









This section provides an in-depth overview of how the SD-WAN Edge Clustering functionality works.
The following are important concepts that describe the SD-WAN Edge Clustering functionality:
- Edge Clustering can be used on Hubs as follows:
- To allow greater tunnel capacity for a Hub than an individual Edge serving as a Hub can provide.
- To distribute the remote Spoke Edges among multiple Hubs and reduce the impact of any incident that may occur.
- Cluster Score is a mathematical calculation of the overall utilization of the system as follows:
The three measured utilization factors are CPU usage, memory usage, and tunnel capacity.
- Each measure of utilization is treated as a percentage out of a maximum of 100%.
- Tunnel capacity is based on the rated capacity for a given hardware model or Virtual Edge configuration.
- All three utilization percentages are averaged to arrive at an integer-based Cluster Score (1-100).
- While throughput is not directly considered, CPU and memory usage indirectly reflect throughput and flow volume on a given Hub.
- For example, on an Edge 2000:
- CPU usage = 20%
- Memory usage = 30%
- Connected Tunnels = 600 (out of a capacity of 6000) = 10%
- Cluster Score: (20 + 30 + 10)/3 = 20
- A Cluster Score greater than 70 is considered "over capacity."
- A “logical ID” is a 128-bit UUID that uniquely identifies an element inside the VMware Network.
- For instance, each Edge is represented by a logical ID and each Cluster is represented by a logical ID.
- While the user is providing the Edge and Cluster names, the logical IDs are guaranteed to be unique and are used for internal identification of elements.
- By default, the load is evenly distributed among Hubs. Hence, it is necessary that all Edges that are part of a cluster must be of the same model and capacity.
How are Edge Clusters tracked by the VMware SD-WAN Gateway ?
Once a Hub is added to a VMware SD-WAN Cluster, the Hub will tear down and rebuild tunnels to all of its assigned Gateways and indicate to each Gateway that the Hub has been assigned to a Cluster and provide a Cluster logical ID.
- The logical ID
- The name
- Whether Auto Rebalance is activated
- A list of Hub objects for members of the Cluster
For each Hub object in the Cluster, the Gateway tracks:
- The logical ID
- The name
- A set of statistics, updated every 30 seconds via a periodic message sent from the Hub to each assigned Gateway, including:
- Current CPU usage of the Hub
- Current memory usage of the Hub
- Current tunnel count on the Hub
- Current BGP route count on the Hub
- The current computed Cluster Score based on the formula provided above.
A Hub is removed from the list of Hub objects when the Gateway has not received any packets from the Hub Edge for more than seven seconds.
How are Edges assigned to a specific Hub in a Cluster?
In a traditional Hub and Spoke topology, the SD-WAN Orchestrator provides the Edge with the logical ID of the Hub to which it must be connected. The Edge asks its assigned Gateways for connectivity information for that Hub logical ID—i.e. IP addresses and ports, which the Edge will use to connect to that Hub.
From the Edge’s perspective, this behavior is identical when connecting to a Cluster. The Orchestrator informs the Edge that the logical ID of the Hub it should connect to is the Cluster logical ID rather than the individual Hub logical ID. The Edge follows the same procedure of sending a Hub connection request to the Gateways and expects connectivity information in response.
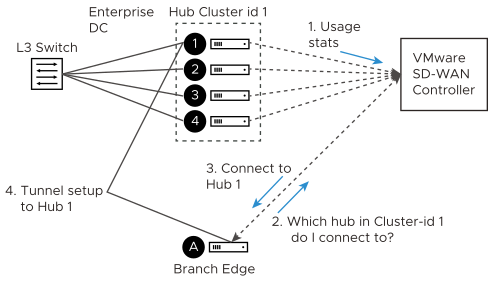
There are two divergences from basic Hub behavior at this point:
- Divergence Number One: The Gateway must choose which Hub to assign.
- Divergence Number Two: Due to Divergence Number One, the Edge may get different assignments from its different Gateways.
Divergence Number One was originally addressed by using the Cluster Score to assign the least loaded Hub in a Cluster to an Edge. While in practice this is logical, in the real world, it turned out to be a less than ideal solution because a typical reassignment event can involve hundreds or even thousands of Edges and the Cluster Score is only updated every 30 seconds. In other words, if Hub 1 has a Cluster Score of 20 and Hub 2 has a Cluster Score of 21, for 30 seconds all Edges would choose Hub 1, at which point it may be overloaded and trigger further reassignments.
Instead, the Gateway first attempts a fair mathematical distribution disregarding the Cluster Score. The Edge logical IDs, which were generated by a secure random-number generator on the Orchestrator, will (given enough Edges) have an even distribution of values. That means that using the logical ID, a fair share distribution can be calculated.
- Edge logical ID modulo the number of Hubs in Cluster = Assigned Hub index
- For example:
- Four Edges that have logical IDs ending in 1, 2, 3, 4
- Cluster with 2 Hubs
- 1 % 2 = 1, 2 % 2 = 0, 3 % 2 = 1, 4 % 2 = 0 (Note: "%” is used to indicate the modulo operator)
- Edges 2 and 4 are assigned Hub Index 0
- Edges 1 and 3 are assigned Hub Index 1

This is more consistent than a round-robin type assignment because it means that Edges will tend to be assigned the same Hub each time, which makes assignment and troubleshooting more predictive.
