
- Automation Level: Fully Automated
- Migration Threshold: Default
- Predictive DRS: Disabled
- Virtual Machine Automation: Enabled
- Additional Options
- VM Distribution: Disabled
- CPU Over-Commitment: not configured
- Scalable Shares: Disabled
- Power Management
- DPM : Off
- Automation Level: Off
- DPM Threshold: Disabled
- Advanced Options:
- None
Enabling HA
On the VMware vSphere Client Home page, navigate to vCenter → Select your Cluster → Configure → Services → vSphere Availability.
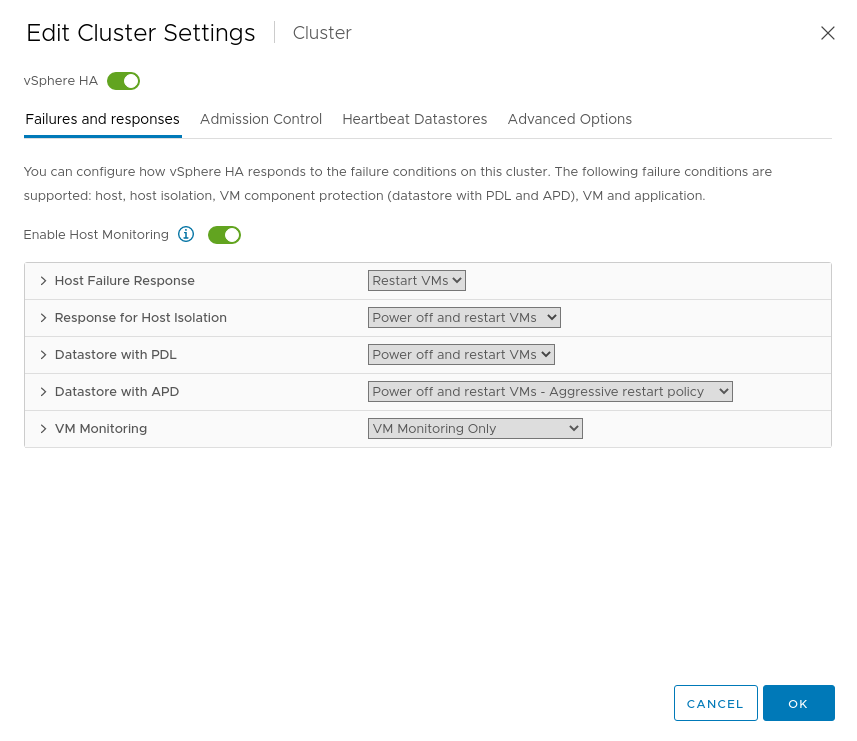
Click the Edit button and enable VMware vSphere HA, then configure the following settings:
- Failures and Responses
- Enable Host Monitoring: On
- Host Failure Response:
- Failure Response: Restart VMs
- Default VM restart priority: Medium
- VM dependency restart condition: Resources allocated
- Additional delay: 0 seconds
- VM restart priority condition timeout: 600 seconds
- Response for Host Isolation: Power off and restart VMs
- Datastore with PDL: Power off and restart VMs
- Datastore with APD: Power off and restart VMs - Aggressive restart policy
