









This topic describes how to enable High Availability (HA) for VMware Postgres Operator. HA offers automatic failover that ensures any application requests operate continuously, and without downtime.
VMware Postgres Operator uses the pg_auto_failover extension to provide a highly available Postgres cluster on Kubernetes. For detailed information about pg_auto_failover features, see the pg_auto_failover documentation.
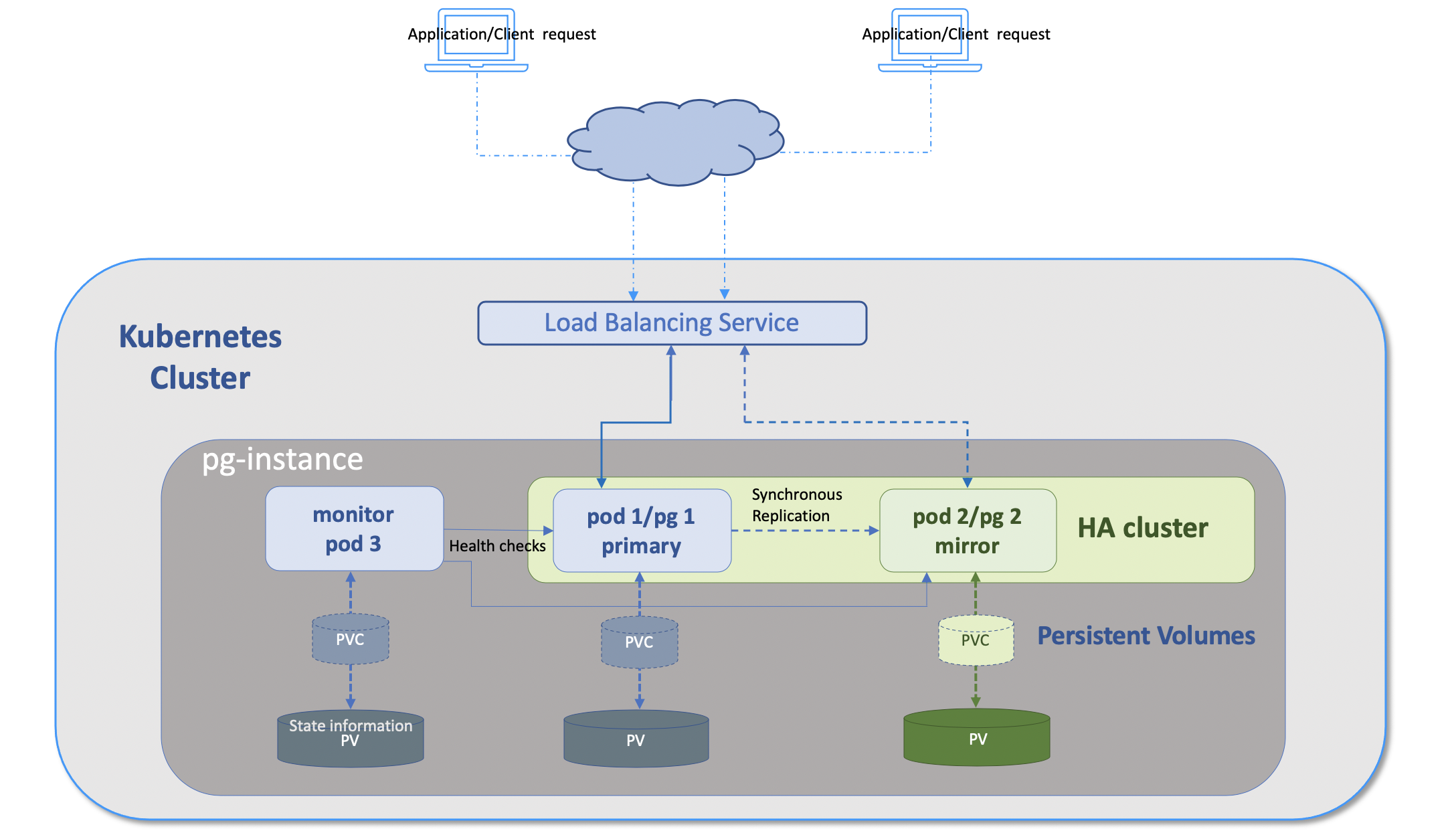
In the VMware Postgres Operator HA cluster configuration, the topology consists of three pods: one monitor, one primary and one hot standby mirror. pg_auto_failover ensures that the data is synchronously replicated from the primary to the mirror node. If the primary node is unresponsive, the application requests are re-directed to the mirror node, which gets promoted to the primary. All application requests continue to the promoted primary, while a new postgres instance is started which becomes the new mirror. If the monitor pod fails, operations continue as normal. The Postgres operator redeploys a monitor pod, and when ready it resumes monitoring of the primary and secondary.
