









The VMware Integrated OpenStack CLI health check runbook covers the viocli check health cases and procedures for fixing the reported issues.
You can run any of the following solutions for the reported issues in viocli check health:
Node not Ready
- To get the node status, run the
osctl get nodecommand.osctl get node NAME STATUS ROLES AGE VERSION controller-dqpzc8r69w Ready openstack-control-plane 17d v1.17.2+vmware.1 controller-lqb7xjgm9r Ready openstack-control-plane 17d v1.17.2+vmware.1 controller-mvn5nmdrsp Ready openstack-control-plane 17d v1.17.2+vmware.1 vxlan-vm-111-161.vio-mgmt.eng.vmware.com Ready master 17d v1.17.2+vmware.1
- Restart the kubelet service on the
not ready nodewith the following command:viosshcmd ${not_ready_node} 'sudo systemctl restart kubelet' - To recheck status of this issue, run
viocli check health -n kubernetes.
Node with Duplicate IP Address
For more information on node with duplicate IP address, see KB 82608.
To recheck the status of this issue, run viocli check health -n kubernetes.
Node Unhealthy
- Run
osctl describe node <node>to get the health status of the node.Type Status LastHeartbeatTime LastTransitionTime Reason Message ---- ------ ----------------- ------------------ ------ ------- NetworkUnavailable False Sat, 05 Jun 2021 10:47:53 +0000 Sat, 05 Jun 2021 10:47:53 +0000 CalicoIsUp Calico is running on this node MemoryPressure False Mon, 07 Jun 2021 01:21:55 +0000 Mon, 07 Jun 2021 00:57:29 +0000 KubeletHasSufficientMemory kubelet has sufficient memory available DiskPressure False Mon, 07 Jun 2021 01:21:55 +0000 Mon, 07 Jun 2021 00:57:29 +0000 KubeletHasNoDiskPressure kubelet has no disk pressure PIDPressure False Mon, 07 Jun 2021 01:21:55 +0000 Mon, 07 Jun 2021 00:57:29 +0000 KubeletHasSufficientPID kubelet has sufficient PID available Ready True Mon, 07 Jun 2021 01:21:55 +0000 Mon, 07 Jun 2021 00:57:32 +0000 KubeletReady kubelet is posting ready status
- If
NetworkUnavailable,MemoryPressure,DiskPressure, orPIDPressurestatus is true, Kubernetes node is in unhealthy status. So, you must check the system status and resource usage of the unhealthy node. - To recheck the status of this issue, run
viocli check health -n kubernetes.
Node with High Disk Usage
- Login to the node which reports high disk use.
#viossh ${node} - Check disk usage with
df -h. - Remove unused files on the node.
- To recheck the status of this issue, run
viocli check health -n kubernetes.
Evicted, please contact VMware Support to rescue.
- Login to the node with the high inode use.
#viossh ${node} - Check the inode use with
df -i /. - Remove unused files on the node.
- To recheck the status of this issue, run
viocli check health -n kubernetes.
Node with Snapshot
- Login to the vCenter and remove the snapshots taken for the VMware Integrated OpenStack controller nodes.
- If it reports an error fail to connect to vCenter, you must check the vCenter connection information in VMware Integrated OpenStack.
- To recheck the status of this issue, run
viocli check health -n kubernetes.
Cannot Resolve FQDN
- From the VMware Integrated OpenStack management node, check the DNS resolution with the following commands:
#viosshcmd ${node_name} -c "nslookup ${reported_host}" #toolbox -c "dig $host +noedns +tcp" - If failed, check the DNS server configured in the VMware Integrated OpenStack node /etc/resolve.conf.
- To recheck the status of this issue, run
viocli check health -n connectivity.
NTP not Synced in Node
For more information on NTP node, see KB 78565. To recheck the status of this issue, run viocli check health -n connectivity.
