









This topic describes how Highly Available (HA) clusters work in VMware SQL with MySQL for Tanzu Application Service and provides information to help you decide whether to use HA clusters.
Highly available cluster topology
In an HA cluster topology, a cluster consists of three nodes. Each node contains the same set of data synchronized across nodes. Data is simultaneously replicated across nodes or not written at all if replication fails even on a single node.
With three nodes, HA clusters are highly available and resilient to failure because if a node loses contact with the other two nodes, the other two nodes can remain in contact and continue to accept transactions. If the number of nodes is odd, the two nodes can represent the primary component.
For more information about cluster availability, see Percona XtraDB Cluster: Quorum and Availability of the cluster in the Percona XtraDB Cluster documentation.
In HA topology, the VMware Tanzu for MySQL service uses the following:
-
Three MySQL servers running Percona XtraDB as the MySQL engine and Galera to keep them in sync.
-
Three Switchboard proxies that are co-located on the MySQL nodes. The proxies gracefully handle failure of nodes which enables fast failover to other nodes within the cluster. For more information, see MySQL Proxy.
-
A jumpbox VM called
mysql-monitorfor monitoring, diagnosing and backing up MySQL nodes. You can run themysql-diagtool on themysql-monitorVM to view the status of your cluster nodes. For more information aboutmysql-diag, see Running mysql-diag.
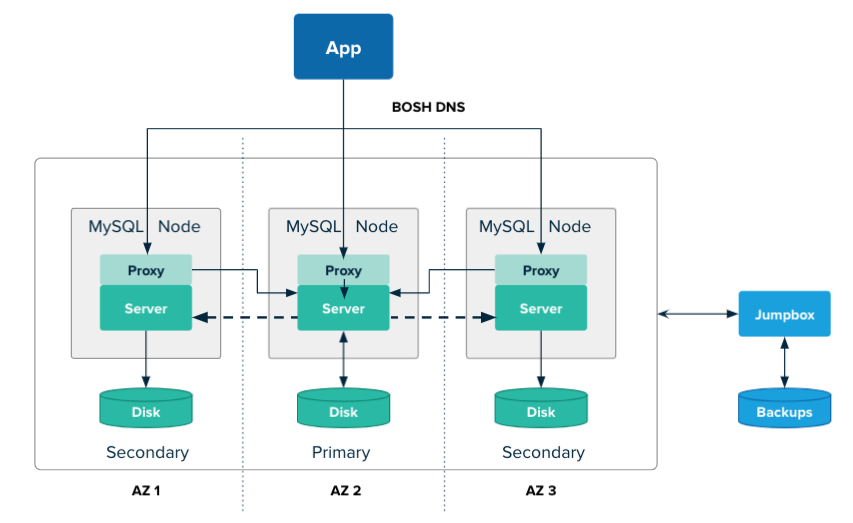
The following diagram shows an HA cluster in three availability zones (AZs):
 See the following image for a detailed description.
See the following image for a detailed description.
The diagram shows an app communicating with a MySQL cluster using BOSH DNS. Each of the three MySQL nodes is located in its own AZ. Each MySQL node contains a proxy and a server, and has its’ own disk. Arrows are shown thAT connect the MySQL nodes, indicating that they can communicate with each other across AZs. The dotted lines indicate data replication from the primary to the secondary databases.
Traffic from apps and clients is sent round robin to the proxies on all nodes over BOSH DNS. The proxies direct their traffic to the server on the primary node.
If the primary server fails, a secondary node is promoted to become the new primary. The proxies are updated to ensure that traffic is sent to the new primary.
For more information about other availability options supported by VMware Tanzu for MySQL, see Availability Options.
Using highly available deployments as a multi-site leader
You may configure a HA cluster running MySQL 8.0.x (or greater) to act as the leader in a multi-site replication configuration. This configuration establishes a follower service instance of type multi‑site replication in a second foundation, and establishes replication from your leader HA cluster to that follower multi‑site replication instance.
For more information, see About multi-site replication.
