









Learn how to bootstrap your MySQL cluster in the event of a cluster failure.
You can bootstrap your cluster by using one of these methods:
- Run the bootstrap errand. See Run the Bootstrap errand.
- Bootstrap manually. See Bootstrap manually.
When to bootstrap
You must bootstrap a cluster that loses quorum. A cluster loses quorum when fewer than half the nodes can communicate with each other for longer than the configured grace period. If a cluster does not lose quorum, individual unhealthy nodes automatically rejoin the cluster after resolving the error, restarting the node, or restoring connectivity.
To discover if your cluster has lost quorum, look for the following symptoms:
-
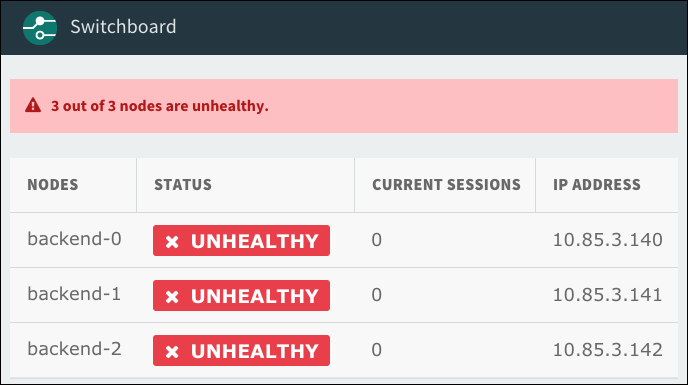
All nodes appear “Unhealthy” on the proxy dashboard. The proxy dashboard is viewable at proxy-BOSH-JOB-INDEX.p-mysql.YOUR-SYSTEM-DOMAIN.
-
All responsive nodes report the value of
wsrep_cluster_statusasnon-Primary:mysql> SHOW STATUS LIKE 'wsrep_cluster_status'; +----------------------+-------------+ | Variable_name | Value | +----------------------+-------------+ | wsrep_cluster_status | non-Primary | +----------------------+-------------+
-
All unresponsive nodes respond with
ERROR 1047when using most statement types in the MySQL client:mysql> select * from mysql.user; ERROR 1047 (08S01) at line 1: WSREP has not yet prepared node for application use
Run the Bootstrap errand
VMware SQL with MySQL for Tanzu Application Service includes a BOSH errand that automates the manual bootstrapping procedure in the Bootstrap manually section below.
It finds the node with the highest transaction sequence number and asks it to start up by itself (i.e. in bootstrap mode) and then asks the remaining nodes to join the cluster.
In most cases, running the errand recovers your cluster. But, certain scenarios require additional steps.
Discover type of cluster failure
To verify which set of instructions to follow:
-
List your MySQL instances by running:
bosh -e YOUR-ENV -d YOUR-DEPLOYMENT instancesWhere:
YOUR-ENVis the environment where you deployed the cluster.YOUR-DEPLOYMENTis the deployment cluster name.