LDAP Unreachable
Check the connection from VMware Integrated OpenStack nodes to the specified LDAP server and ensure the LDAP (user, credentials) setting in VMware Integrated OpenStack is correct. To recheck the status of this issue, run viocli check health -n connectivity.
vCenter Unreachable
For vCenter unreachable, check the connection from VMware Integrated OpenStack nodes to the specified vCenter and ensure the vCenter setting (user, credentials) in VMware Integrated OpenStack is correct. To recheck the status of this issue, run viocli check health -n connectivity.
NSX Unreachable
For NSX unreachable, check the connection from VMware Integrated OpenStack nodes to the specified NSX server and ensure the NSX setting (user, credentials) is correct. To recheck the status of this issue, run viocli check health -n connectivity.
- You must have all prerequisites listed in the Integrate VMware Integrated OpenStack with vRealize Log Insight document ready.
- To recheck the status of this issue, run
viocli check health -n connectivity.
- Ensure that the DNS server can communicate with the VMware Integrated OpenStack API access network.
- You must have all the prerequisites listed in Enable the Designate Component document ready.
- To recheck the status of this issue, run
viocli check health -n connectivity.
Incorrect Network Partition in rabbitmq Node
- To force recreate the
rabbitmqnode, run on VMware Integrated OpenStack management node.#osctl delete pod ${reported_rabbitmq_node} - To recheck the status of this issue, run
viocli heath check -n rabbitmq.
WSREP Cluster Issue
viocli get deployment is Running, please contact VIO support. Otherwise, follow the instructions below.
- Run the following command from VMware Integrated OpenStack manager node:
#kubectl -n openstack exec -ti mariadb-server-0 -- mysql --defaults-file=/etc/mysql/admin_user.cnf --connect-timeout=5 --host=localhost -B -N -e "show status;" #kubectl -n openstack exec -ti mariadb-server-1 -- mysql --defaults-file=/etc/mysql/admin_user.cnf --connect-timeout=5 --host=localhost -B -N -e "show status;" #kubectl -n openstack exec -ti mariadb-server-2 -- mysql --defaults-file=/etc/mysql/admin_user.cnf --connect-timeout=5 --host=localhost -B -N -e "show status;"
- If the output
wsrep_cluster_sizeofmariadb-server-xis not 3, then recreate themariadbnode with:#kubectl -n openstack delete pod mariadb-server-x
- If a big gap of
wsrep_last_commitedis seen among the three nodes, then restart themariadbnode or nodes with a smaller number withwsrep_last_committed.#kubectl -n openstack delete pod mariadb-server-x
- To recheck the status of this issue, run
viocli check health -n mariadb.
Big Tables in OpenStack Database
nova.instancesRefer to KB 83768.
glance.imagesThere are cron jobs enabled by default to auto purge soft-deleted records in glance database.
Please check if db purge cron job is enabled and running properly.
viocli update glance jobs: db_purge: age_in_days: 60 max_rows: 1000 db_purge_images: age_in_days: 60 max_rows: 1000 manifests: cron_job_db_purge: true cron_job_db_purge_images: truecron_job_db_purgeis used to enable the db purge for glance table except the 'image' table.cron_job_db_purge_imagesis used to enable the db purge for glance 'image' table.--age_in_days NUMonly purge rows that have been deleted for longer than NUM days. The default is 30 days.--max_rows NUMpurge a maximum of NUM rows from each table. The default is 100.cinder.volumesandcinder.volume_attachmentManual steps to purge Cinder Database
- Backup Cinder db.
osctl exec -ti mariadb-server-0 -- mysqldump --defaults-file=/etc/mysql/admin_user.cnf -R cinder > /tmp/cinder_backup.sql
- Login to cinder-api-xxxxx pod.
osctl exec -ti deploy/cinder-api bash
- Clean up Cinder database.
cinder-manage db purge 60
Note:command usage: cinder-manage db purge
age_in_days.positional arguments:
age_in_daysPurge deleted rows older than age in days.You may need to adjust
age_in_daysto clean more soft-deleted records in Cinder database.
