









A flow is a 5-tuple, such as, src-IP, src-port, dst-IP, dst-port, and protocol. Routers do a hash of the 5-tuple to pick which equal-cost path to use.
Flow Resiliency during Scale-Out/ In
When an SE scale-out occurs, the router is given yet another path to use, and its hashing algorithm can make different choices, as a result disrupting existing flows. To gracefully cope with this BGP-based scale-out issue, NSX Advanced Load Balancer supports resilient flow handling using IP-in-IP (IPIP) tunneling. The following sequence shows how this is done.
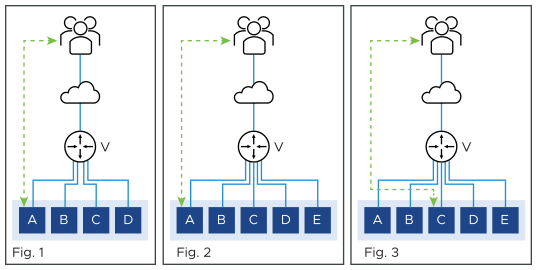
Figure 1 shows the virtual service placed on four SEs, with a flow ongoing between a client and SE-A. In figure 2, there is a scale-out to SE-E. This changes the hash on the router. Existing flows get rehashed to other SEs. In this particular example, it is SE-C.
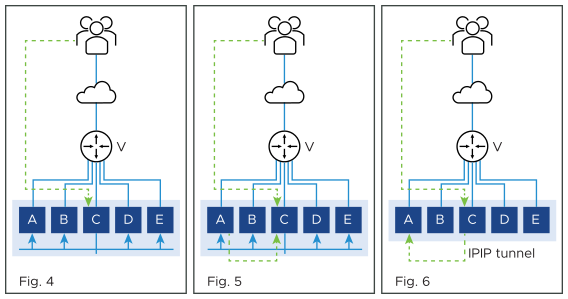
In the NSX Advanced Load Balancer implementation, SE-C sends a flow probe to all other SEs (figure 4). Figure 5 shows SE-A responding to claim ownership of the depicted flow. In figure 6, SE-C uses IPIP tunneling to send all packets of this flow to SE-A.
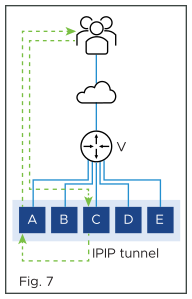
In figure 7, SE-A continues to process the flow and sends its response directly to the client.
Flow Resiliency for Multi-homed BGP Virtual Service
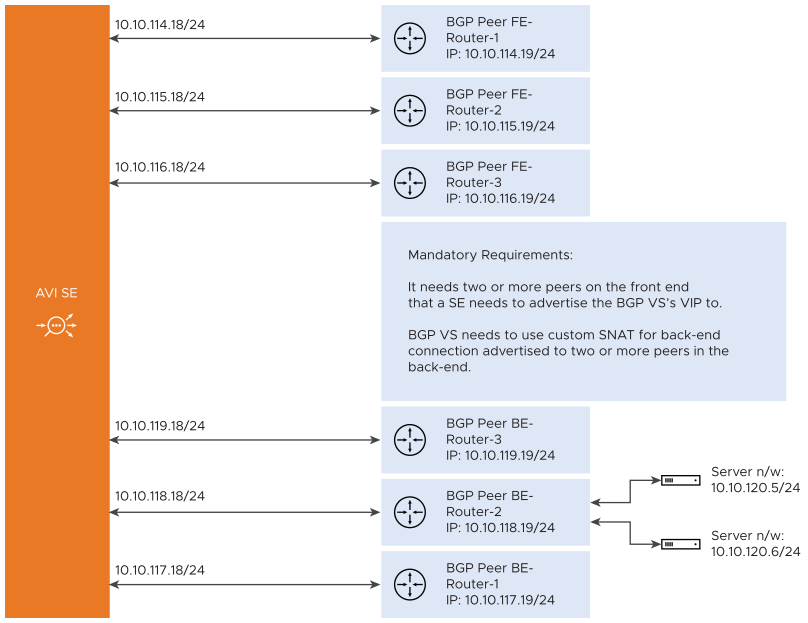
The flow resiliency is supported when there is a BGP virtual service that is configured to advertise its VIP to more than one peer in the frontend and is configured to advertise SNAT IP associated with virtual service to more than one peer in the backend.
In such a setup, when one of the links goes down, the BGP withdraws the routes from that particular NIC causing rehashing of that flow to another interface on the same SE or to another SE. The new SE that receives the flow tries to recover the flow with a flow probe which fails because of the interface going down.
The problem is seen with both the frontend and the backend flows.
For the frontend flows to be recovered, the flow must belong to a BGP virtual service that is placed on more than one NIC on a Service Engine.
For the backend flows to be recovered, the virtual service must be configured with SNAT IPs and must be advertised through BGP to multiple peers in the backend.
Recovering Frontend Flows
- Flow recovery within the same SE:
-
If the interface goes down, the FT entries are not deleted. If the flow lands on another interface, the flow-probe is triggered which is going to migrate the flow from the old flow table to the new interface where the flow is landed.
The interface down event is reported to the Controller and the Controller removes the VIP placement from the interface. This causes the primary virtual service entry to be reset. If the same flow now lands on a new interface, it triggers a flow-probe, flow-migration if the virtual service was placed initially on more than one interface.
- Flow recovery on a scaled-out SE:
-
If the flow lands on a new SE, the remote flow-probes are triggered. A new flag called Relay will be added to the flow-probe message. This flag indicates that all the receiving interfaces need to relay the flow-probes to other flow-tables where the flow can be there. The flag is set at the sender of the flow-probe when the virtual service is detected as BGP scaled-out virtual service.
On the receiving SE, the messages are relayed to the other flow tables resulting in a flow migration. So subsequent flow-probe from the new SE is going to earn a response because the flow now resides on the interface that is up and running.
If there is more than one interface on the flow-probe receiving SE, they will all trigger a flow-migrate.
Recovering Backend Flows
The backend flows can be migrated only if the SNAT IP is used for the backend connection. When multiple BGP peers are configured on the back end, and the servers are reachable through more than one route, SNAT IP is placed on all the interfaces. Also, the flow table entries are created on all the interfaces in the back end.
This result in the flow getting recovered in case an interface fails, and the flow lands on another interface with flow table entry.