- Response recovery: Reset VMs
- Response delay: 3 minutes
- VM Monitoring: VM Monitoring Only
- VM monitoring sensitivity: Custom
- Failure interval: 30 seconds
- Minimum uptime: 120 seconds
- Maximum per-VM resets: 3
- Maximum resets time window: No window
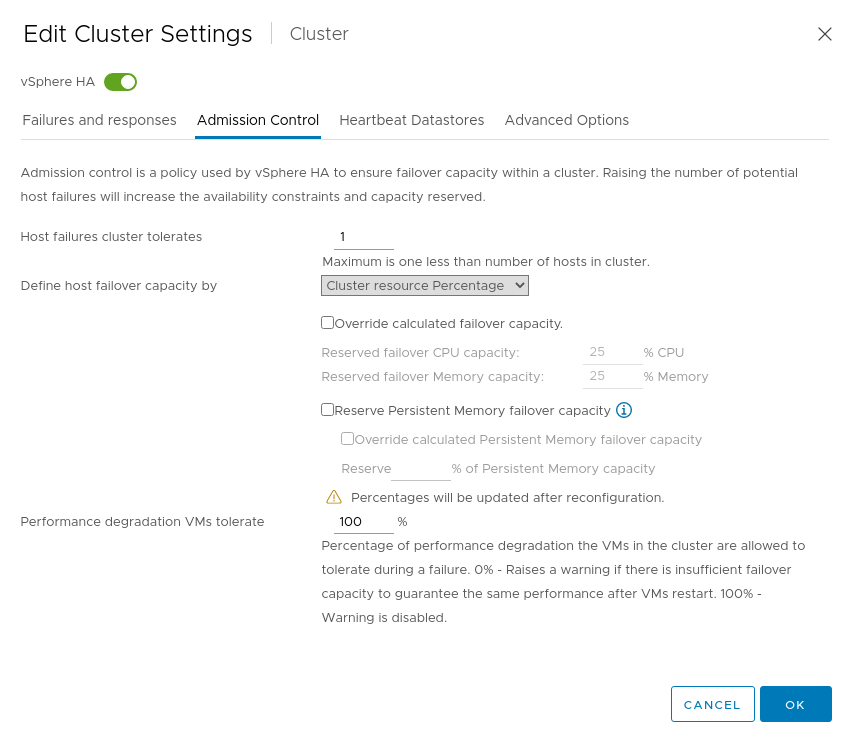
- Admission Control
- Host failures cluster tolerates: 1
- Define host failover capacity by: Cluster resource Percentage
- Performance degradation VMs tolerate: 100%
Heartbeat Datastores
- Automatically select datastores accessible from the hosts
Advanced Options
- None
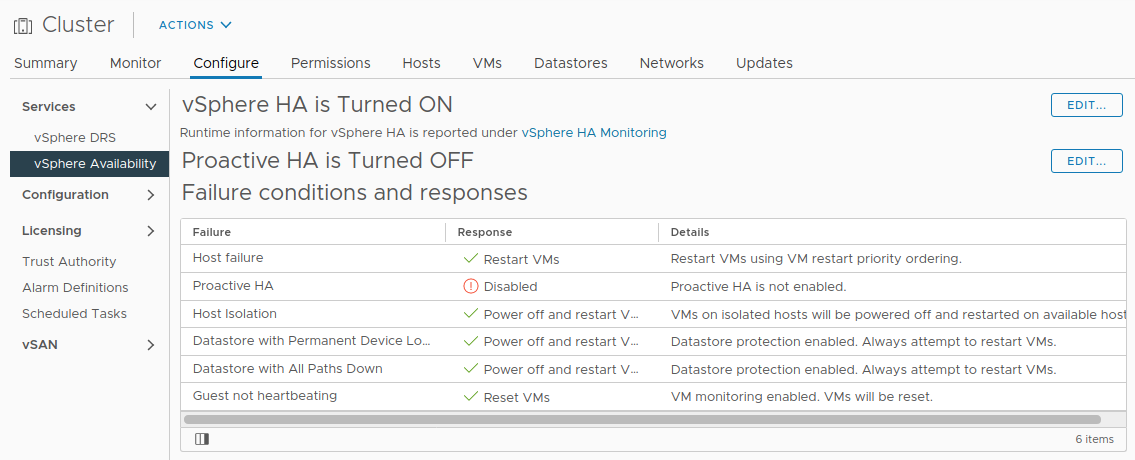
Make sure that Proactive HA is turned OFF.
Next Steps
- If you are not planning on using encryption for your VMware Greenplum on vSphere environment, proceed to Setting Up VMware vSphere Storage to configure the VMware vSphere storage policies.
- Visit Setting Up VMware vSphere Encryption in order to explore the different encryption options and set up the chosen type of encryption and its corresponding storage policies.