Too Many Legacy Network Resources in Control Plane
For solution, see Fail to enable ceilometer when there are 10k neutron tenant networks in VMware Integrated OpenStack 7.1 Release Notes.
OpenStack Keystone not Working Properly
- You must try to login to OpenStack from toolbox as the admin user and try to run the commands such as
openstack user listandopenstack user show. If the login fails, collect and check Keystone logs for error messages. - Get the list of keystone-api pod:
#osctl get pod | grep keystone-api
- Collect the logs:
#osctl logs keystone-api-xxxx -c keystone-api >keystone-api-xxxx.log
- To check the status of this issue, run
viocli check health -n keystone.
Empty Network ID in Neutron Database
For solution, see KB 76455. To check the status of this issue, run viocli check health -n neutron.
Wrong vCenter Reference in Neutron
- Get
vioclustername.Ifosctl get viocluster
viocluster1is returned, continue to the next step. Otherwise, this is a false alarm. Contact VMware Support for a permanent solution. - Get
vioclustervCenter configuration.# osctl get viocluster viocluster1 -oyaml
- Backup Neutron configuration.
osctl get neutron -oyaml > neutron-<time-now>.yml
- Edit Neutron CR
cmd:osctl edit neutron neutron-xxxand then change CR spec by replacing vCenter reference found in step 1.spec: conf: plugins: nsx: dvs: dvs_name: vio-dvs host_ip: .VCenter:vcenter812:spec.hostname <---- change the vcenter instance to viocluster refered host_password: .VCenter:vcenter812:spec.password <---- same above host_username: .VCenter:vcenter812:spec.username <---- insecure: .VCenter:vcenter812:spec.insecure <---- - To check the status of this issue, run
viocli check health -n neutron.
- Get the Nova pod.
osctl get pod | grep nova
Check if the Nova pod is not in Running status.
- Delete the pod with:
osctl delete pod xxx.Wait for the new pod until its status is Running.
- To check the status of this issue, run
viocli check health -n nova.
