









This topic tells you about how multi‑site replication topology works in VMware Tanzu SQL with MySQL for VMs and contains information to help you decide whether to use the Multi‑Site Replication plan.
The multi‑site replication topology in Tanzu SQL for VMs is a disaster recovery solution that enables developers to provision a leader-follower instance across two foundations. This leader-follower service instance is comprised of two single node instances that are configured for replication. Operators can configure two foundations to be in the same data center or spread across multiple data centers or geographical regions.
The foundation types are:
-
Primary Foundation: This foundation is deployed in your main data center. Generally, this data center receives the majority of app traffic. Tanzu SQL for VMs assumes that the leader is deployed on this foundation when healthy.
-
Secondary Foundation: This foundation is deployed in your failover data center. Generally, this data center receives less app traffic than the primary foundation, or no traffic at all. Tanzu SQL for VMs assumes that the follower is deployed on this foundation unless a developer triggers a failover.
The Multi‑Site Replication plan type is configured separately from the leader-follower service plan.
For information about enabling Multi‑Site Replication, see Preparing for Multi‑Site Replication.
For information for developers about using Multi‑Site Replication, see Using Tanzu SQL for VMs for Multi‑Site Replication.
Multi‑Site Replication benefits
The Multi‑Site Replication plan has the following benefits:
-
Resilience for Service Instances: Developers can trigger a failover to maintain app uptime during a data center outage. For more information, see Triggering Multi‑Site Replication failover and switchover.
-
Data Center Upgrades with Zero Downtime: Operators can upgrade data centers without taking databases offline by triggering a switchover first.
-
Support for Multiple Cloud Deployment Models: Operators can configure multi‑site replication with a single cloud or hybrid cloud deployment model. Both deployment models have the same end-user experience.
-
Support for Active-Passive and App-Layer Active-Active Disaster Recovery:
For more information, see About active-passive topology and About app-layer active-active topology.
Active-passive topology
In an active-passive topology, when all foundations and workloads are healthy, all app traffic is directed to the primary foundation. The secondary foundation receives no app traffic.
VMware recommends using this topology when your secondary foundation is scaled down, generally inactive, and does not receive significant app traffic.
For information about active-passive failover and switchover, see About failover and switchover.
The following diagram describes the active-passive topology in a healthy state:
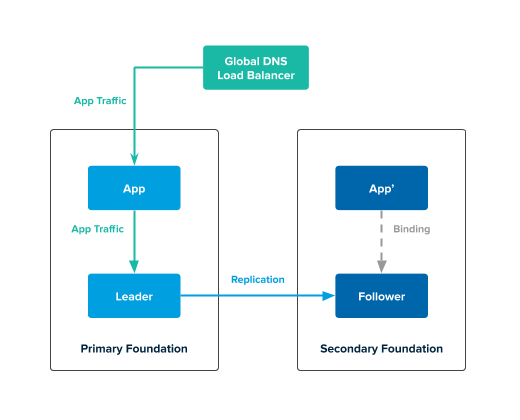
In the preceding diagram:
- The global DNS load balancer (GLB) directs traffic to the app in the primary foundation. This app issues transactions to the leader service instance.
- The follower service instance in the secondary foundation continuously replicates data from the leader service instance in the primary foundation.
App-layer active-active topology
In an app-layer active-active topology, when all foundations and workloads are healthy, app traffic is directed to both the primary and secondary foundation.
VMware recommends using this topology when both your primary and secondary foundations are scaled up and are expected to serve traffic.
For information about app-layer active-active failover and switchover, see About failover and switchover.
