









Pools maintain the list of servers assigned to them and perform health monitoring, load balancing, persistence, and functions that involve NSX Advanced Load Balancer-to-server interaction. This topic explains the different features of server pools in NSX Advanced Load Balancer including pool analytics, logs, health, events, alerts, and more.
A typical virtual service will point to one pool. However, more advanced configurations may have a virtual service content switching across multiple pools through HTTP Request Policies or DataScripts.
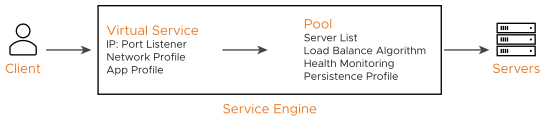
Creating a virtual service using the basic method automatically creates a new pool for that virtual service, using the name of the virtual service with a -pool appended. When creating a virtual service through the advanced mode, an existing pool may be specified, or a new pool may be created.
Pools
Navigate to to open the pools page. This page displays a high-level overview of configured pools.
Field |
Description |
|---|---|
Name |
Displays the name of each pool. Clicking the name opens the Analytics tab of the Pool Details page. |
Health |
Displays the health using both a number from 1-100 and a color-coded status to provide quick information about the health of each pool. This will be gray if the pool is unused, such as not associated with a virtual service or associated with a VS that can not or has not been placed on a Service Engine.
|
Virtual Service |
Displays the virtual service the pool is assigned to. Clicking a name in this column opens the virtual service Analytics tab of the Virtual Service Details page. If no virtual service is listed, this pool is considered unused. |
Servers (Up/Total) |
Displays the number of servers in the pool that are up out of the total number of servers assigned to the pool. For instance, 2/3 indicates that two of the three servers in the pool are successfully passing health checks and are considered up. Clicking on it opens the Servers tab of the Pool Details page. |
Cloud |
Displays the relevant cloud. |
RPS |
Displays the performance of the CPU. Hovering the mouse pointer over the RPS (Requests per second) value opens the RPS score popup. |
Open Conns |
Displays the open connections of the respective pool. Hovering the mouse pointer over the Open connections value opens the popup. |
Throughput |
Displays the thumbnail chart of the throughput in Mbps for each pool for the time frame selected. Hovering the mouse pointer over this graph shows the throughput at the selected time. Clicking a graph opens the Analytics tab of the Pool’s Details page. |