Stale Nova Service
For stale Nova service, see KB 78736. To check the status of this issue, run viocli check health -n nova.
- Login to the toolbox and try to find and delete the redundant Nova service and some Nova service without endpoints.
# openstack catalog list

# openstack service list

- Find out the Nova service in use.
# openstack endpoint list |grep nova
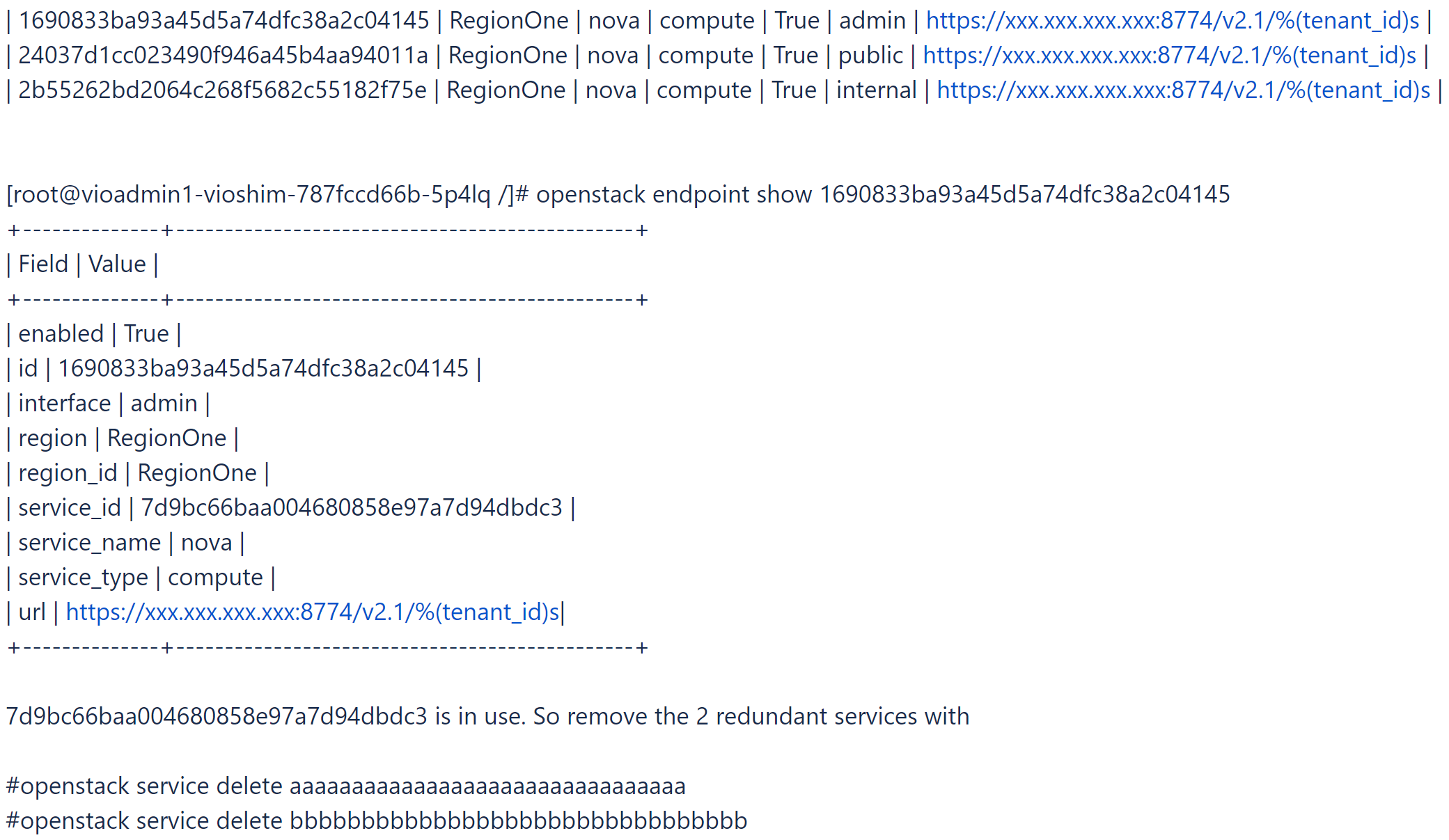
- To check the status of this issue, run
viocli check health -n nova.
Some Nova Compute Pods Keep Restarting Due To Startup Timeout
This alarm indicates that some nova compute pods may be under unhealthy state. Please contact VMware support for solution. To check the status of the issue, run viocli check health -n nova.
Glance Datastore Unreachable
- Get Glance service list.
osctl get glance
- Get Glance datastore information.
osctl get glance $glance-xxx -o yaml
- Find datastore connection information.
spec: conf: backends: vmware_backend: vmware_datastores: xxxx vmware_server_host: xxxx vmware_server_password: xxxx vmware_server_username: .xxxx - If the information is incorrect, check vCenter and datastore connection and update it with
osctl update glance $glance-xxxaccordingly. - To check the status of this issue, run
viocli check health -n glance.
Glance Image(s) With Incorrect Location Format
The message indicates that some of glance images are in incorrect location format. Please contact VMware support for solution. To check the status of the issue, run viocli check health -n glance.
Cinder Services Down
- Get the Cinder pod.
osctl get pod | grep cinder | grep -v Completed
Check if the Cinder pod is not in Running status.
- Delete the pod with:
osctl delete pod xxx.Wait for the new pod until its status shows as Running.
- To check the status of this issue, run
viocli check health -n cinder.
- Login in to
cinder-volumepod.#osctl exec -ti cinder-volume-0 bash
- Check and list stale Cinder services.
