









Getting Started with Policies
What Are Policies and Why Should You Use Them
Several infrastructure changes occur in your cloud environment hourly, daily, weekly, and monthly.
- The launch of new resources
- Tracking and termination of unused or underutilized assets
- Sudden cost spikes
- Changes across the infrastructure
- Security risks
- Deviations from business guidelines
As your cloud environment grows, monitoring and governing these changes becomes increasingly challenging.
Policies are sets of rules that allow you to govern various aspects of your cloud infrastructure, such as cost, availability, security, performance, and usage. For each aspect, you can identify a desired operational state and configure policies to monitor for conditions that deviate from that state. When conditions do change, policies can take actions such as notifying you of the change or, in some cases, remediating the condition.
Policies are an effective way to eliminate noise and focus on the key aspects of your cloud infrastructure that require attention.
Policies differ in the types of actions they can take.
| Type | When to use |
|---|---|
| Standard policy | To get email notifications of broader infrastructure changes or to automate remedial actions based on a condition. |
| Rightsizing policy | To rightsize your instances or volumes by specifying underutilization thresholds. Results appear in the Health Check Pulse report. |
Anatomy of a Policy
At the core of each policy is a rule, which monitors for one or more conditions and, optionally, responds with an action.
Rule Conditions
Conditions specify thresholds for one or more of these aspects: (a) cost, (b) configuration, (c) usage, (d) performance, and (e) security.
A good way to think about building conditions is as follows:
- Identify a resource that you want to monitor, for example, an AWS S3 Bucket.
- Decide which aspect of this resource you want to measure, for example, Usage.
- Determine the measure you want to use, for example, S3 Storage GB.
Example: When S3 Storage GB increased by more than 50 GB over 3 days.
Policy evaluation periods begin and end at midnight UTC. Therefore, the evaluation period covers the last full day, but not the current unfinished day. For example, let’s consider a policy that monitors for when S3 Storage GB increases by more than 50 GB over 3 days. If today is March 15, then the policy checks for the last 3 complete days - March 12, 13, and 14.
When a policy checks for an increase or decrease over an evaluation period, the policy checks the total increase or decrease value between the start and end of the evaluation period. For example, let’s consider a policy that monitors whether AWS Billing Statement total cost has increased by more than 20% over 30 days. The policy checks whether the total cost has increased by more than 20% between the start date and end date of the evaluation period. If the total cost is $100 on the first day of the evaluation period and $130 on the last day of the evaluation period, then the total increase is greater than 20% and the policy’s action triggers.
Note that the policy action only triggers if the measure is met over the entire evaluation period. If the total cost increases by more than 20% over one day in the evaluation period, but the total cost increase between the first and last day of the evaluation period is still less than 20%, the policy action does not trigger. To create a day-over-day cost alert, you can create a second policy with an evaluation period of 1 day.
Rule Actions
Actions define how you want to respond when thresholds set by a condition or a set of conditions are violated. The following actions are possible:
- Notifications: Send an email to individual users or groups. Notifications from rule violations are recorded in the Notification Center. You can also email the owner of the resource that meets the rule criteria.
- Actions: Use VMware Tanzu CloudHealth-defined actions or configure your own actions, such as stopping and restarting instances, modifying reservations, and so on.
If the results of an evaluation period are the same as those in the previous evaluation, no actions are taken.
Rule Blocks
Blocks are combinations of rules based on an organization principle, for example, by functional cluster (Cassandra) or by department (Engineering). You can specify which type of resource each block evaluates. You can also enable and disable blocks. One or more blocks make up a policy.
By default, blocks are evaluated daily at 6:00 AM EST. If a block contains multiple rules, block evaluation stops at the rule that is violated first. The evaluation of all subsequent rules within the block is ignored.
NoteDaylight Savings Time is not taken into account when selecting the run time of the policy. To account for Daylight Savings Time, manually adjust the evaluation time as needed.
Governance Approaches with Tanzu CloudHealth Policies
Types of governance approaches and when to use them
Tanzu CloudHealth Policies differ in the types of actions they allow you to take.
| Governance Approach | Type | When to use |
|---|---|---|
| Notifications and Actions | Standard policy | To get email notifications of broader infrastructure changes and, optionally, automate remedial actions based on a condition. |
| Rightsizing | Rightsizing policy | To rightsize your instances or volumes by specifying underutilization thresholds. Results appear in the Health Check Pulse report and the rightsizing report. |
Notifications
Cost Governance
Receive alerts if the cost of one or more services in your environment has increased by more than a certain percentage for a given time period. By defining business groups using Perspectives, you can limit these alerts to certain groups. For example, you can be alerted whenever the cost of your production environment increases by 10% in the last 30 days.