For example:
$ bosh -e prod -d mysql instances
-
Find and record the
Process Statefor your MySQL instances. In the following example output, the MySQL instances are in thefailingprocess state.Instance Process State AZ IPs backup-restore/c635410e-917d-46aa-b054-86d222b6d1c0 running us-central1-b 10.0.4.47 bootstrap/a31af4ff-e1df-4ff1-a781-abc3c6320ed4 - us-central1-b - broker-registrar/1a93e53d-af7c-4308-85d4-3b2b80d504e4 - us-central1-b 10.0.4.58 cf-mysql-broker/137d52b8-a1b0-41f3-847f-c44f51f87728 running us-central1-c 10.0.4.57 cf-mysql-broker/28b463b1-cc12-42bf-b34b-82ca7c417c41 running us-central1-b 10.0.4.56 deregister-and-purge-instances/4cb93432-4d90-4f1d-8152-d0c238fa5aab - us-central1-b - monitoring/f7117dcb-1c22-495e-a99e-cf2add90dea9 running us-central1-b 10.0.4.48 mysql/220fe72a-9026-4e2e-9fe3-1f5c0b6bf09b failing us-central1-b 10.0.4.44 mysql/28a210ac-cb98-4ab4-9672-9f4c661c57b8 failing us-central1-f 10.0.4.46 mysql/c1639373-26a2-44ce-85db-c9fe5a42964b failing us-central1-c 10.0.4.45 proxy/87c5683d-12f5-426c-b925-62521529f64a running us-central1-b 10.0.4.60 proxy/b0115ccd-7973-42d3-b6de-edb5ae53c63e running us-central1-c 10.0.4.61 rejoin-unsafe/8ce9370a-e86b-4638-bf76-e103f858413f - us-central1-b - smoke-tests/e026aaef-efd9-4644-8d14-0811cb1ba733 - us-central1-b 10.0.4.59
-
Choose your scenario:
- If your MySQL instances are in the
failingstate, continue to Scenario 1. - If your MySQL instances are in the
-state, continue to Scenario 2. - If your MySQL instances are in the
stoppedstate, continue to Scenario 3.
- If your MySQL instances are in the
Scenario 1: VMs running, cluster disrupted
In this scenario, the VMs are running, but the cluster has been disrupted.
To bootstrap in this scenario:
-
Run the bootstrap errand on the VM where the bootstrap errand is co-located, by running:
bosh -e YOUR-ENV -d YOUR-DEPLOYMENT run-errand bootstrapWhere:
YOUR-ENVis the name of your environment.YOUR-DEPLOYMENTis the name of your deployment.
Important The errand runs for a long time, during which no output is returned.
The command returns many lines of output, eventually followed by:
Bootstrap errand completed [stderr] + echo 'Started bootstrap errand ...' + JOB\_DIR=/var/vcap/jobs/bootstrap + CONFIG\_PATH=/var/vcap/jobs/bootstrap/config/config.yml + /var/vcap/packages/bootstrap/bin/cf-mysql-bootstrap -configPath=/var/vcap/jobs/bootstrap/config/config.yml + echo 'Bootstrap errand completed' + exit 0 Errand 'bootstrap' completed successfully (exit code 0)
-
If the errand fails, run the bootstrap errand command again after a few minutes. The bootstrap errand might not work the first time.
-
If the errand fails after several tries, bootstrap your cluster manually. See Bootstrap manually below.
Scenario 2: VMs terminated or lost
In severe circumstances, such as a power failure, it is possible to lose all your VMs. You must re-create them before you can begin recovering the cluster.
When MySQL instances are in the - state, the VMs are lost. The procedures in this scenario bring the instances from a - state to a failing state. Then you run the bootstrap errand similar to Scenario 1 and restore configuration.
To recover terminated or lost VMs, follow the procedures in the sections below:
-
Re-create the missing VMs: Bring MySQL instances from a
-state to afailingstate. -
Run the Bootstrap errand: Because your instances are now in the
failingstate, continue similarly to Scenario 1. -
Restore the BOSH configuration: Go back to unignoring all instances and redeploy. This is a critical and mandatory step.
Important If you do not set each of your ignored instances to unignore, your instances are not updated in future deploys. You must follow the procedure in the final section of Scenario 2, Restore the BOSH Configuration.
Recreate the missing VMs
The procedure in this section uses BOSH to re-create the VMs, install software on them, and try to start the jobs.
The following procedure allows you to:
-
Redeploy your cluster while expecting the jobs to fail.
-
Instruct BOSH to ignore the state of each instance in your cluster. This allows BOSH to deploy the software to each instance even if the instance is failing.