#cinder-manage service list
For example:#cinder-manage service list
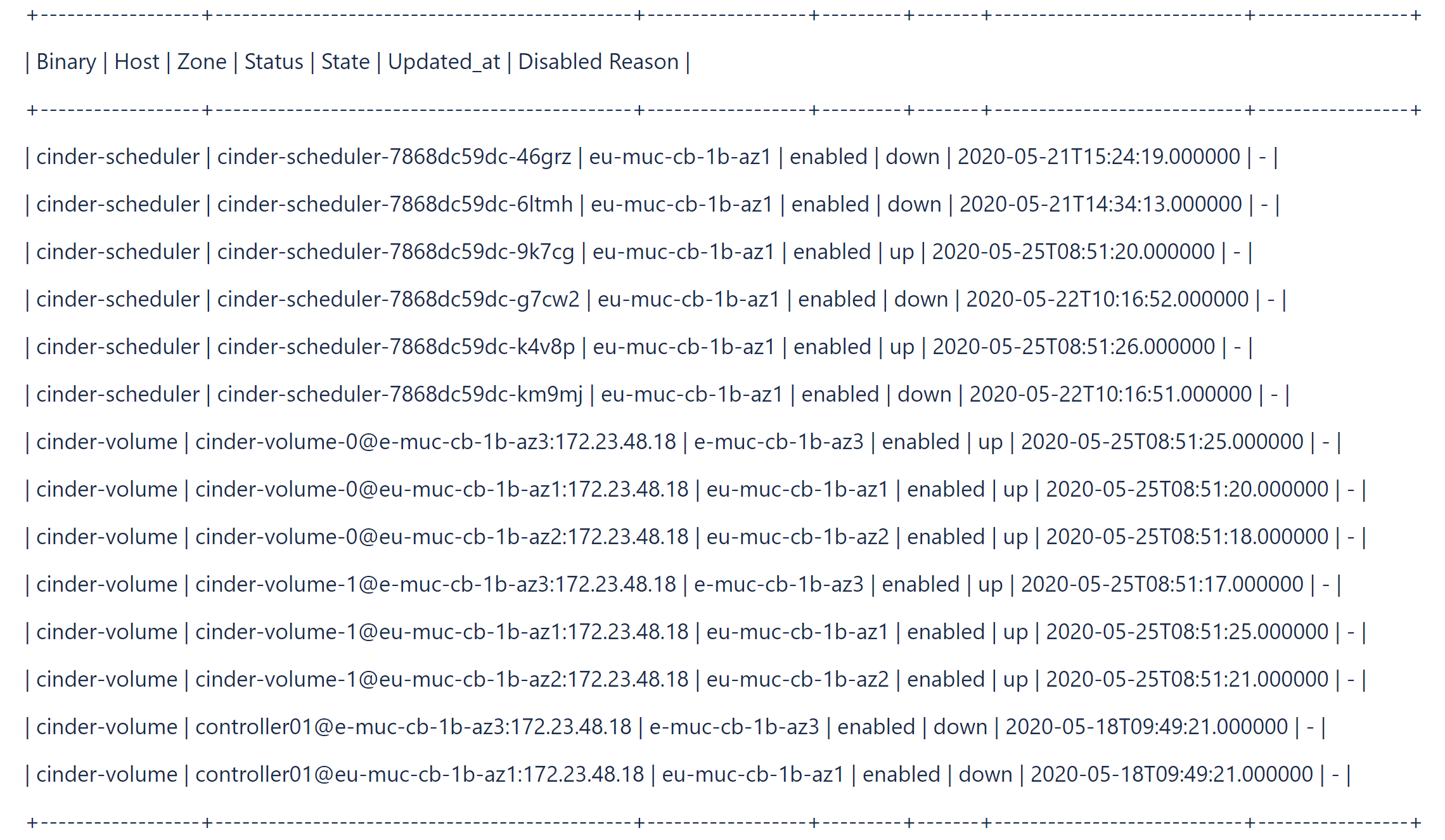
- Get rid of stale Cinder services using
cinder-managecommand incinder-volumepod.# cinder-manage service remove cinder-scheduler cinder-scheduler-7868dc59dc-km9mj # cinder-manage service remove cinder-volume controller01@e-muc-cb-1b-az3:172.23.48.18
- To check the status of this issue, run
viocli check health -n cinder.
