









Troubleshoot Kubernetes deployments
Introduction
Kubernetes is the recommended way to manage containers in production. To make it even easier to work with Kubernetes, Bitnami offers:
- Stable, production-ready Helm charts to deploy popular software applications, such as WordPress, Magento, Redmine and many more, in a Kubernetes cluster
- Kubeapps, a set of tools to super-charge your Kubernetes cluster with an in-cluster deployment dashboard and out-of-the-box support for Kubeless, a Kubernetes-native Serverless Framework and SealedSecrets.
In many cases, though, you might find that your Bitnami application has not been correctly deployed to your Kubernetes cluster, or that it is not behaving the way it should. This guide provides some broad troubleshooting ideas and solutions to common problems you might encounter with your Kubernetes cluster.
How to detect
Kubernetes issues are not always very easy to detect. In some cases, errors are obvious and can be resolved easily; in others, you might find that your deployed application is not responding, but detecting the error requires you to dig deeper and run various commands to identify what went wrong.
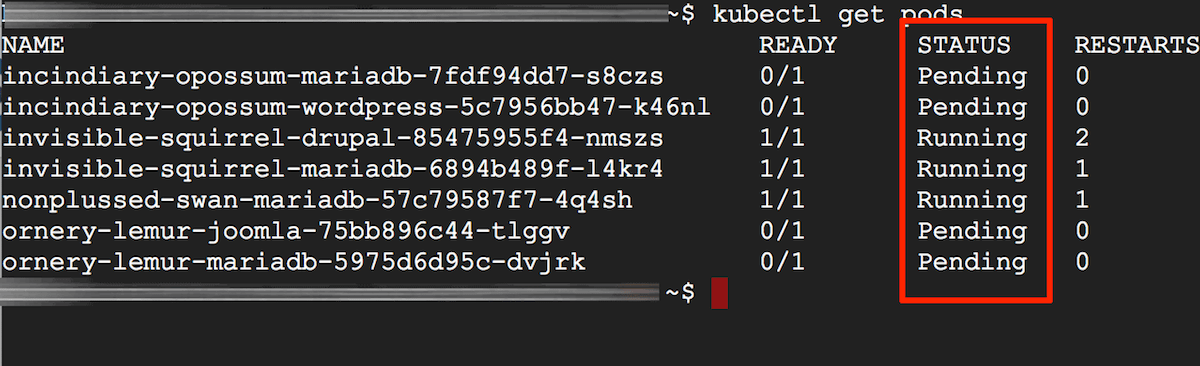
Typically, running kubectl get pods gives you a top-level overview of whether pods are running correctly, or which pods have issues. You can then use kubectl describe and kubectl logs to obtain more detailed information.
Common issues
The following are the most common issues that Bitnami users face:
- Pods in Pending, CrashLoopBackOff or Waiting state
- PVCs in Pending state
- DNS lookup failures for exposed services
- Non-responsive pods or containers
- Authentication failures
- Difficulties in finding the external IP address of a node
Troubleshooting checklist
The following checklist covers the majority of the cases described above and will help you to find and debug most Kubernetes deployment issues.
Does your pod status show Pending?
