









This section explains how high availability (HA) operates within NSX Advanced Load Balancer Controller cluster.
Quorum
The Controller level HA requires a quorum of NSX Advanced Load Balancer Controller nodes to be up. In a three-node Controller cluster, quorum can be maintained if at least two of the three Controller nodes are up. If one of the Controllers fail, the remaining two nodes continues service and NSX Advanced Load Balancer continues to operate. However, if two of the three nodes go down, then the entire cluster goes down, and NSX Advanced Load Balancer stops working.
Failover
Each Controller node in a cluster periodically sends heartbeat messages to the other Controller nodes in a cluster, through an encrypted SSH tunnel using TCP port 22 (port 5098 if running as Docker containers).
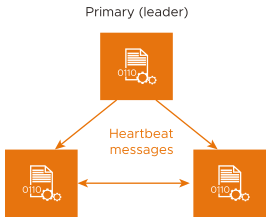
The heartbeat interval is ten seconds. The maximum number of consecutive heartbeat messages that can be missed is four. If one of the Controllers does not hear from another Controller for 40 seconds (four missed heartbeats), then the other Controller is assumed to be down.
If only one node is down, then the quorum is still maintained and the cluster can continue to operate.
If a follower node goes down but the primary (leader) node remains up, then the access to virtual services continues without any interruption.
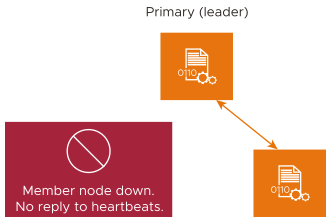
If the primary (leader) node becomes unavailable because of events such as a hardware failure or a snapshot of the leader node VM being taken, the member nodes will form a new quorum and elect a cluster leader. The election process takes about 50-60 seconds and during this period, there is no impact on the data plane. The SEs will continue to operate in the Headless mode, but the control plane service will not be available. During this period, you cannot create a VIP through LBaaS or use the NSX Advanced Load Balancer user interface, API, or CLI.