To re-create your missing VMs:
-
If BOSH Resurrector is activated, deactivate it by running:
bosh -e YOUR-ENV update-resurrection offWhere
YOUR-ENVis the name of your environment. -
Download the current manifest by running:
bosh -e YOUR-ENV -d YOUR-DEPLOYMENT manifest > /tmp/manifest.ymlWhere:
YOUR-ENVis the name of your environment.YOUR-DEPLOYMENTis the name of your deployment.
-
Redeploy deployment by running:
bosh -e YOUR-ENV -d YOUR-DEPLOYMENT deploy /tmp/manifest.ymlWhere:
YOUR-ENVis the name of your environment.YOUR-DEPLOYMENTis the name of your deployment.
Important Expect one of the MySQL VMs to fail. Deploying causes BOSH to create new VMs and install the software. Forming a cluster is in a subsequent step.
-
View the instance GUID of the MySQL VM that attempted to start by running:
bosh -e YOUR-ENV -d YOUR-DEPLOYMENT instancesWhere:
YOUR-ENVis the name of your environment.YOUR-DEPLOYMENTis the name of your deployment.
Record the instance GUID, which is the string after
mysql/in your BOSH instances output. -
Instruct BOSH to ignore the MySQL VM that just attempted to start, by running:
bosh -e YOUR-ENV -d YOUR-DEPLOYMENT ignore mysql/INSTANCE-GUIDWhere:
YOUR-ENVis the name of your environment.YOUR-DEPLOYMENTis the name of your deployment.INSTANCE-GUIDis the GUID of your instance you recorded in the previous step.
-
Repeat steps 3 through 5 until all instances have attempted to start.
-
If you deactivated the BOSH Resurrector in step 1, re-enable it by running:
bosh -e YOUR-ENV update-resurrection onWhere
YOUR-ENVis the name of your environment. -
Confirm that your MySQL instances have gone from the
-state to thefailingstate by running:bosh -e YOUR-ENV -d YOUR-DEPLOYMENT instancesWhere:
YOUR-ENVis the name of your environment.YOUR-DEPLOYMENTis the name of your deployment.
Run the Bootstrap errand
After you recreate the VMs, all instances now have a failing process state and have the MySQL code. You must run the bootstrap errand to recover the cluster.
To bootstrap:
-
Run the bootstrap errand by running:
bosh -e YOUR-ENV -d YOUR-DEPLOYMENT run-errand bootstrapWhere:
YOUR-ENVis the name of your environment.YOUR-DEPLOYMENTis the name of your deployment.
Important The errand runs for a long time, during which no output is returned.
The command returns many lines of output, eventually with the following successful output:
Bootstrap errand completed [stderr] echo 'Started bootstrap errand ...' JOB\_DIR=/var/vcap/jobs/bootstrap CONFIG\_PATH=/var/vcap/jobs/bootstrap/config/config.yml /var/vcap/packages/bootstrap/bin/cf-mysql-bootstrap -configPath=/var/vcap/jobs/bootstrap/config/config.yml echo 'Bootstrap errand completed' exit 0 Errand 'bootstrap' completed successfully (exit code 0)
-
If the errand fails, run the bootstrap errand command again after a few minutes. The bootstrap errand might not work immediately.
-
See that the errand completes successfully in the shell output and continue to Restore the BOSH configuration below.
After you complete the bootstrap errand, you might still see instances in the failing state. Continue to the next section anyway.
Important If you do not set each of your ignored instances to unignore, your instances are never updated in future deploys.
To restore your BOSH configuration to its previous state, this procedure unignores each instance that was previously ignored:
-
For each ignored instance, run:
bosh -e YOUR-ENV -d YOUR-DEPLOYMENT unignore mysql/INSTANCE-GUIDWhere:
YOUR-ENVis the name of your environment.YOUR-DEPLOYMENTis the name of your deployment.INSTANCE-GUIDis the GUID of your instance.
-
Redeploy your deployment by running:
bosh -e YOUR-ENV -d YOUR-DEPLOYMENT deployWhere:
YOUR-ENVis the name of your environment.YOUR-DEPLOYMENTis the name of your deployment.
