









Abstracting service implementations behind a class across clusters
In this Services Toolkit tutorial you learn how service operators can configure a class that allows for claims to resolve to different backing implementations of a service, such as PostgreSQL, depending on which cluster the class is claimed in.
This setup allows the configuration for workloads and class claims to remain unchanged as they are promoted through environments. It also enables service operators to change the implementations of the backing services without further configuration.
About this tutorial
Target user role: Service operator
Complexity: Medium
Estimated time: 60 minutes
Topics covered: Classes, claims, claim-by-class, multicluster
Learning outcomes: The ability to abstract the implementation (for example, helm, tanzu data service, cloud) of a service (for example, RabbitMQ) across multiple clusters
Prerequisites
Before you can follow this tutorial, you need access to three separate Tanzu Application Platform clusters v1.5.0 or later. This tutorial refers to the clusters as iterate, run-test, and run-production, but you can use different names if required.
Scenario
This tutorial is centered around the following scenario.
You work at BigCorp as a service operator. BigCorp uses three separate Tanzu Application Platform clusters: iterate, run-test, and run-production. Application workloads begin on the iterate cluster, before being promoted to the run-test cluster, and then finally to the run-production cluster. The application development team have asked you for a PostgreSQL service to use with their workloads that is available on all three clusters.
The service level objectives (SLOs) for each cluster are different. You want to tailor the implementation of the PostgreSQL service to each of the clusters accordingly:
- The
iteratecluster has low level SLOs, so you want to offer an unmanaged PostgreSQL service backed by a Helm chart. - The
run-testcluster has more robust requirements, so want to offer a PostgreSQL service backed by VMware SQL with Postgres for Kubernetes. - The
run-productioncluster is critically important, so you want to use a fully managed and cloud-based PostgreSQL implementation.
You want to ensure that the differing implementations are completely opaque to development teams. They do not need to know about the inner workings of the services and must be able to keep their workloads and class claims the same as they are promoted across clusters. You want to use the claims and classes abstractions in Tanzu Application Platform to complete your task.
Concepts
This section provides a high-level overview of the elements you will use during this tutorial and how these elements fit together.
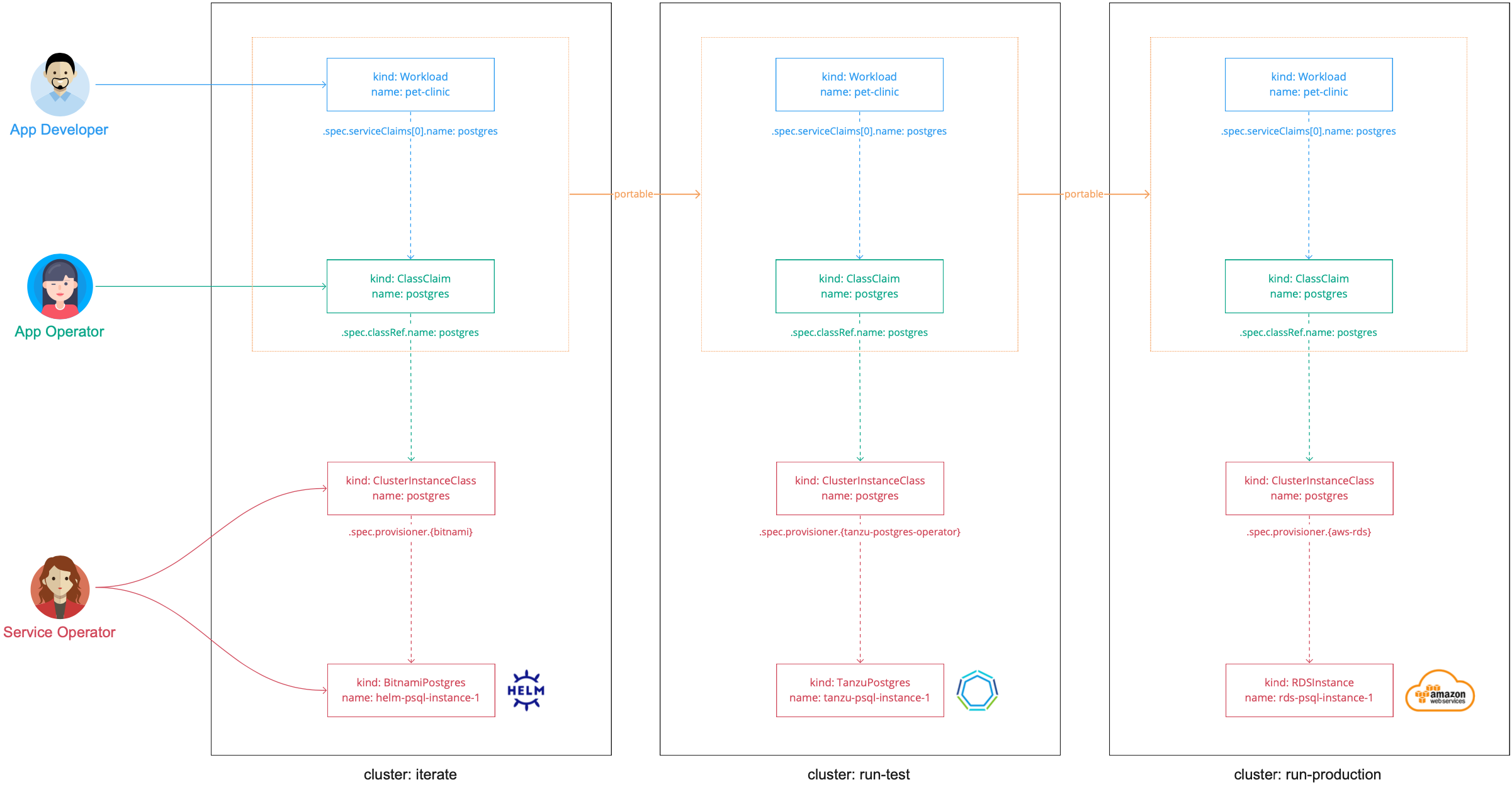
In this diagram:
- There are three clusters:
iterate,run-test, andrun-production. - In each cluster, the service operator creates a
ClusterInstanceClasscalledpostgres.- In the
iteratecluster,postgresis a provisioner-based class that uses Bitnami Services to provision Helm instances of PostgreSQL. - In the
run-testcluster,postgresis a provisioner-based class that uses VMware SQL with Postgres for Kubernetes to provision instances of PostgreSQL. - In the
