









The NSX Controller cluster represents a scale-out distributed system, where each controller node is assigned a set of roles that define the type of tasks the node can implement. For resiliency and performance, deployments of controller VM should be in three distinct hosts.
Sharding is used to distribute workloads across NSX Controller cluster nodes. Sharding is the action of dividing NSX Controller workloads into different shards so that each NSX Controller instance has an equal portion of the work.
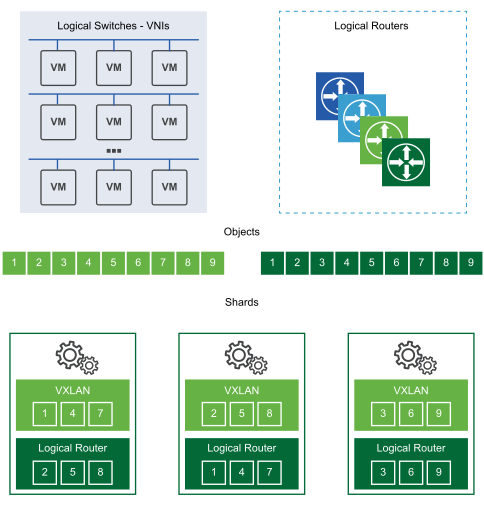
This demonstrates how distinct controller nodes act as master for given entities such as logical switching, logical routing and other services. After a master NSX Controller instance is chosen for a role, that NSX Controller divides the different logical switches and routers among all available NSX Controller instances in a cluster.
Each numbered box on the shard represents shards that the master uses to divide the workloads. The logical switch master divides the logical switches into shards and assigns these shards to different NSX Controller instances. The master for the logical routers also divides the logical routers into shards and assigns these shards to different NSX Controller instances.
These shards are assigned to the different NSX Controller instances in that cluster. The master for a role decides which NSX Controller instances are assigned to which shard. If a request comes in on router shard 3, the shard is told to connect to the third NSX Controller instance. If a request comes in on logical switch shard 2, that request is processed by the second NSX Controller instance.
When one of the NSX Controller instances in a cluster fails, the masters for the roles redistribute the shards to the remaining available clusters. One of the controller nodes is elected as a master for each role. The master is responsible for allocating shards to individual controller nodes, determining when a node has failed, and reallocating the shards to the other nodes. The master also informs the ESXi hosts about the failure of the cluster node.
The election of the master for each role requires a majority vote of all active and inactive nodes in the cluster. This is the primary reason why a controller cluster must always be deployed with an odd number of nodes.
ZooKeeper
ZooKeeper is a client server architecture that is responsible for NSX Controller cluster mechanism. The controller cluster is discovered and created using Zookeeper. When cluster is coming up, it literally means ZooKeeper is coming up between all the nodes. ZooKeeper nodes goes through election process to form the control cluster. There must be a ZooKeeper master node in the cluster. This is done via inter-node election.
When a new controller node is created,NSX Manager propagates the node information to the current cluster, with node IP and ID. As such, each node knows the total number of nodes available for clustering. During ZooKeeper master election, each node casts one vote to elect a master node. The election is triggered again until one node has a majority of the votes. For example, in a three node cluster, the master must have received at least two of the votes.
- When the first controller is deployed, it’s a special case and the first controller becomes master. As such, when deploying controllers, the first node must complete deployment before any other nodes are added.
- When adding the second controller, it’s also a special case, because the number of nodes at this time is even.
- When the third node is added, the cluster reaches a supported stable state.
ZooKeeper can sustain only one failure at a time. This means that if one controller node goes down, it must be recovered before any other failures. Otherwise, there can be problems with the cluster breaking.
Central Control Plane (CCP) Domain Manager
This is the layer above ZooKeeper which provides configuration for ZooKeeper on all nodes to start. Domain manager updates the configuration between all nodes in the cluster, and then makes a remote procedure call for the ZooKeeper process to start.
Domain manager is responsible to start all domains. To join the cluster, CCP domain talks to CCP domain on other machines. The component of CCP domain that helps with cluster initialization is zk-cluster-bootstrap.
Controller Relation with Other Components
The controller cluster is responsible for maintaining and providing information about logical switches, logical routers, and VTEPs to the ESXi hosts.
When a logical switch is created, the controller nodes within the cluster determines which node will be master or owner for that logical switch. The same applies when a logical router is added.
Once ownership is established for a logical switch or logical router, the node sends that ownership to the ESXi hosts that belong to that switch or router’s transport zone. The entire election of ownership and propagation of the ownership information to the hosts is called ‘sharding’. Note that ownership means that node is responsible for all NSX related operations for that logical switch or logical router. The other nodes will not perform any operation for that logical switch.
Because only one owner must be the source of truth for a logical switch and logical router, any time the controller cluster breaks in such a way that two or more nodes are elected as owner for a logical switch or logical router, each host in the network may have a different information regarding the source of truth for that logical switch or logical router. If this happens, there will be network outage because network control and data plane operations can only have one source of truth.
If a controller node goes down, the remaining nodes in the cluster will rerun sharding to determine ownership of the logical switch and logical routing.
