









Troubleshooting Supply Chain Security Tools - Store
This topic tells you how to troubleshoot known issues for Supply Chain Security Tools (SCST) - Store.
Querying by insight source returns zero CVEs even though there are CVEs in the source scan
Symptom
insight source get and other insight source commands return zero results.
Solution
You might have to include different combinations of --repo, --org, --commit because of how scan-controller populates the software bill of materials (SBOM). For more information, see Query vulnerabilities, images, and packages.
Persistent volume retains data
Symptom
If SCST - Store is deployed, deleted, and then redeployed, and the database password is changed during the redeployment, the metadata-store-db pod fails to start.
Explanation
The persistent volume that PostgreSQL uses retains old data, even though the retention policy is set to DELETE.
Solution
To redeploy the app, either use the same database password or follow these steps to erase the data on the volume.
CautionChanging the database password deletes your SCST - Store data.
- Deploy the
metadata-storeapp by usingkapp. - Verify that the
metadata-store-db-*pod fails. -
Run:
kubectl exec -it metadata-store-db-<some-id> -n metadata-store /bin/bashWhere
<some-id>is the ID generated by Kubernetes and appended to the pod name. -
Run
rm -rf /var/lib/postgresql/data/*to delete all database data.Where
/var/lib/postgresql/data/*is the path found inpostgres-db-deployment.yaml. -
Delete the
metadata-storeapp by usingkapp. - Deploy the
metadata-storeapp by usingkapp.
Missing persistent volume
Symptom
After SCST - Store is deployed, the metadata-store-db pod might fail for missing volume while postgres-db-pv-claim pvc is in the PENDING state.
Explanation
The cluster where SCST - Store is deployed does not have storageclass defined. storageclass’s provisioner is responsible for creating the persistent volume after metadata-store-db attaches postgres-db-pv-claim.
Solution
To solve:
-
Verify that your cluster has
storageclassby runningkubectl get storageclass -
Create a
storageclassin your cluster before deploying SCST - Store. For example:# This is the storageclass that Kind uses $ kubectl apply -f https://raw.githubusercontent.com/rancher/local-path-provisioner/master/deploy/local-path-storage.yaml # set the storage class as default kubectl patch storageclass local-path -p '{"metadata": {"annotations":{"storageclass.kubernetes.io/is-default-class":"true"}}}'
Builds fail because of volume errors on EKS running Kubernetes v1.23
Symptom
When installing SCST - Store on an EKS cluster or upgrading an EKS cluster to Kubernetes v1.23, the database pod shows:
running PreBind plugin "VolumeBinding": binding volumes: provisioning failed for PVC "postgres-db-pv-claim"
Explanation
CSIMigrationAWS in this Kubernetes version requires users to install the Amazon Elastic Block Store (EBS) CSI Driver to use EBS volumes. For more information, see the AWS documentation.
SCST - Store uses the default storage class, which uses EBS volumes by default on EKS.
Solution
Follow the AWS documentation to install the Amazon EBS CSI Driver before installing SCST - Store or upgrading to Kubernetes v1.23.
CA certificate expires
Symptom
The Insight CLI or Scan Controller fails to communicate with the SCST - Store and receives an error message containing the following text:
tls: failed to verify certificate: x509: certificate has expired or is not yet valid
Explanation
The CA certificate expired before the app certificate expires, which causes the error even though the app certificate is still valid. cert-manager rotates the expired CA certificate, but it does not rotate the certificates that were previously created by the expired CA certificate.
Solution
-
Delete the existing expired
cacertby running:kubectl delete secret cacert contourcert envoycert -n projectcontour -
Delete the
contour-certgenjob by running:kubectl delete job contour-certgen -n projectcontour -
Trigger reconciliation for contour by running:
kctrl package installed kick --package-install contour -n tap-install -
Learn the name of the envoy pod by running:
kubectl get pods -n projectcontourFind the pod that is named in the format
envoy-<some-random-id>. -
Use that name to restart the pods by deleting them by running:
kubectl delete pod <envoy-pod-name> -n projectcontour
Certificate Expires
Symptom
The Insight CLI or the Scan Controller fails to connect to SCST - Store.