run-productioncluster,postgresis a provisioner-based class that uses Amazon RDS to provision instances running in Amazon AWS RDS.
- In the
- The app operator creates a
ClassClaim. This is applied with a consuming workload.- When it is applied in
iterateit resolves to a Helm chart instance. - When it is promoted to
run-testit resolves to a VMware PostgreSQL instance. - When it is promoted to
run-productionit resolves to an Amazon AWS RDS instance.
- When it is applied in
- The definition of the
ClassClaimremains identical across the clusters, which is easier for the application development team.
ImportantThe backing service implementations and environment layouts used in this scenario are arbitrary. They are not recommendations or requirements.
Although this tutorial uses provisioner-based classes on all three clusters, you can also use a combination of provisioner-based and pool-based classes across the clusters. You might want to do this in cases where, for example, you want to allow for dynamic provisioning of service instances in the iterate cluster, but want to be more considered about the approach in the run-production cluster to ensure that workloads only connect to a specific service instance. You can achieve this by using a provisioner-based class on the iterate cluster, and an identically named pool-based class on the run-production cluster that is configured to select from a pool that consists of one service instance.
Procedure
The following steps explain how to set up a class that allows for claims to resolve to differing implementations of PostgreSQL depending on the cluster it is in.
Step 1: Set up the run-test cluster
Configure the run-test cluster for dynamic provisioning of VMware PostgreSQL service instances. To do that, see Configure dynamic provisioning of VMware SQL with Postgres for Kubernetes service instances and complete the steps in the following sections only:
- Install the Tanzu VMware Postgres Operator
- Set up the namespace
- Create a CompositeResourceDefinition
- Create a Composition
- Configure RBAC
You do not need to follow any other sections in that topic.
Step 2: Set up the run-production cluster
Configure the run-production cluster for dynamic provisioning of AWS RDS PostgreSQL service instances. To do that, see Configure Dynamic Provisioning of AWS RDS Service Instances and complete the steps in the following sections only:
- Install the AWS Provider for Crossplane
- Create a CompositeResourceDefinition
- Create a Composition
- Configure RBAC
You do not need to follow any other sections in that topic.
Step 3: Create the class
The ClusterInstanceClass acts as the abstraction fronting the differing service implementations across the different clusters. You must create a class with the same name on all three of the clusters, but the configuration of each class will be different. The ClassClaim refers to classes by name. The fact that the class name remains consistent is what allows for the ClassClaim, which the application development team creates, to remain unchanged as it is promoted across the clusters.