The following diagram describes the app-layer active-active topology in a healthy state:
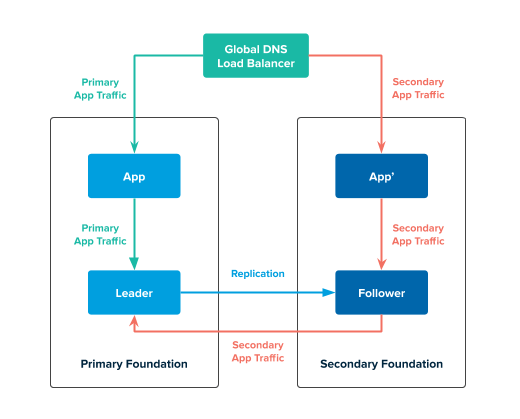
In the preceding diagram:
-
The GLB directs traffic to the apps in the primary and secondary foundations. The apps in the primary and secondary foundation issue transactions to the leader service instance.
The app in the secondary foundation issues transactions to the leader as below:- Connects to the follower service instance
- Issues transactions to the follower service instance
- Forwards the transactions from the follower service instance to the leader
-
The follower service instance in the secondary foundation continuously replicates data from the leader service instance in the primary foundation.
Important In the Multi‑Site Replication plan, the app-layer active-active topology does not enable multi-primary replication. Therefore, the follower service instance is read-only. Apps can only write to the leader.
Failover and switchover
Tanzu SQL for VMs prioritizes data consistency over availability. Therefore, Tanzu SQL for VMs does not trigger failover or switchover automatically and developers must manually trigger a failover or switchover. For instructions about triggering failover or switchover, see see Triggering Multi‑Site Replication Failover and switchover.
The following table describes when you can trigger a failover or switchover:
| Failover if... | Switchover if... |
|---|---|
|
|
|
For information about multi‑site replication topologies in an healthy state, see About active-passive topology and About app-layer active-active topology.
Failover
In both the active-passive and app-layer active-active topologies, if a developer triggers a failover, all app traffic is directed to the leader in the secondary foundation and the primary foundation receives no app traffic.
The following diagram describes what happens when you trigger a failover for a multi‑site replication topology:
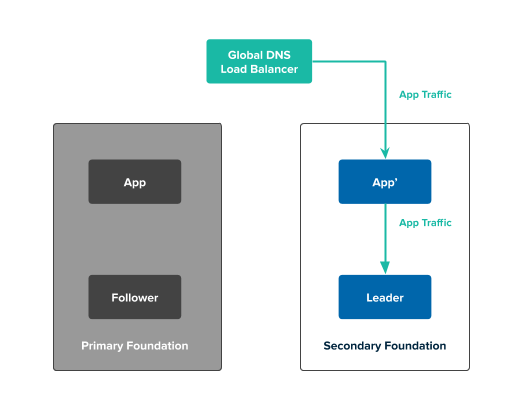
In the previous diagram:
- The GLB directs traffic to the app in the secondary foundation. This app issues transactions to the leader service instance in the secondary foundation.
- The leader service instance in the secondary foundation does not replicate data to another service instance.
Active-passive switchover
In an active-passive topology, if a developer triggers a switchover, all app traffic is directed to the leader in the secondary foundation. The primary foundation receives no app traffic.
The following diagram describes what happens when you trigger a switchover in an active-passive topology:
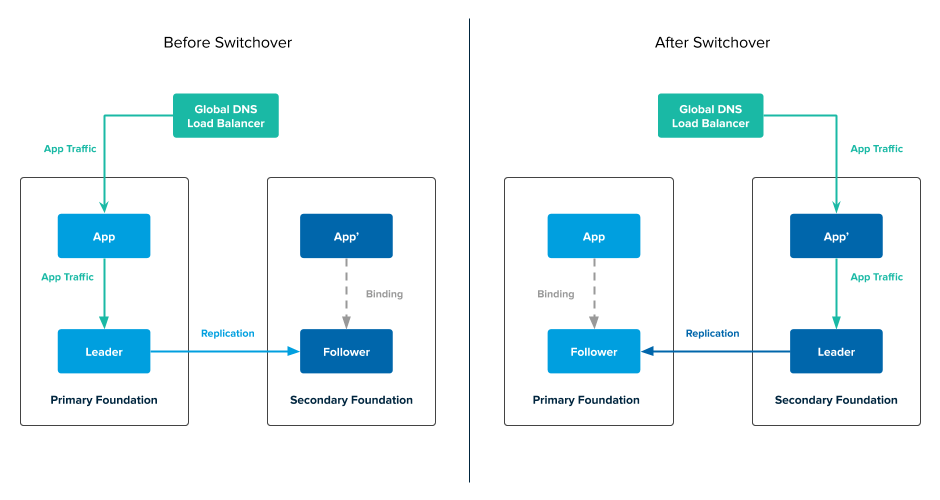
In the preceding diagram:
- The GLB directs traffic to the app in the secondary foundation. This app issues transactions to the leader service instance in the secondary foundation.