If kubectl get pods shows that your pod status is Pending or CrashLoopBackOff, this means that the pod could not be scheduled on a node. Typically, this is because of insufficient CPU or memory resources. It could also arise due to the absence of a network overlay or a volume provider. To confirm the cause, note the pod identifier from the previous command and then run the command below, replacing the POD-UID placeholder with the correct identifier:
kubectl describe pod POD-UID
The output of the command should provide information about why the pod is pending. Here's an example:
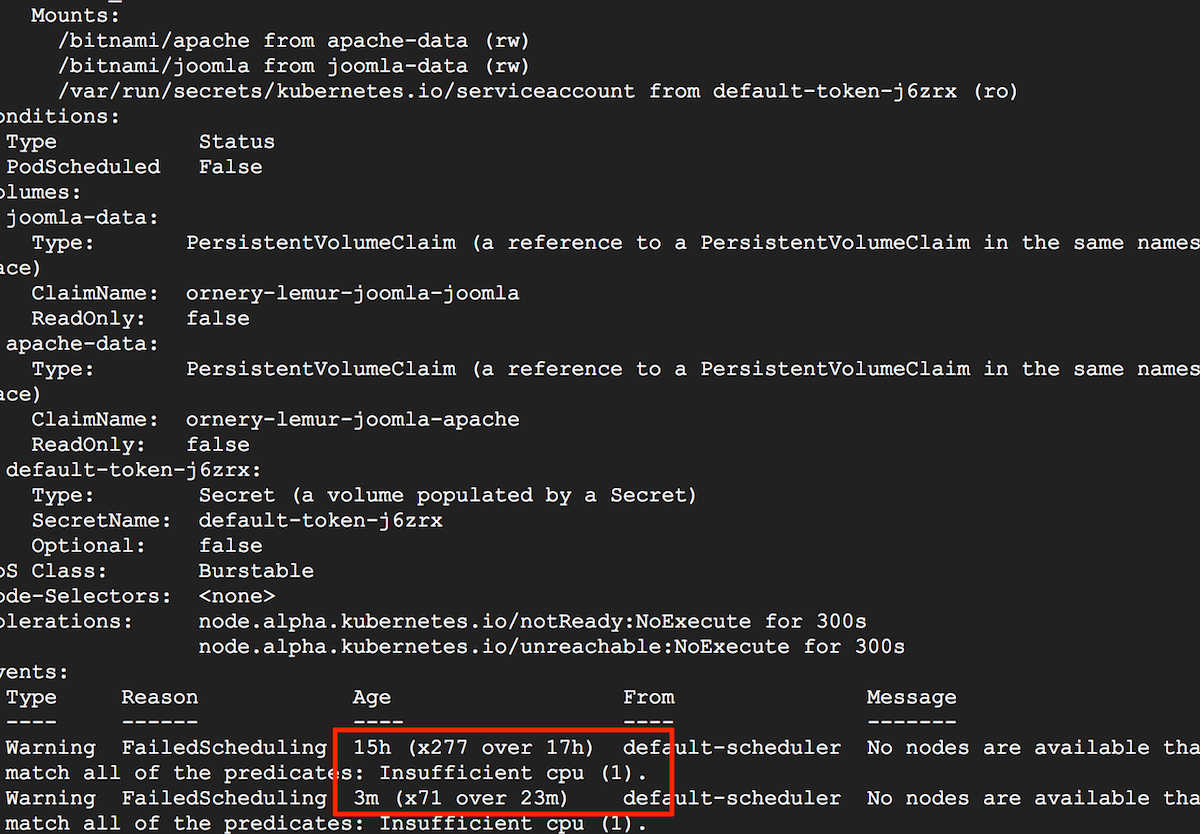
If available resources are insufficient, try freeing up existing cluster resources or adding more nodes to the cluster to increase the available cluster resources.
Does your pod status show ImagePullBackOff or ErrImagePull?
If kubectl get pods shows that your pod status is ImagePullBackOff or ErrImagePull, this means that the pod could not run because it could not pull the image. To confirm this, note the pod identifier from the previous command and then run the command below, replacing the POD-UID placeholder with the correct identifier:
kubectl describe pod POD-UID
The output of the command should provide more information about the failed pull. Check that the image name is correct and try pulling the image manually on the host using docker pull. For example, to manually pull an image from Docker Hub, use the command below:
docker pull IMAGE
Does your PVC status show Pending?
If kubectl get pvc shows that your PVC status is Pending when using a Bitnami Helm chart, this may be because your cluster does not support dynamic provisioning (such as a bare metal cluster). In this case, the pod is unable to start because the cluster is unable to fulfil the request for a persistent volume and attach it to the container.