The Postgres operator supports Pod Disruption Budget for HA instances. When enabled, the Pod Disruption Budget only tolerates the loss of one pod between the monitor and data stateful sets in voluntary eviction events like node drains. In case the HA instance is scaled down to a single instance, PDB will be deleted.
Configuring High Availability
Prerequisites
Ensure that you have a VMware Postgres Operator. For details, refer to Installing a Postgres Operator.
Review Deploying a New Postgres Instance, to become familiar with the Postgres instance manifest YAML file.
Procedure
To enable VMware Postgres Operator high availability (HA mode), edit your copy of the instance YAML file you created during Deploying a New Postgres Instance. In the YAML, uncomment, and alter the
highAvailabilityfield totrue:...... spec: memory: 800Mi cpu: "0.8" storageClassName: standard storageSize: 10G serviceType: ClusterIP pgConfig: dbname: username: highAvailability: enabled: true readReplicas: 1 podDisruptionBudget: enabled: false ......If the
highAvailabilityfield is left commented-out, or empty, the Postgres instance is by default a single node configuration with no read-replicas.The field
highAvailability.readReplicasrepresents the number of read replicas that will be configured when the Postgres instance is deployed.readReplicasrequires thehighAvailability.enabledfield to be set totrue. The fieldhighAvailability.podDisruptionBudget.enabledspecifies if Pod Disruption Budget should be enabled for the Postgres instance.podDisruptionBudget.enabledrequires thehighAvailability.enabledfield to be set totrue.Deploy or redeploy the instance with the new
highAvailabilitysetting using:kubectl apply -f postgres.yamlwhere
postgres.yamlis the example name of the Kubernetes manifest created for this instance.The command output would be similar to:
postgres.sql.tanzu.vmware.com/postgres-sample createdwhere postgres-sample is the Postgres instance
namedefined in the YAML file.At this point, the Postgres operator deploys the three Postgres instance pods: the monitor, the primary, and the mirror.
Verifying the HA Configuration
To confirm your HA configuration is ready for access, use kubectl get to review the STATUS field and confirm that it shows "Running". Initially STATUS will show Created, until all artifacts are deployed. Use Ctr-C to escape the watch command.
watch kubectl get postgres/postgres-sample
NAME STATUS BACKUP LOCATION AGE
postgres-sample Pending backuplocation-sample 17m
To view the created pods, use:
kubectl get pods
NAME READY STATUS RESTARTS AGE
pod/postgres-sample-0 1/1 Running 0 11m
pod/postgres-sample-monitor 1/1 Running 0 12m
pod/postgres-sample-1 1/1 Running 0 4m28s
You can now log into the primary pod using kubectl exec -it <pod-name> -- bash:
kubectl exec -it postgres-sample-0 -- bash
You can log into any pod with kubectl exec and use the pg_autoctl tool to inspect the state of the cluster. Run pg_autoctl show state to see which pod is currently the primary:
kubectl exec pod/postgres-sample-1 -- pg_autoctl show state
Name | Node | Host:Port | TLI: LSN | Connection | Current State | Assigned State
-------+-------+------------------------------------------------------------------------+----------------+--------------+---------------------+--------------------
node_1 | 1 | postgres-sample-0.postgres-sample-agent.default.svc.cluster.local:5432 | 2: 0/3002690 | read-only | secondary | secondary
node_2 | 2 | postgres-sample-1.postgres-sample-agent.default.svc.cluster.local:5432 | 2: 0/3002690 | read-write | primary | primary
The pg_autoctl set of commands manage the pg_autofailover services. For further information, refer to the pg_autoctl reference documentation.