Operational Governance
Receive alerts when the Tanzu CloudHealth platform finds opportunities for instance or volume rightsizing. Tanzu CloudHealth can monitor for these changes:
- Resource throughput (CPU, networking, disk, or memory) is above or below a certain percentage for a given time period.
- Aggregate throughput average of resources is above or below a certain percentage for a given time period.
- Unusual provisioning, for example, by monitoring infrastructure every hour to alert on unusual provisioning or termination of instances.
- Change in performance for instances in a given time period based on granular performance metrics data (e.g., file system size in GB).
Security and Incident Management (Beta)
Only available for AWS configurations.
In a fast-changing, distributed environment, receive notifications for security risks resulting from inadvertent or noncompliant changes to services. Tanzu CloudHealth provides the following capabilities.
- Security monitoring provided through policies.
- A default out-of-the-box security policy that incorporates best practices based on both AWS and Tanzu CloudHealth recommendations.
- Recommendations that summarize the issue, suggest an action, provide links to supporting documentation, and list the resources that are violating the policy.
- Ability to exclude specific resources from policy rules.
Actions
In addition to receiving notifications of changes in your cloud infrastructure, you can build a policy that will execute actions based on certain conditions. You can configure actions to run at a specific time and date. The following are examples of actions you can configure for AWS:
- Start instance
- Stop instance
- Reboot instance
- Terminate instance
- Purchase reserved instance
- Modify reserved instance
- Delete snapshots
- Delete volumes
- Release elastic IPs
- Run Lambda function
The following are examples of actions you can configure for Azure:
- Start Azure virtual machines
- Stop & deallocate Azure virtual machines
- Restart Azure virtual machines
- Resize Azure virtual machines
The following are examples of actions you can configure for GCP:
- Start GCP compute instances
- Stop GCP compute instances
The Tanzu CloudHealth platform can take these actions on its own or after an approver has signed off on the action.
Rightsizing
Organizations tend to provision more instances than necessary either to give themselves more headroom or because they are unaware of their performance requirements. This over provisioning can lead to exponentially higher costs. Rightsizing of volumes, instances, and VMs is an optimization technique that helps you reduce costs. But the dynamic nature of cloud infrastructures makes it difficult to perform this optimization continuously. Tanzu CloudHealth Policies help you automate the continuous optimization and reduce these costs.
AWS Volume Rightsizing
Tanzu CloudHealth analyzes usage, read throughput, and write throughput on your volumes to determine if they need to be rightsized based on performance thresholds that you specify.
For example, if a volume is attached to an instance and has very few read or write operations, the instance is either inactive or the volume is unnecessary.
AWS Instance Rightsizing
CPU utilization, memory utilization, disk utilization, and network in/out utilization of an instance determine whether it meets your performance requirements. Tanzu CloudHealth monitors these metrics over time and reports deviations from thresholds that you specify. It is common for instances to be underutilized, so you can reduce costs by ensuring that all your instances are of the right size.
Azure VM Rightsizing
Memory, CPU, and Disk utilization of a VM determine whether it meets your performance requirements. Tanzu CloudHealth evaluates the performance of individual VMs and compares it against the published performance specifications from Microsoft. This comparison produces a rightsizing score. You can use this score to make intelligent decisions around downgrading or upgrading VMs to reduce cost or improve performance.
In order to enable the rightsizing assessment, enable diagnostics on the VM or install the Tanzu CloudHealth Agent. In addition, configure a Service Principal.
Build a Policy That Sends Notifications
Build a policy that notifies one or more people of groups when specific conditions are met
A common use of policies is to inform one or more individuals about changes to your cloud infrastructure. A Standard Policy helps you set up these notifications.
Create Policy
A policy contains one or more blocks, each containing a specific rule that checks for operational conditions that you specify.
- In Setup > Governance > Policies, select New Policy > Standard Policy.
- Name your policy and write a brief description of what the policy monitors. The policy is Enabled by default and contains an empty block that is also enabled.
Associate Blocks with Resources
Blocks help you organize and manage rules within a policy, and each block is associated with a resource you want to monitor. A block can contain one or more rules, each of which can be enabled or disabled.
- Optional: Click the default block name to edit it. Naming your blocks helps you manage complex policies easily.
- From the Resource Type dropdown, select the resource that you want this block of rules to evaluate. Each resource provides a different set of aspects for building rule conditions.
- Specify when you want this block to be evaluated by clicking the calendar icon under Evaluate. If you are unsure of what interval to specify, retain the default value before you develop rules. You can change the default value later.
Configure Rules
Rules monitor for one or more conditions and, optionally, respond with an action. A default rule is created when you associate the block with a resource.
- Recommended: Click the default rule name to edit it. Use a name that is sufficiently descriptive, for example, Reaching Usage Threshold, because it is used in the notification message.
-
Specify the severity of the rule.