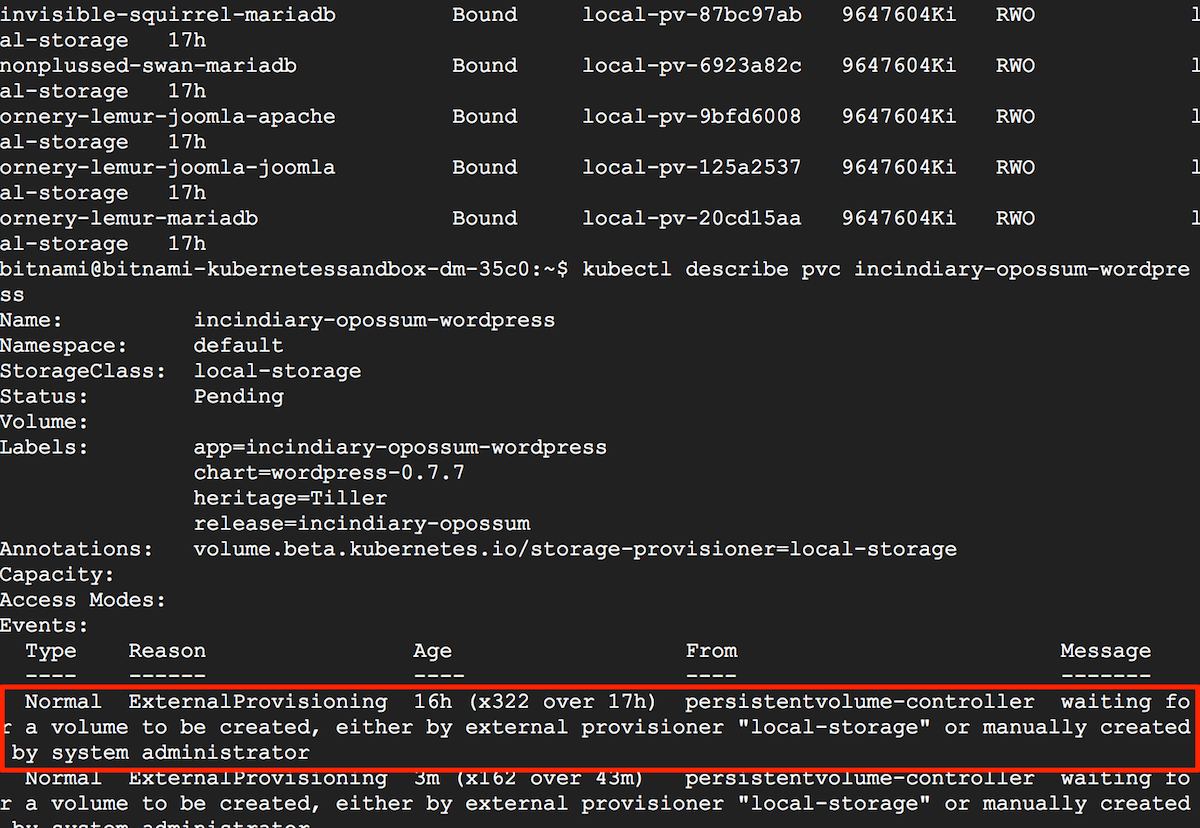
To fix this, you must manually configure some persistent volumes or set up a StorageClass resource and provisioner for dynamic volume provisioning, such as the NFS provisioner. Learn more about dynamic provisioning and storage classes.
Are you unable to look up or resolve Kubernetes service names using DNS?
This usually occurs when the service has not been properly registered. The service may be using a different namespace or may simply not be available. Try these steps:
- Check if the service name you are using is correct.
- Run these commands to check if the service is registered and the pods selected:
kubectl get svc
kubectl get endpoints
- If the service is registered, run kubectl get pods, get the UID for your pod and then run the command below. Replace the POD-UID placeholder with the pod UID and the SERVICE-NAME placeholder with the DNS name of the service. This will give you an indication if the DNS resolution is working or not.
kubectl exec -ti POD-UID nslookup SERVICE-NAME
- If the error persists, then confirm that DNS is enabled for your Kubernetes cluster. If you're using minikube, the command minikube addons list will give you a list of all enabled features. If it is disabled, enable it and try again.