- The leader service instance in the secondary foundation replicates data to the follower service instance in the primary foundation.
App-layer active-active switchover
If a developer triggers a switchover, app traffic is still directed to both the primary and secondary foundation. However, the leader service instance is in secondary foundation.
The following diagram describes what happens when you trigger a switchover in an active-active topology:
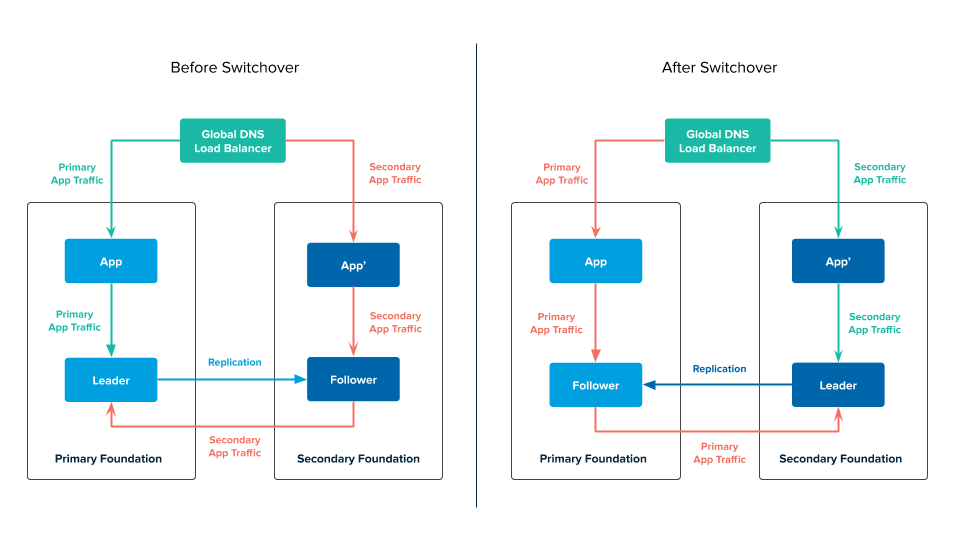
In the preceding diagram:
-
The GLB directs traffic to the apps in the primary and secondary foundations. The apps in the primary and secondary foundation issue transactions to the leader service instance in the secondary foundation.
The app in the primary foundation issues transactions to the leader:- Connects to the follower service instance.
- Issues transactions to the follower service instance.
- Forwards the transactions from the follower service instance to the leader.
-
The follower service instance in the primary foundation continuously replicates data from the leader service instance in the secondary foundation
Infrastructure requirements for Multi‑Site Replication
Before you use the Multi‑Site Replication plan, consider the following requirements.
Capacity planning
When calculating IaaS usage, you must take into account that each Multi‑Site Replication instance requires two VMs. Therefore, the resources used for Multi‑Site Replication plan is twice the amount of single node plan.
For more information, see Setting limits for on-demand service instances and Persistent Disk Usage.
Networking requirements
You must consider the Multi‑Site Replication instances that are deployed in data centers are a geographically farther apart experience higher latencies.
For information about the standard networking rules, see Required Networking Rules for Multi‑Site Replication.
Multi‑Site Replication limitations
The Multi‑Site Replication plan has the following limitation:
Important Synchronous replication is not supported. For multi‑site replication plans, any data that is written to the leader is asynchronously replicated to the follower.
