This section describes about Elastic HA for NSX Advanced Load Balancer SEs.
High Availability Modes
NSX Advanced Load Balancer supports two SE elastic HA modes which combine scale-out performance as well as high availability:
N+M mode (the default)
Active/Active
NSX Advanced Load Balancer also provides a third mode, legacy HA mode, which enables a smooth migration from legacy appliance-based load balancers.
Elastic HA N+M Mode
N+M is the default mode for elastic HA.
In this mode, each virtual service is typically placed on just one SE.
The “N” in “N+M” is the minimum number of SEs required to place virtual services in the SE group — this calculation is done by the NSX Advanced Load Balancer Controller based on Virtual Services per Service Engine parameter. N will vary over time, as virtual services are placed on or removed from the group.
The “M”of “N+M” is the number of additional SEs the Controller spins up to handle up to M SE failures without reducing the capacity of the SE group. M appears in Buffer Service Engines field.
The buffer SE in N+M mode is the number of SE failures the system can tolerate for the Virtual Service to be operationally up (placed on at least 1 SE), but not to be at the same capacity. If there is specific minimum scale per Virtual Service set in the SE Group and if additional SE is required above that, then you should increase the buffer SE according to the calculations.
Elastic HA N+M Example
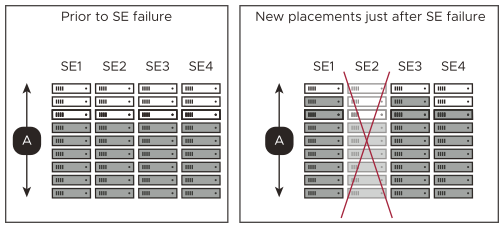
The left side of figure 2 shows 20 virtual service placements on an SE group. With Virtual Services per SE set to 8, N is 3 (20/8 = 2.5, which rounds to 3). With M = 1, a total of N+M = 3 + 1 = 4 SEs are required in the group 2.
No single SE in the group is completely idle. The Controller places virtual services on all available SEs. In N+M mode, the NSX Advanced Load Balancer ensures enough buffer capacity exists in aggregate to handle one (M=1) SE failure. In this example, each of the four SEs has five virtual services placed. A total of 12 spare slots are still available for additional virtual service placements, which is sufficient to handle one SE failure.
The right side of the figure below shows the SE group just after SE2 has failed. The five virtual services in SE2 have been placed onto spare slots found on surviving SEs: SE1, SE3, and S4.
The imbalance in loading disappears over time if one or both of two things happens:
New virtual services are placed on the group. As many as 4 virtual services could be placed without compromising the M=1 condition. They would be placed on SE5 because NSX Advanced Load Balancer chooses the least-loaded SE first.
The Auto-Rebalance option is selected (As shown in the above image).
With M set to 1, the SE group is single-SE fault tolerant. Customers desiring multiple-SE fault tolerance set M higher. NSX Advanced Load Balancer permits M to be dynamically increased by the administrator without interrupting any services. Consequently, one may start with M=1 (typical of most N+M deployments), and increase it if conditions warrant.
If an N+M group has scaled out to Max Number of Service Engines and N x Virtual Services per SE have been placed, NSX Advanced Load Balancer will permit additional VS placements (into the spare capacity represented by M), but an HA_COMPROMISED event will be logged.
For a Write Access cloud, the NSX Advanced Load Balancer will attempt to recover the failed SE after five minutes by rebooting the virtual machine. After a further five minutes, the NSX Advanced Load Balancer will attempt to delete the failed SE virtual machine after which a new SE will be spun up to restore the configured buffer capacity.
As shown in above, with only 4 slots remaining just after the 5 re-placements, if NSX Advanced Load Balancer orchestrator mode is set to write access, NSX Advanced Load Balancer spins up SE5 to meet the M=1 condition, which in this case requires at least 8 slots available for re-placements.
To provide time to identify the cause of a failure, the first SE that fails in an SE group is not automatically deleted even after five minutes. You can then perform troubleshooting on the failed SE and delete the virtual machine manually if restoration is not possible. The Controller will delete the SE virtual machine after 3 days if you have not manually deleted the same.
Elastic HA Active/Active
In active/active mode, NSX Advanced Load Balancer places each virtual service on more than one SE, as specified by “Minimum Scale per Virtual Service” parameter — the default minimum is 2. If an SE in the group fails, then
Virtual services that had been running are not interrupted. They continue to run on other SEs with degraded capacity until they can be placed once again.
If NSX Advanced Load Balancer’s orchestrator mode is set to write access, a new SE is automatically deployed to bring the SE group back to its previous capacity. After waiting for the new SE to spin up, the Controller places on it the virtual services that had been running on the failed SE.