Is kubectl unable to find your nodes?
When running kubectl get nodes, you may see the following error:
the server doesn't have a resource type "nodes"
This occurs because the authentication credentials are not correctly set. To resolve this, copy the configuration file /etc/kubernetes/admin.conf to ~/.kube/config in a regular user account (with sudo if necessary) and try again. This command should not be performed in the root user account.
cp /etc/kubernetes/admin.conf ~/.kube/config
Is kubectl not permitting access to certain resources?
When using kubectl, you may see the following error:
the server does not allow access to the requested resource
This typically occurs when Kubernetes Role-Based Access Control (RBAC) is enabled, the default situation from Kubernetes 1.6 onwards. To resolve this, you must create and deploy the necessary RBAC policies for users and resources. Read our RBAC guide for more information and examples.
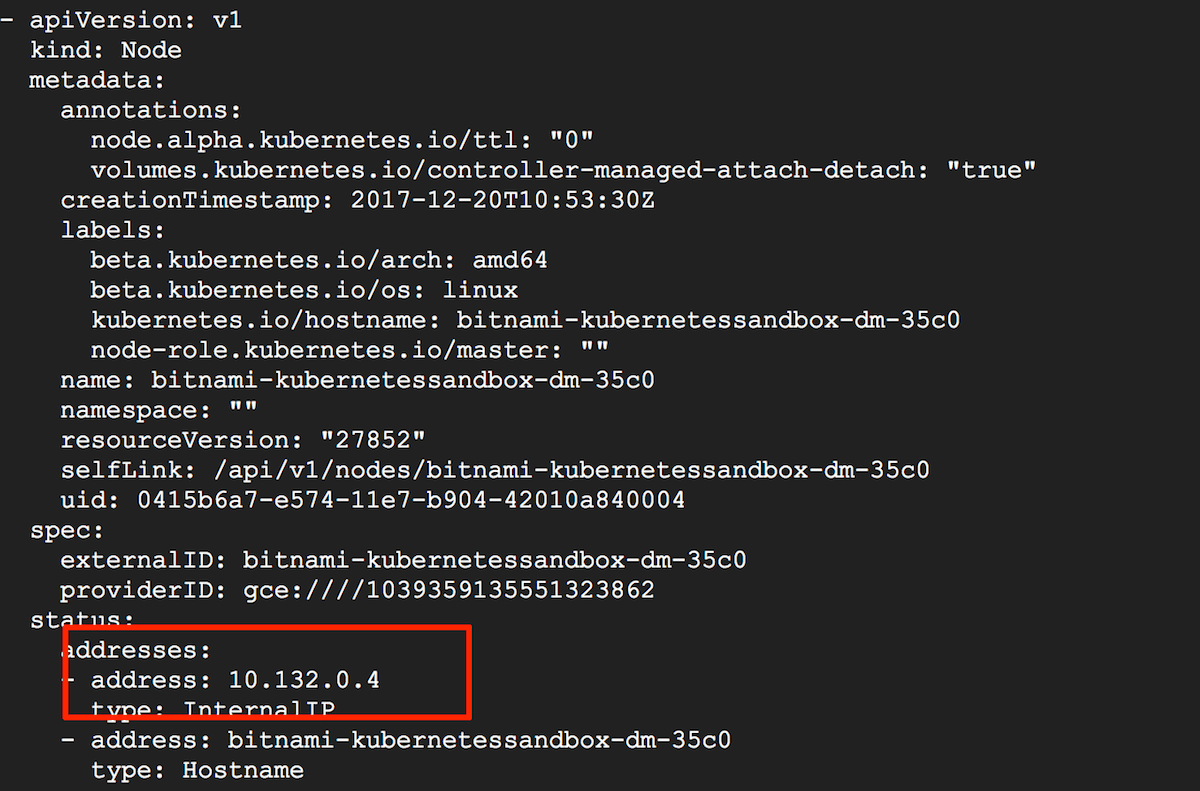
Are you unable to find the external IP address of a node?