The severity appears on the console as well as in notification emails that are sent through the rule. If you want to create two separate notifications for conditions (e.g., Critical and Warning), define two separate Blocks.
Rules contains two sections: Conditions, which monitor changes to specific aspects, and Actions, which respond to those changes.
Build Conditions
- Click Add Condition. A dialog box for specifying criteria appears. Three criteria make up a condition, and they change based on the Resource Type you specify for the block: * Topic: The aspect of the resource that you want to monitor. * Data Type: Monitoring based on each resource or all resources of that type. * Choose a Measure: How the aspect is measured during monitoring.
- Select your criteria. Criteria are dependent on one another, and they change based on your selection in the previous dropdown.
- Build a condition based on the selected criteria. The condition is an expression that is made up one or more bold-text phrases that you can change. The phrases help you specify thresholds for the Topic that you selected.
-
Click Save Condition. You can build multiple conditions, where each condition specifies a threshold for a different aspect of your infrastructure. For example, one condition can monitor whether the average CPU usage is less than 5% and the other, whether maximum CPU usage is less than 20% for at least 1 day.
When multiple conditions define a rule, notifications are dispatched only if both conditions are met.
Add Actions
Define what happens when one or more conditions are met. Click Add Action.
| Type | When to use |
|---|---|
| Notify individuals or groups. | |
| Email Owner | Notify the IAM user who launched the resource. If the IAM user is not connected to a Tanzu CloudHealth user, notify the user who owns unassociated IAM users. |
| Actions | Initiate remedial actions defined in a previously defined automated task. |
Configure Multiple Rules
Just as you can specify multiple conditions within a rule, so too can you define multiple rules within a policy block. You can organize rules by dragging them and reordering them.
Example: You can set a policy around EC2 utilization, and choose to have multiple rules based on different conditions.
- A Critical notification called
Increase EC2 Instance Size if your EC2 Instance Average CPU is greater than 70% for at least 1 day. - A Critical notification called
Heavy EC2 CPU Utilization if your EC2 Average CPU is greater than 60% for at least 1 day.
Add Multiple Blocks
You can add multiple blocks to a policy and evaluate your infrastructure in a way that aligns with your business. With multiple blocks, you can measure multiple aspects of the same assets or, conversely, the same aspect of different assets.
Example: Consider a policy for your AWS infrastructure that monitors the utilization of your EC2 and RDS instances. You can create a policy named Instance Utilization that contains two blocks. The first block is named EC2 Utilization with its Resource Type set to AWS EC2 Instance. This policy can contain rules and conditions for EC2 Instance Average CPU being greater than 70% for at least 1 day.
You can add a second block to the same policy and name it RDS Utilization and set its Resource Type to AWS RDS Instance. Perhaps you want your RDS instances running at no higher than 70%. You can set the threshold for those instances to 60%.
Using this multiblock structure, you can measure two different assets using separate criteria, that are part of the same policy.
Save the Policy
Click Save Policy. The policy appears on the Setup > Governance > Policies page.
On this page, you can select a policy and view policy violations, edit the policy, duplicate the policy, or delete the policy.
Build a Policy That Starts or Stops a Resource
Use policies to help optimize your environment by setting specific rules that include starting and stopping an instance. Create a standard policy to automate this action, and optionally send an email when the policy is triggered.
Use policies to help optimize your environment by setting specific rules that include starting and stopping a resource. Create a standard policy to automate this action, and optionally send an email when the policy is triggered.
Prerequisites
Tanzu CloudHealth requires certain permissions to stop or start resources in your environment. This section provides information on the permissions needed for each cloud provider.
Amazon Web Services (AWS)
Configure your AWS IAM role to allow Tanzu CloudHealth to start and stop instances as follows:
- From Setup > Accounts > AWS, edit the AWS account associated with the instances.
- Expand Automation and enable Start Amazon EC2 Instances and Stop Amazon EC2 Instances.
- Save the account changes.
- Click Generate Policy and copy the policy contents to the clipboard.
- Log in to the AWS console and go to Services > IAM > Policies. Select the IAM access policy you are using for the Tanzu CloudHealth Platform.
- In the Permissions tab, open the JSON view and paste the policy you copied from the Tanzu CloudHealth platform.
Azure
Associate a custom role with each Azure Service Principal to allow Tanzu CloudHealth to start and stop virtual machines as follows:
- Go to Setup > Governance > Actions. The Set Up Azure Service Principal section lists each service principal configured in the Tanzu CloudHealth platform.
- Click the Enable button next to the service principal for which you want to enable Azure Actions. A PowerShell script customized for that service principal appears.
- By default, Tanzu CloudHealth assigns the built-in Azure Contributor role in the PowerShell script. For more information on what actions this role can perform, see Azure built-in roles.