- To install the required command in VMware Integrated OpenStack management node, run
tdnf install xxx. - To check the status of this issue, run
viocli check health -n basic.
Empty Kubernetes Node List or Node Unreachable
Run osctl get nodes from VMware Integrated OpenStack management node and check if it can capture the correct output. To check the status of this issue, run viocli check health -n basic.
No Running Pod
Run osctl get pod |grep xxx from VMware Integrated OpenStack management node and check if it can capture any running pod from the output. To check the status of this issue, viocli check health -n basic.
Pod Unreachable
Run osctl exec -it $pod_name bash from VMware Integrated OpenStack management node and check if you can login to the pod. To check the status of this issue, run viocli check health -n basic.
Run Command in Pod
Check log file /var/log/viocli_health_check.log for detail information and try to rerun the command from VMware Integrated OpenStack management node. To check the status of this issue, run viocli check health -n basic.
- Login to the toolbox and run some OpenStack commands, for example,
openstack catalog listand check if the command can capture correct return. - For more message, add the debug option. For example:
openstack catalog list --debug
- To check the status of this issue, run
viocli check health -n basic.
- Get the openstack admin password and compare it with
OS_PASSWORD.osctl get secret keystone-keystone-admin -o jsonpath='{.data.OS_PASSWORD} - If there is no value stored in
keystone-keystone-admin, update it withosctl edit secret keystone-keystone-admin. - To check the status of this issue, run
viocli check health -n basic.
vCenter cluster is overloaded / hosts are under pressure
Check vCenter hosts for VIO control plane and add more resource, or clean up some unused instance to relieve the pressure on resources.
- Check log /var/log/viocli_health_check.log and search the last message for
check_vio_cert_expireto know how long the certificate has been expired or will expire. - To update the cert, follow Update Certificate for VMware Integrated OpenStack.
- To recheck the status of the issue, run
viocli check health -n connectivity.
LDAP Certificate Expired / Is About To Expire
- Check log /var/log/viocli_health_check.log and search the last message for
check_ldap_cert_expireto know how long the certificate has been expired or will expire. - To update the cert, follow Update Certificate for LDAP Server.
Note: If no LDAP configured, the check will be skipped with log message,
No LDAP Certificate found. - To recheck the status of the issue, run
viocli check health -n connectivity.
vCenter Certificate Expired / Is About To Expire
- Check log /var/log/viocli_health_check.log and search the last message for
check_vcenter_cert_expireto know how long the certificate has been expired or will expire. - To update the cert, follow Configuring VMware Integrated OpenStack with Updated vCenter or NSX-T Certificate.
Note: If the vcenter is configured to use insecure connection, the check will be skipped with log message,
Use insecure connection. - To recheck the status of the issue, run
viocli check health -n connectivity.
NSX Certificate Expired/Is About To Expire
- Check log /var/log/viocli_health_check.log and search the last message for
check_nsx_cert_expireto know how long the certificate has been expired or will expire. - To update the cert, follow Configuring VMware Integrated OpenStack with Updated vCenter or NSX-T Certificate.
Note: If the NSX is configured to use insecure connection, the check will be skipped with log message,
Use insecure connection. - To recheck the status of the issue, run
viocli check health -n connectivity.
Service xxx Stopped
Run viocli start xxx to start the service. To check the status of this issue, run viocli check health -n lifecycle_manager.
- Check log /var/log/viocli_health_check.log and search the last message for
check_cluster_workload, which provides detailed resource usage. - Fix reported resource issues and then recheck status by running
viocli check health -n kubernetes.