ImportantBefore you can use a highly available deployment as a multi-site leader, your operator must enable Service-Gateway. You must create the leader instance with Service-Gateway access. For general information about Service-Gateway access, including architecture and use cases, see About Service-Gateway access.
Infrastructure Requirements for highly available deployments
Before you decide to use HA clusters for VMware Tanzu for MySQL service plans, consider the following requirements.
Capacity planning
When you calculate IaaS usage, you must take into account that each HA instance requires three VMs. Therefore, the resources used for an HA plan must be tripled. For more information, see Resource Usage Planning for On-Demand Plans.
Availability zones
To minimize impact of an availability zone (AZ) outage and to remove single points of failure, VMware recommends that you provision three AZs if using HA deployments. With three AZs, nodes are deployed to separate AZs.
For more information, see Availability Using Multiple AZs in VMware SQL with MySQL for Tanzu Application Service Recommended Usage and Limitations.
Networking Rules
In addition to the standard networking rules needed for VMware Tanzu for MySQL, you must ensure HA cluster specific network rules are also configured.
For information about HA cluster specific networking rules, see Required Networking Rules for Highly Available Cluster Plans.
Highly available cluster limitations
When deployed with HA topology, VMware Tanzu for MySQL runs three nodes. This cluster arrangement imposes some limitations which do not apply to single node or leader-follower MySQL database servers. For more information about the difference between single node, leader-follower, and HA cluster topologies, see Availability Options.
HA clusters perform validations at startup and during runtime to prevent you from using MySQL features that are not supported. If a validation fails during startup, the server is halted and throws an error. If a validation fails during runtime the operation is denied and throws an error.
These validations are designed to ensure optimal operation for common cluster setups that do not require experimental features and do not rely on operations not supported by HA clusters.
For more information about HA limitations, see Percona XtraDB Cluster Limitations in the Percona XtraDB Cluster documentation.
Storage engine limitations
-
HA clusters only supports the InnoDB storage engine. The InnoDB is the default storage engine for new tables. Pre-existing tables that are not using InnoDB are at risk because they are not replicated within a cluster.
-
Large DDL statements can lock all schemas. This can be mitigated by using the Rolling Schema Upgrade (RSU) method. For instructions on how to use the RSU method, see Using a rolling schema upgrade (RSU).
-
Large transaction sizes can inhibit the performance of the cluster and apps using the cluster because they are buffered in memory.
-
You cannot run a DML statement in parallel with a DDL statement, if both statements affect the same tables. If they are expected in parallel, the DML and DDL statements are both applied immediately to the cluster, and cause errors.
Architecture limitations
-
All tables must have a primary key. You can use multi-column primary keys. This is because HA clusters replicate using row based replication and ensure unique rows on each instance.
-
Explicit table locking is not supported. For more information, see EXPLICIT TABLE LOCKING in the Percona XtraDB Cluster documentation.
-
By default, auto-increment variables are not sequential and each node has gaps in IDs. This prevents auto-increment replication conflicts across the cluster. For more information, see wsrep_auto_increment_control in the Percona XtraDB Cluster documentation.
-
You cannot change the session behavior of auto-increment variables. This is because the HA cluster controls the behavior of these variables. For example, if an app runs
SET SESSION auto_increment_increment, the cluster ignores the change. -
In InnoDB, some transactions can cause deadlocks. You can minimize deadlocks in your apps by rewriting transactions and SQL statements. For more information about deadlocks, see Deadlocks in InnoDB and How to Minimize and Handle Deadlocks in MySQL documentation.
-
Table partitioning can cause performance issues in the cluster. This is as a result of the implicit table locks that are used when running table partition commands.
Networking limitations
- Round-trip latency between database nodes must be less than five seconds. Latency exceeding this results in a network partition. If more than half of the nodes are partitioned, the cluster loses quorum and becomes unusable until manually bootstrapped. For more information about bootstrapping HA clusters, see Bootstrapping.
MySQL Server defaults for HA components
This section describes some defaults that VMware Tanzu for MySQL applies to HA components.