-
Verify that all
mysqlinstances are in arunningstate by running:bosh -e YOUR-ENV -d YOUR-DEPLOYMENT instancesWhere:
YOUR-ENVis the name of your environment.YOUR-DEPLOYMENTis the name of your deployment.
Bootstrap manually
If the bootstrap errand cannot automatically recover the cluster, you must do the steps manually.
Follow the procedures in the sections below to manually bootstrap your cluster.
CautionThe following procedures are prone to user error and can cause lost data if followed incorrectly. Follow the procedure in Bootstrap with the BOSH Errand first, and only resort to the manual process if the errand fails to repair the cluster.
Shut down MySQL
Follow these steps to stop the galera-init process for each node in the cluster. For each node, record if the monit stop command was successful:
-
SSH into the node using the procedure in Advanced troubleshooting with the BOSH CLI.
-
To shut down the
mysqldprocess on the node, run:monit stop galera-init -
Record if the `monit command succeeds or exits with an error:
-
If
monitsucceeds in stoppinggalera-init, then you can use `monit to restart this node. Follow all the steps below including the steps marked Monit Restart but omitting the steps marked Manual Redeploy. -
If
monitexits with the following error, then you must manually deploy this node:Warning: include files not found '/var/vcap/monit/job/*.monitrc' monit: action failed -- There is no service by that name
Follow all the steps below including the steps marked Manual Redeploy but omitting the steps marked Monit Restart.
-
-
Repeat the preceding steps for each node in the cluster.
You cannot bootstrap the cluster unless you have shut down the
mysqldprocess on all nodes in the cluster.
Verify which node to bootstrap
To identify which node to bootstrap, you must find the node with the highest transaction sequence_number. The node with the highest sequence number is the one most recently updated.
To identify the node to bootstrap:
-
SSH into the node using the procedure in Advanced troubleshooting with the BOSH CLI.
-
View the sequence number for a node by running:
/var/vcap/jobs/pxc-mysql/bin/get-sequence-numberWhen prompted confirm that you want to stop MySQL.
For example:
$ /var/vcap/jobs/mysql/bin/get-sequence-number This script stops mysql. Are you sure? (y/n): y {"sequence_number":421,"instance_id":"012abcde-f34g-567h-ijk8-9123l4567891"} -
Record the value of
sequence_number. -
Repeat these steps for each node in the cluster.
-
After you verify the
sequence_numberfor all nodes in your cluster, identify the node with the highestsequence_number. If all nodes have the samesequence_number, you can choose any node as the new bootstrap node.
To avoid losing data, you must bootstrap from a node in the cluster that has the highest transaction sequence number (seqno).
If /var/vcap/jobs/pxc-mysql/bin/get-sequence-number returns a failure:
$ /var/vcap/jobs/pxc-mysql/bin/get-sequence-number Failure obtaining sequence number! Result was: [ ] $
Use the following procedure to retrieve the seqno value.
-
For each node in the cluster, find the
seqnovalue:-
Use SSH to log in to the node, following the procedure in the Tanzu Operations Manager documentation.
-
Find
seqnovalues in the node’s Galera state file,grastate.dat, by running:cat /var/vcap/store/pxc-mysql/grastate.dat | grep 'seqno:' -
If the last and highest
seqnovalue in the output is a positive integer, the node shut down gracefully. Record this number. -
If the last and highest
seqnovalue in the output is-1, the node crashed or was stopped. To recover theseqnovalue from the database:-
Temporarily start the database and append the last sequence number to its error log by running:
$ /var/vcap/jobs/pxc-mysql/bin/get-sequence-number -
The output of the
get-sequence-numberutility looks like:{ "cluster_uuid": "1f594c30-a709-11ed-a00e-5330bbda96d3", "seqno": 4237, "instance_id": "4213a73e-069f-4ac7-b01b-43068ab312b6" }The
seqnoin the output is4237. -
If the node never connected to the cluster before crashing, there might not be a group ID assigned. In this case, there is nothing to recover. Do not choose this node for bootstrapping unless all of the other nodes also crashed.