To create the class:
-
Configure a
ClusterInstanceClassfor theiteratecluster by creating a file namedpostgres.class.iterate-cluster.yamlwith the following contents:# postgres.class.iterate-cluster.yaml --- apiVersion: services.apps.tanzu.vmware.com/v1alpha1 kind: ClusterInstanceClass metadata: name: bigcorp-postgresql spec: description: short: PostgreSQL by BigCorp provisioner: crossplane: compositeResourceDefinition: xpostgresqlinstances.bitnami.database.tanzu.vmware.comThis class refers to the
xpostgresqlinstances.bitnami.database.tanzu.vmware.comCompositeResourceDefinition(XRD). This is installed as part of the Bitnami Services package and powers the PostgreSQL service. You are reusing the underlying XRD from a different class using the class name you want. -
Apply the file to the
iteratecluster by running:kubectl apply -f postgres.class.iterate-cluster.yaml -
Configure a
ClusterInstanceClassfor therun-testcluster by creating a file namedpostgres.class.run-test-cluster.yamlwith the following contents:# postgres.class.run-test-cluster.yaml --- apiVersion: services.apps.tanzu.vmware.com/v1alpha1 kind: ClusterInstanceClass metadata: name: bigcorp-postgresql spec: description: short: PostgreSQL by BigCorp provisioner: crossplane: compositeResourceDefinition: xpostgresqlinstances.database.tanzu.example.orgThis class is almost identical to the one for the
iteratecluster, but this class refers to thexpostgresqlinstances.database.tanzu.example.orgXRD. -
Apply the file to the
run-testcluster by running:kubectl apply -f postgres.class.run-test-cluster.yaml -
Configure a
ClusterInstanceClassfor therun-productioncluster by creating a file namedpostgres.class.run-production-cluster.yamlwith the following contents:# postgres.class.run-production-cluster.yaml --- apiVersion: services.apps.tanzu.vmware.com/v1alpha1 kind: ClusterInstanceClass metadata: name: bigcorp-postgresql spec: description: short: PostgreSQL by BigCorp provisioner: crossplane: compositeResourceDefinition: xpostgresqlinstances.database.rds.example.orgThis class is almost identical to the previous two, but this class refers to the
xpostgresqlinstances.database.rds.example.orgXRD. -
Apply the file to the
run-productioncluster by running:kubectl apply -f postgres.class.run-production-cluster.yaml
Step 4: Create and promote the workload and class claim
After configuring the clusters and classes, switch roles from service operator to application operator and developer to create the workload and class claim YAML and promote it through the three clusters.
To create and promote the workload and class claim:
-
Create a
ClassClaimby creating a file namedapp-with-postgres.yamlwith the following contents:# app-with-postgres.yaml --- apiVersion: services.apps.tanzu.vmware.com/v1alpha1 kind: ClassClaim metadata: name: postgres namespace: default spec: classRef: name: bigcorp-postgresql --- apiVersion: carto.run/v1alpha1 kind: Workload metadata: name: pet-clinic namespace: default labels: apps.tanzu.vmware.com/workload-type: web app.kubernetes.io/part-of: pet-clinic spec: params: - name: annotations value: autoscaling.knative.dev/minScale: "1" env: - name: SPRING_PROFILES_ACTIVE value: postgres serviceClaims: - name: db ref: apiVersion: services.apps.tanzu.vmware.com/v1alpha1 kind: ClassClaim name: postgres source: git: url: https://github.com/sample-accelerators/spring-petclinic ref: branch: main tag: tap-1.2 -
Apply the
app-with-postgres.yamlfile to theiteratecluster by running:kubectl apply -f app-with-postgres.yaml -
Wait for the workload to become ready and then inspect the cluster to see that the workload is bound to a Helm-based PostgreSQL service instance. Target the
iteratecluster then confirm by running:helm list -A -
Apply the
app-with-postgres.yamlfile to therun-testcluster by running:kubectl apply -f app-with-postgres.yaml -
Wait for the workload to become ready and then confirm that the workload is bound to a Tanzu-based PostgreSQL service instance. Target the
run-testcluster then confirm by running:kubectl get postgres -n tanzu-psql-service-instances -
Apply the
app-with-postgres.yamlfile to therun-productioncluster by running:kubectl apply -f app-with-postgres.yaml -
Wait for the workload to become ready and then confirm that the workload is bound to a RDS-based PostgreSQL service instance. Target the
run-productioncluster then confirm by running:kubectl get RDSInstance -A