- If using minikube, the command minikube ip will return the IP address of the node.
- If not using minikube, the command kubectl get nodes -o yaml will show you, amongst other data, the IP address of the node.
Is your pod running but not responding?
If your pod is running but appears to be non-responsive, it could be due to a failed process in the container - for example, because of an invalid configuration or insufficient storage space. To check this, you can log into the running container and check that the required processes are running.
To do this, first open a shell to the container and then, at the container shell, use ps to check for running processes:
kubectl exec -ti POD-UID -- /bin/bash
> ps ax
If the required process is not running, inspect the container logs to identify and resolve the issue.
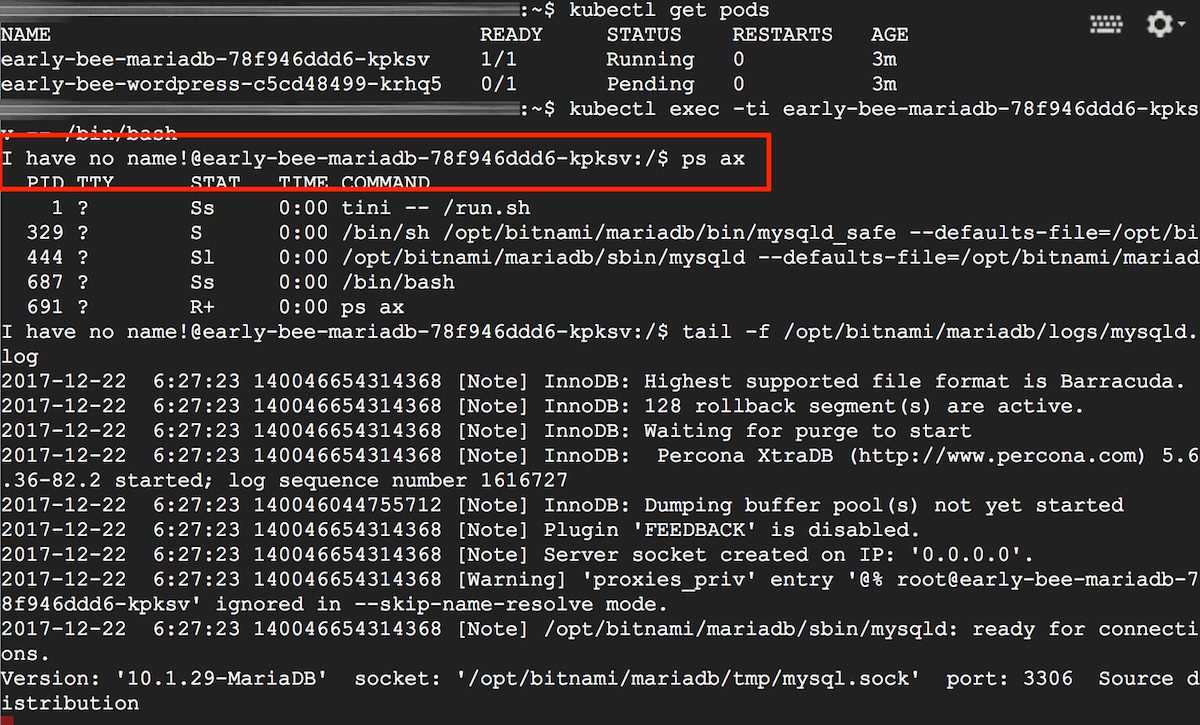
It is also helpful to look at the RESTARTS column of the kubectl get pods output to know if the pod is repeatedly being restarted and the READY column to find out if the readiness probe (health check) is executing positively.
Useful links
The following resources may be of interest to you:
- Application troubleshooting guide
- Configure RBAC in your Kubernetes cluster
- Secure Kubernetes with pod security policies or network policies