-
-
-
After retrieving the
seqnovalues for all nodes in the cluster, identify the node with the highestseqnovalue. If multiple nodes share the same highestseqnovalue, and it is not-1, you can bootstrap from any of those nodes.
Bootstrap the first node
After discovering the node with the highest sequence_number, do the following to bootstrap the node:
Caution Only run these bootstrap commands on the node that you previously identified in Verify which node to bootstrap. Non-bootstrapped nodes abandon their data during the bootstrapping process. Therefore, bootstrapping off the wrong node causes data loss. For information about intentionally abandoning data, see the architecture sections in the VMware SQL with MySQL for Tanzu Application Service documentation.
-
SSH into the node using the procedure in Advanced troubleshooting with BOSH CLI.
-
Update the node state to trigger its initialization of the cluster by running:
echo -n "NEEDS_BOOTSTRAP" > /var/vcap/store/pxc-mysql/state.txt -
Monit Restart: If when doing Shut down MySQL you successfully used
monitto shut down yourgalera-initprocess, then re-launch themysqldprocess on the new bootstrap node.-
Start the
mysqldprocess by running:monit start galera-init -
It can take up to ten minutes for
monitto start themysqldprocess. To confirm if themysqldprocess has started, run:watch monit summaryIf
monitsucceeds in starting the galera-init process, then the output includes the lineProcess 'galera-init' running.
-
-
Manual Redeploy: If when doing Shut down MySQL you encountered
moniterrors, then redeploy themysqldsoftware to your bootstrap node as follows:-
Leave the MySQL SSH login shell and return to your local environment.
-
Target BOSH on your bootstrap node by instructing it to ignore the other nodes in your cluster. For nodes all nodes except the bootstrap node you identified earlier, run:
bosh -e YOUR-ENV -d YOUR-DEPLOYMENT ignore mysql/M bosh -e YOUR-ENV -d YOUR-DEPLOYMENT ignore mysql/NWhere
NandMare the numbers of the non-bootstrapped nodes. For example, if you bootstrap node 0, thenM=1 andN=2. -
Turn off the BOSH Resurrector by running:
bosh update-resurrection off -
Use the BOSH manifest to bootstrap your bootstrap machine by running:
bosh -e YOUR-ENV -d YOUR-DEPLOYMENT manifest > /tmp/manifest.yml bosh -e YOUR-ENV -d YOUR-DEPLOYMENT deploy /tmp/manifest.yml
-
Restart remaining nodes
After the bootstrapped node is running, restart the remaining nodes.
The procedure to follow for restarting a node depends on the output you got for that node when doing Shut down MySQL. Do one of the following procedures:
Monit restart
If in Shut down MySQL you successfully used monit to shut down your galera-init process, then restart the nodes as follows:
-
SSH into the node using the procedure in Advanced troubleshooting with BOSH CLI.
-
Start the
mysqldprocess withmonitby running:monit start galera-initIf the Interruptor (see the MySQL documentation) prevents the node from starting, follow the manual procedure to force the node to rejoin the cluster. See Manually force a MySQL node to rejoin if a node cannot rejoin the HA cluster.
Caution Forcing a node to rejoin the cluster is a destructive procedure. Only follow the procedure with the help of [VMware Tanzu Support](https://tanzu.vmware.com/support).
-
If the
monit startcommand fails, it might be because the node with the highestsequence_numberismysql/0.In this case:
-
Ensure that BOSH ignores updating
mysql/0by running:bosh -e YOUR-ENV -d YOUR-DEPLOYMENT ignore mysql/0Where:
YOUR-ENVis the name of your environment.YOUR-DEPLOYMENTis the name of your deployment.
-
Navigate to Tanzu Operations Manager in a browser, log in, and click Apply Changes.