State snapshot transfer process
When a new node is added to or rejoins a cluster, a primary node from the cluster is designated as the state donor. The new node synchronizes with the donor through the State Snapshot Transfer (SST) process.
VMware Tanzu for MySQL uses Xtrabackup for SST, which lets the state donor node to continue accepting reads and writes during the transfer. HA clusters default to using rsync to perform SST, which is fast, but blocks requests during the transfer. For more information about Percona XtraBackup SST Configuration in the Percona XtraDB Cluster documentation.
Large data file splitting enabled
By default, HA clusters splits large Load Data commands into small manageable units. This deviates from the standard behavior for MySQL.
For more information, see wsrep_load_data_splitting in the Percona XtraDB Cluster documentation.
Maximum transaction sizes
These are the maximum transaction sizes set for HA clusters:
The maximum write-set size that is allowed in HA clusters is 2 GB. For more information, see wsrep_max_ws_size.
The maximum number of rows each write-set can contain defaults to no limit. For more information, see wsrep_max_ws_rows.
MySQL proxy
VMware SQL with MySQL for Tanzu Application Service uses a proxy to send client connections to the healthy MySQL database cluster nodes in a highly available cluster plan. Using a proxy handles failure of nodes, enabling fast, failover to other nodes within the cluster. When a node becomes unhealthy, the proxy closes all connections to the unhealthy node and re-routes all subsequent connections to a healthy node.
The proxy used in VMware Tanzu for MySQL is Switchboard. Switchboard was developed to replace HAProxy as the proxy tier for the high availability cluster for MySQL databases in VMware Tanzu for MySQL.
See the following image for a detailed description. 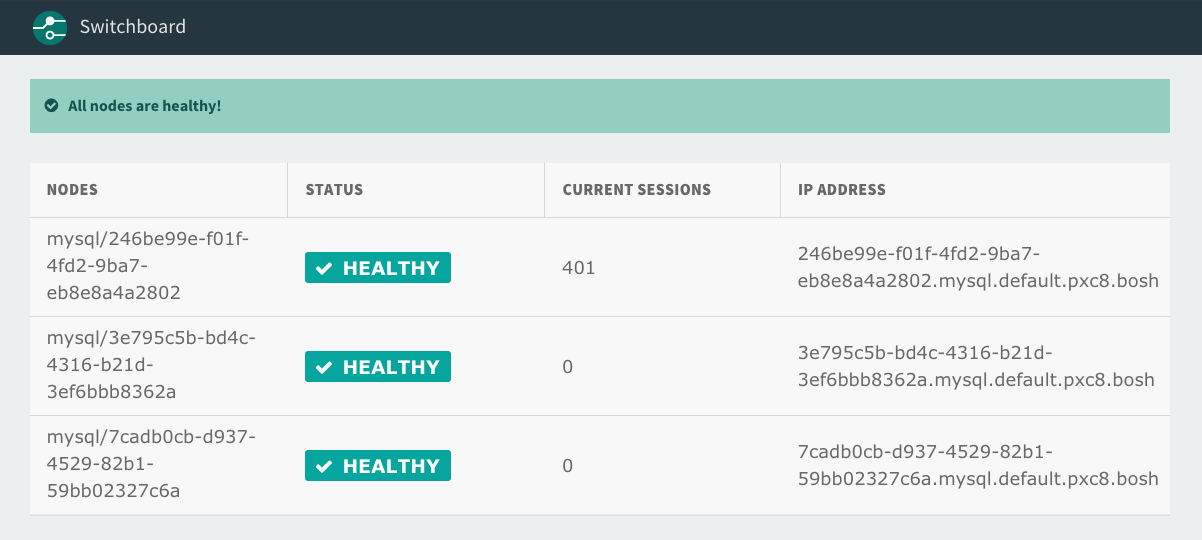
Switchboard offers the following features:
-
MySQL Server Access
MySQL clients communicate with nodes through this network port. These connections are automatically passed through to the nodes.
-
Switchboard and API
Operators can connect to Switchboard to view the state of the nodes.
For more information about monitoring proxy health status, see Monitoring Node Health.