The logs of the metadata-store-app pod show the following error:
$ kubectl logs deployment/metadata-store-app -c metadata-store-app -n metadata-store
...
2022/09/12 21:22:07 http: TLS handshake error from 127.0.0.1:35678: write tcp 127.0.0.1:9443->127.0.0.1:35678: write: broken pipe
...
or the logs of metadata-store-db show the following error:
$ kubectl logs statefulset/metadata-store-db -n metadata-store
...
2022-07-20 20:02:51.206 UTC [1] LOG: database system is ready to accept connections
2022-09-19 18:05:26.576 UTC [13097] LOG: could not accept SSL connection: sslv3 alert bad certificate
...
Explanation
cert-manager rotates the certificates, but the metadata-store and the PostgreSQL database are unaware of the change and are using the old certificates.
Solution
If TLS handshake error is in the metadata-store-app logs, delete the metadata-store-app pod by running:
kubectl delete pod metadata-store-app-xxxx -n metadata-store
Wait for it to come back up.
If could not accept SSL connection is in the metadata-store-db logs, delete the metadata-store-db pod by running:
kubectl delete pod metadata-store-db-0 -n metadata-store
Wait for it to come back up.
Database index corruption issue in SCST - Store
Symptom
The Metadata Store was unable to reconcile because the metadata-store pod reports suspected database index corruption. For example:
$ kubectl logs metadata-store-app-pod_name -n metadata-store
{“level”:“error”,“ts”:“2023-08-15T16:38:31.528115988Z”,“logger”:“MetadataStore”,“msg”:“unable to check index corruption since user is not a superuser to perform \“CREATE EXTENSION amcheck\“. Please create this extension and check for index corruption using following sql command \“SELECT bt_index_check(oid) FROM pg_class WHERE relname in (SELECT indexrelid::regclass::text FROM (SELECT indexrelid, indrelid, indcollation[i] coll FROM pg_index, generate_subscripts(indcollation, 1) g(i)) s JOIN pg_collation c ON coll=c.oid WHERE collprovider IN (‘d’, ‘c’) AND collname NOT IN (‘C’, ‘POSIX’));\“”,“hostname”:“metadata-store-app-77c9fb59c8-qplxt”}
{“level”:“error”,“ts”:“2023-08-15T16:38:31.528139637Z”,“logger”:“MetadataStore”,“msg”:“Found corrupted database indexes but unable to fix them”,“hostname”:“metadata-store-app-77c9fb59c8-qplxt”,“error”:“unable to check index corruption since user is not a superuser to perform \“CREATE EXTENSION amcheck\“. Please create this extension and check for index corruption using following sql command \“SELECT bt_index_check(oid) FROM pg_class WHERE relname in (SELECT indexrelid::regclass::text FROM (SELECT indexrelid, indrelid, indcollation[i] coll FROM pg_index, generate_subscripts(indcollation, 1) g(i)) s JOIN pg_collation c ON coll=c.oid WHERE collprovider IN (‘d’, ‘c’) AND collname NOT IN (‘C’, ‘POSIX’));\“”}
Solution
See SCST - Store Database Index Corruption.
Errors from Tanzu Developer Portal related to SCST - Store
Different Tanzu Developer Portal plug-ins use SCST - Store to display information about vulnerabilities and packages. Some errors visible in Tanzu Developer Portal are related to this connection.
An error occurred while loading data from the Metadata Store
Symptom
In the Supply Chain Choreographer plug-in, you see the error message An error occurred while loading data from the Metadata Store.