-
When the deploy finishes, run the following command from the Tanzu Operations Manager VM:
bosh -e YOUR-ENV -d YOUR-DEPLOYMENT unignore mysql/0Where:
YOUR-ENVis the name of your environment.YOUR-DEPLOYMENTis the name of your deployment.
-
Manual redeploy
If in doing Shut down MySQL, you encountered monit errors, then restart the nodes as follows:
-
Instruct BOSH to no longer ignore the non-bootstrap nodes in your cluster by running:
bosh -e YOUR-ENV -d YOUR-DEPLOYMENT unignore mysql/M bosh -e YOUR-ENV -d YOUR-DEPLOYMENT unignore mysql/NWhere
NandMare the numbers of the non-bootstrapped nodes. For example, if you bootstrap node 0, thenM=1 andN=2. -
Redeploy software to the other two nodes and have them rejoin the cluster, bootstrapped from the node above by running:
bosh -e YOUR-ENV -d YOUR-DEPLOYMENT deploy /tmp/manifest.ymlYou only need to run this command once to deploy both the nodes that you unignored in the earlier step.
-
With your redeploys completed, turn the BOSH Resurrector back on by running:
bosh -e YOUR-ENV update-resurrection on
Verify that the nodes have joined the cluster
The final task is to verify that all the nodes have joined the cluster.
-
SSH into the bootstrap node then run the following command to output the total number of nodes in the cluster:
mysql> SHOW STATUS LIKE 'wsrep_cluster_size';
Manually force a MySQL node to rejoin if a node cannot rejoin the HA cluster
When a MySQL node cannot rejoin the HA cluster automatically, a Tanzu Application Service (TAS for VMs) operator must manually force the node to rejoin. The following procedure applies to TAS for VMs MySQL and MySQL tile HA clusters. This section describes the case where a single node is joined to a cluster. For bootstrapping, see the TAS for VMs or MySQL tile documentation.
When a node cannot rejoin the HA (Percona XtraDB Cluster - PXC) cluster automatically, an operator needs to manually force a MySQL node to rejoin.
If your HA cluster is experiencing downtime or is in a degraded state, VMware recommends first running the mysql-diag tool to gather information about the current state of the cluster. This tool will either report a healthy cluster with (typically) 3 running nodes, a cluster in quorum with two running nodes and a third node needing to re-join, or a cluster that has lost quorum and requires a bootstrap. The mysql-diag tool is available on the mysql_monitor instance for a TAS for VMs internal cluster or on the mysql_jumpbox instance for a MySQL tile HA service instance.
This procedure removes all the data from a server node, forces it to join the cluster, receiving a current copy of the data from one of the other nodes already in the cluster. The steps are slightly different based on which MySQL cluster this is for.
Cautions:
-
Do not do this if there is any data on the local node that you need to preserve.
-
The other two nodes must be online and healthy. You can validate this by looking at the
mysql-diagoutput or checking the MySQL Proxy logs (i.e.,grep 'Healthcheck failed on backend' proxy.combined.log).mysql-diagreports a healthy node as “Synced” and “Primary”.
For a TAS MySQL cluster or a MySQL tile HAS cluster:
- Log into the instance as
root. - Run
monit stop galera-init. Skip to step 3 if the monit job is unavailable. - Ensure mysql is stopped by running
ps auxw | grep mysqld. Kill themysqldprocess(es) if they are running. - Run
mv /var/vcap/store/pxc-mysql /var/vcap/store/pxc-mysql-backup(or if disk space is a concern, runrm -rf /var/vcap/store/pxc-mysql). Clean up the backup after successfully joining the node to the cluster. - Run
/var/vcap/jobs/pxc-mysql/bin/pre-start. An error code of 0 indicates success. -
Restart the database on the instance using one of these commands:
- If the monit job is available, run
monit start galera-init - If the instance has no
galera-initmonit job, runbosh -d deploymentName restart mysql/instanceGUID --no-converge
- If the monit job is available, run