Important: VMware does not support using the following pg_autoctl commands on the Postgres pods: pg_autoctl create, pg_autoctl drop, pg_autoctl enable, pg_autoctl disable, pg_autoctl config set, pg_autoctl run, pg_autoctl stop, and pg_autoctl activate.
If the primary is unreachable, during the primary to mirror failover, the Current State and Assigned State status columns toggle between demoted, catching_up, wait_primary, secondary, and primary. You can monitor the states using pg_autoctl:
watch pg_autoctl show state
Name | Node | Host:Port | TLI: LSN | Connection | Current State | Assigned State
-------+-------+------------------------------------------------------------------------+----------------+--------------+---------------------+--------------------
node_1 | 1 | postgres-sample-0.postgres-sample-agent.default.svc.cluster.local:5432 | 2: 0/3002690 | read-only | demoted | catching_up
node_2 | 2 | postgres-sample-1.postgres-sample-agent.default.svc.cluster.local:5432 | 2: 0/3002690 | read-write | primary | primary
Name | Node | Host:Port | TLI: LSN | Connection | Current State | Assigned State
-------+-------+------------------------------------------------------------------------+----------------+--------------+---------------------+--------------------
node_1 | 1 | postgres-sample-0.postgres-sample-agent.default.svc.cluster.local:5432 | 2: 0/3002690 | read-only | secondary | secondary
node_2 | 2 | postgres-sample-1.postgres-sample-agent.default.svc.cluster.local:5432 | 2: 0/3002690 | read-write | primary | primary
Scaling down the HA Configuration
An HA instance's read replicas can be scaled down by modifying the highAvailability.readReplicas field. For example, to alter an HA cluster with one read replica, to a single node configuration, alter the Postgres instance YAML and change the HA readReplicas field from:
apiVersion: sql.tanzu.vmware.com/v1
kind: Postgres
metadata:
name: ha-postgres-sample
spec:
highAvailability:
enabled: true
readReplicas: 1
podDisruptionBudget:
enabled: false
to:
apiVersion: sql.tanzu.vmware.com/v1
kind: Postgres
metadata:
name: ha-postgres-sample
spec:
highAvailability:
enabled: false
readReplicas: 0
podDisruptionBudget:
enabled: false
Apply the change:
kubectl apply -f <name-of-yaml-file>
Now the mirror no longer exists. To verify that there is no replication happening, access the pod:
kubectl exec -it pod/ha-postgres-sample -- bash
and run:
pg_autoctl show state
The column Current State output should show single.
Enabling Pod Disruption Budget (PDB) for the HA Postgres instance
To enable Pod Disruption Budget for the HA instance, modify the highAvailability.podDisruptionBudget.enabled field by setting its value to true:
apiVersion: sql.tanzu.vmware.com/v1
kind: Postgres
metadata:
name: <postgres-instance-name>
namespace: <namespace>
spec:
highAvailability:
enabled: true
readReplicas: 1
podDisruptionBudget:
enabled: false
to:
apiVersion: sql.tanzu.vmware.com/v1
kind: Postgres
metadata:
name: <postgres-instance-name>
namespace: <namespace>
spec:
highAvailability:
enabled: true
readReplicas: 1
podDisruptionBudget:
enabled: true
Apply the change:
kubectl apply -f <name-of-yaml-file>
To check if a PDB has been created for the Postgres instance:
kubectl get pdb <postgres-instance-name> -n <namespace>