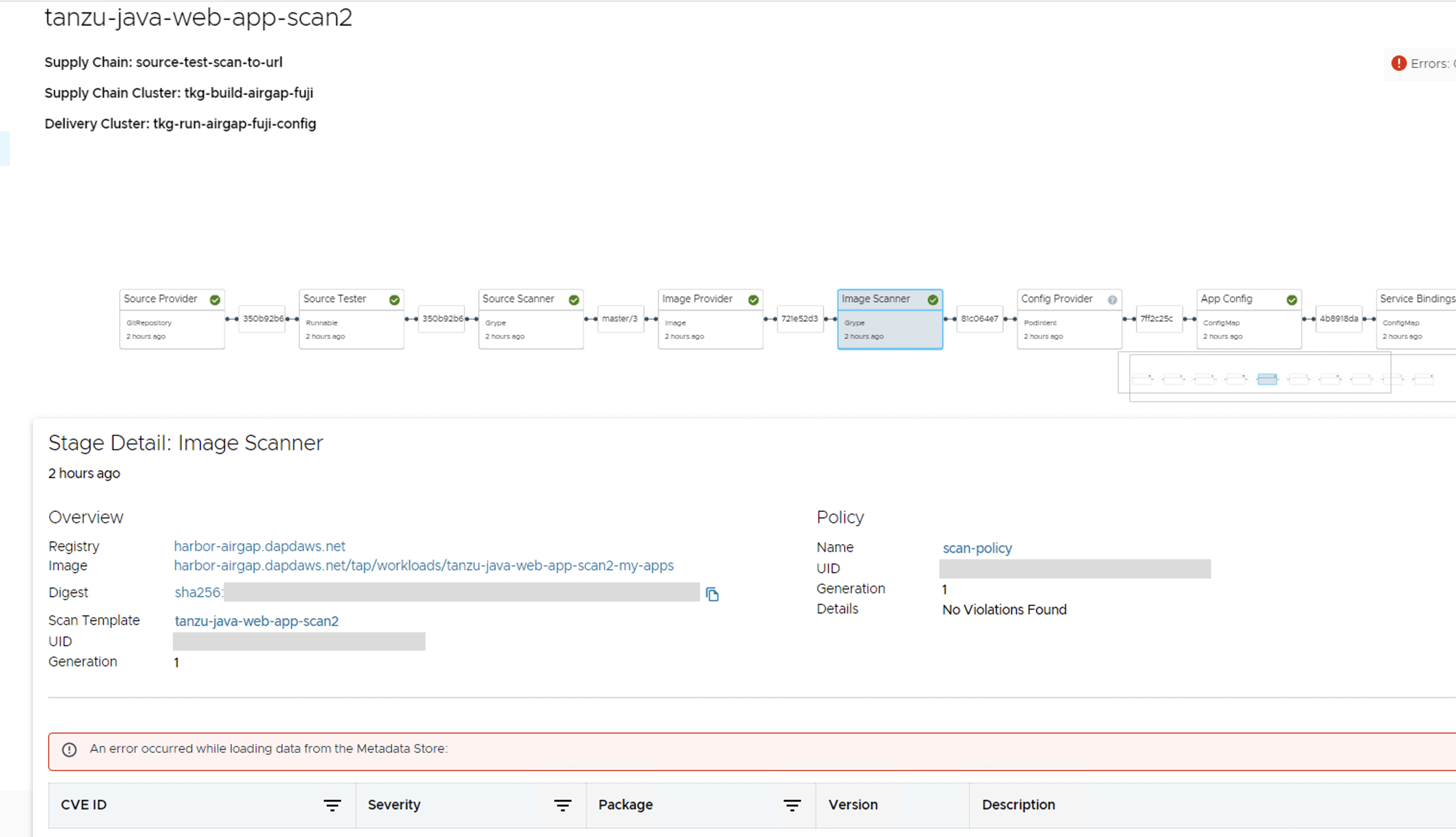
Cause
There are multiple potential causes. The most common cause is tap-values.yaml missing the configuration that enables Tanzu Developer Portal to communicate with Supply Chain Security Tools - Store.
Solution
See Supply Chain Choreographer - Enable CVE scan results for the necessary configuration to add to tap-values.yaml. After adding the configuration, update your Tanzu Application Platform deployment or Tanzu Developer Portal deployment with the new values.