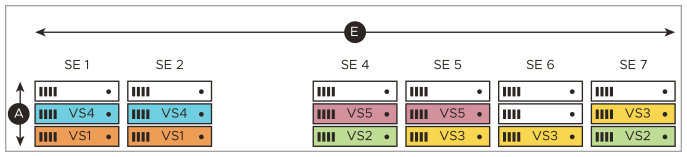
Elastic HA Active/Active Example
The following illustrations explain an SE failure and full recovery:
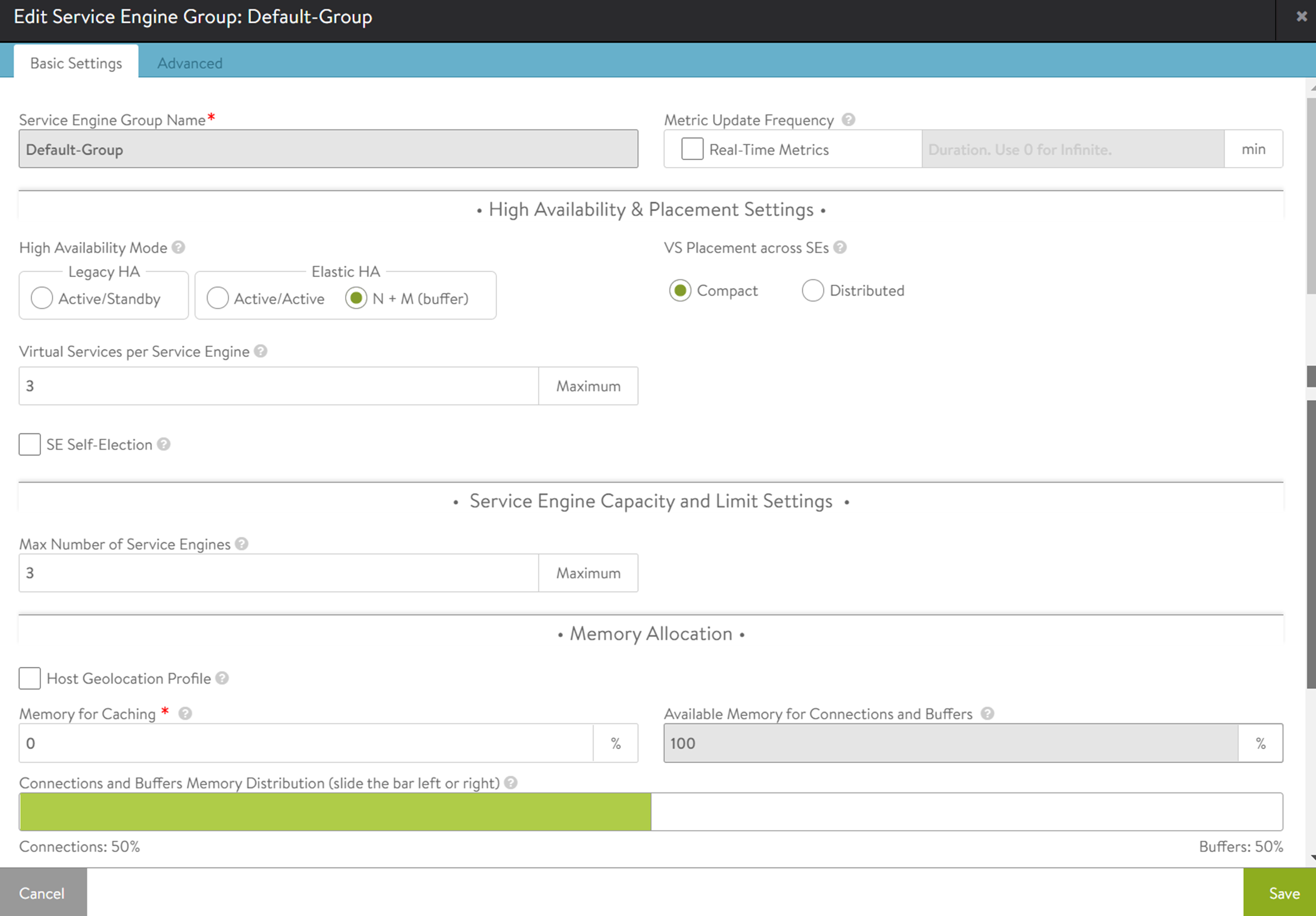
Virtual Services per Service Engine
Minimum Scale per Virtual Service
Maximum Scale per Virtual Service
Max Number of Services Engines
Over time, five virtual services (VS1-VS5) have been placed. One of them, VS3, has been scaled from its initial two placements to three, illustrating NSX Advanced Load Balancer’s support for “N-way active” virtual services.
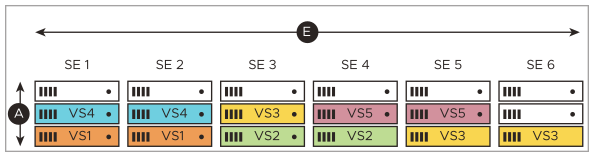
SE3 fails in the below image as a result, one of two VS2 instances fails and one of three VS3 instances fails. Three other virtual services (VS1, VS4, VS5) are unaffected. Neither VS2 nor VS3 are interrupted because of instances previously placed on SE4, SE5, and SE6. They continue, albeit with degraded performance.
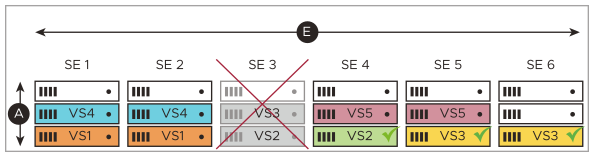
As shown in the below image, the NSX Advanced Load Balancer Controller deploys SE7 as a replacement for SE3, and places VS2 and VS3 on it, bringing both virtual services up to their prior level of performance.