What happens when a Hub exceeds its maximum allowed tunnel capacity?
The Edge assignment logic will attempt to evenly distribute the Edges between all available Hubs. However, after an event (like restart) on the Hub, the Edge distribution will no longer be even.
Due to such an event on the Hub (or adding additional Edges to the network), Clusters might reach a point where an individual Hub has exceeded 70% of its permitted tunnel capacity. If this happens, and at least one other Hub is at less than 70% tunnel capacity, then fair share redistribution is performed automatically regardless of whether rebalancing is activated on the Orchestrator. Most Edges will retain their existing assignment due to the predictive mathematical assignment using logical IDs, and the Edges that have been assigned to other Hubs due to failovers or previous utilization rebalancing will be rebalanced to ensure the Cluster is returned to an even distribution automatically.
What happens when a Hub exceeds its maximum allowed Cluster Score?
Unlike tunnel percentage (a direct measure of capacity), which can be acted upon immediately, the Cluster Score is only updated every 30 seconds and the Gateway cannot automatically calculate what the adjusted Cluster Score will be after making an Edge reassignment. In the Cluster configuration, an Auto Rebalance parameter is provided to indicate whether the Gateway should dynamically attempt to shift the Edge load for each Hub as needed.
If Auto Rebalance is deactivated and a Hub exceeds a 70 Cluster Score (but not 70% tunnel capacity), then no action is taken.
If Auto Rebalance is activated and one or more Hubs exceed a 70 Cluster Score, the Gateway will reassign one Edge per minute to the Hub with the lowest current Cluster Score until all Hubs are below 70 or there are no more reassignments possible.
What happens when two VMware SD-WAN Gateways give different Hub assignments?
As is the nature of a distributed control plane, each Gateway is making an individual determination of the Cluster assignment. In most cases, Gateways will use the same mathematical formula and thus arrive at the same assignment for all Edges. However, in cases like Cluster Score-based rebalancing this cannot be assured.
If an Edge is not currently connected to a Hub in a Cluster, it will accept the assignment from any Gateway that responds. This ensures that Edges are never left unassigned in a scenario where some Gateways are down and others are up.
What happens when a VMware SD-WAN Gateway goes down?
When a SD-WAN Gateway goes down, Edges may be reassigned if the most preferred Gateway was the one that went down, and the next most preferred Gateway provided a different assignment. For instance, the Super Gateway assigned Hub A to this Edge while the Alternate Super Gateway assigned Hub B to the same Edge.
The Super Gateway going down will trigger the Edge to fail over to Hub B, since the Alternate Super Gateway is now the most preferred Gateway for connectivity information.
When the Super Gateway recovers, the Edge will again request a Hub assignment from this Gateway. In order to prevent the Edge switching back to Hub A again in the scenario above, the Hub assignment request includes the currently assigned Hub (if there is one). When the Gateway processes the assignment request, if the Edge is currently assigned a Hub in the Cluster and that Hub has a Cluster Score less than 70, the Gateway updates its local assignment to match the existing assignment without going through its assignment logic. This ensures that the Super Gateway, on recovery, will assign the currently connected Hub and prevent a gratuitous failover for its assigned Edges.
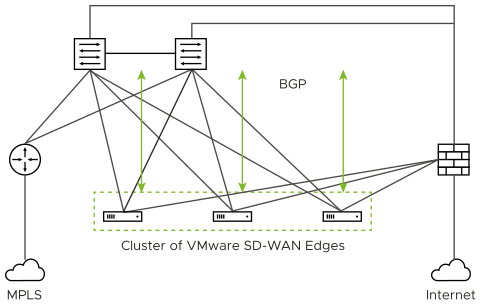
What happens if a Hub in a Cluster loses its dynamic routes?
As noted above, the Hubs report to the SD-WAN Gateways the number of dynamic routes they have learned via BGP every 30 seconds. If routes are lost for only one Hub in a Cluster, either because they are erroneously retracted or the BGP neighborship fails, the SD-WAN Gateways will failover Spoke Edges to another Hub in the Cluster that has an intact routing table.
As the updates are sent every 30 seconds, the route count is based on the moment in time when the update is sent to the SD-WAN Gateway. The SD-WAN Gateway rebalancing logic occurs every 60 seconds, meaning that users can expect failover to take 30-60 seconds in the unlikely event of total loss of a LAN-side BGP neighbor. To ensure that all Hubs have a chance to update the Gateways again following such an event, rebalancing is limited to a maximum of once per 120 seconds. This means that users can expect failover to take 120 seconds for a second successive failure.
How to configure Routing on Cluster Hubs?
As the Gateway can instruct the spokes to connect to any member Hub of the Cluster, the routing configuration should be mirrored on all the Hubs. For example, if the spokes must reach a BGP prefix 192.168.2.1 behind the Hubs, all the Hubs in the cluster should advertise 192.168.2.1 with the exact same route attributes.
BGP uplink community tags should be used in the cluster deployment. Configure the cluster nodes to set the uplink community tag when redistributing routes to BGP peers.
What happens if a Hub in a Cluster fails?
The SD-WAN Gateway will wait for tunnels to be declared dead (7 seconds) before failing over Spoke Edges. This means that users can expect failover to take 7-10 seconds (depending on RTT) when an SD-WAN Hub or all its associated WAN links fail.