- Run the script that Tanzu CloudHealth created for the service principal. If you have created a custom role, replace Contributor in the script with the name of the role you have created.
For more details, see Automate Azure VM Management Using Actions.
Google Cloud Provider (GCP)
Include compute.instances.stop and compute.instances.start permissions in the Google Console. You can add these permissions in one of the following ways:
- Add the start and stop action permissions to an existing IAM Policy at the organization level that is used by all the IAM users.
- Create a new IAM role at the organization level with only two permissions required for the start and stop action policy. Then, attach the newly-created IAM role at the project level with the IAM user. For the instructions to create a custom role, see Configuring GCP Accounts at the Organization Level.
- Manually add the start and stop action permissions to the IAM member at the project level.
Create Policy
- In the Tanzu CloudHealth platform, go to Setup > Governance > Policies, select New Policy > Standard Policy.
- Name the policy and add a description.
- Select the Resource type to start or stop.
- Add rules to monitor one or more conditions.
- Add an action to start or stop the resource.
- Select the Perspective Groups from the dropdown to limit the scope of the action.
- Optionally enter the email address of the user who should be notified of the status of the instances after running the start or stop action.
- Click Save Action.
Currently, AWS EC2 instances, AWS RDS instances, GCP compute instances, and Azure virtual machines are the only resource types that can be stopped or started using a policy.
Verify Policy Status
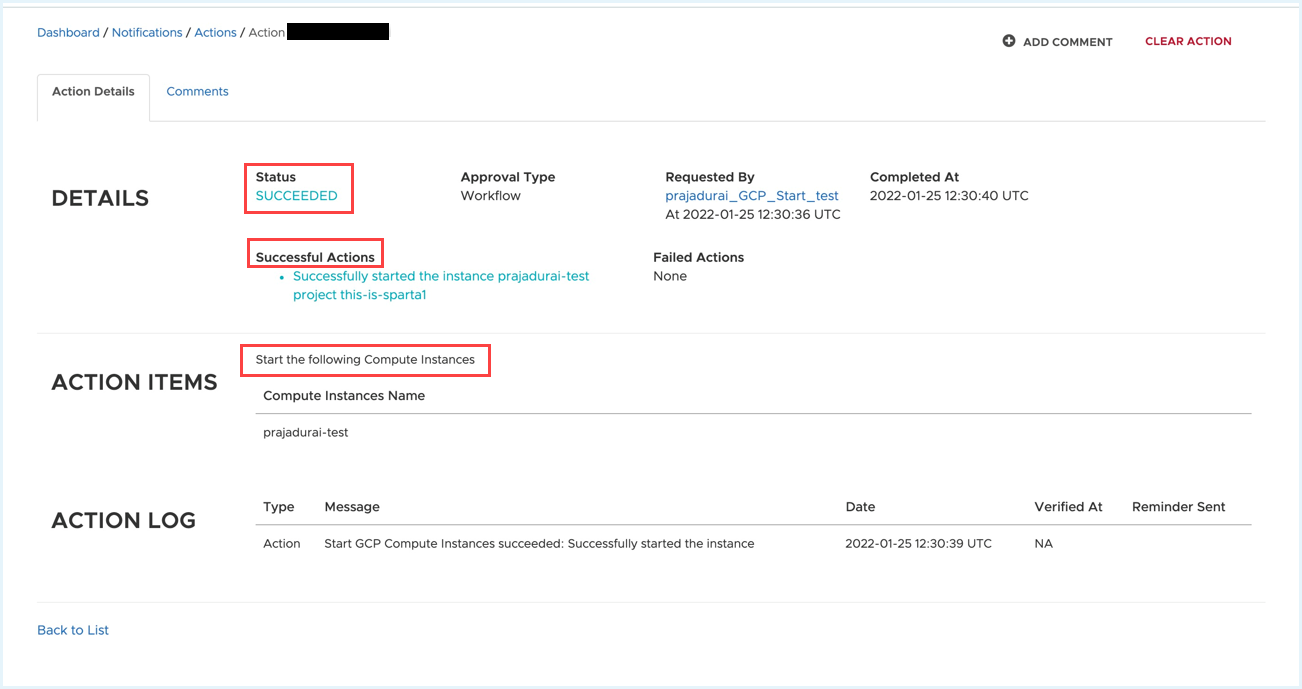
To verify the status of the policy in the Tanzu CloudHealth platform, go to Dashboard > Notification > Actions, and click the view icon. The status of the action can be:
- Succeeded: the action succeeded with all resources.
- Failed: the action failed with all resources.
- Succeeded with Failure: the action succeeded with some resources but failed for other resources.
If you choose to send an email notification, the email will include IDs of the resources that succeeded and/or failed to start or stop as of 40 minutes after the policy action was initiated. If you choose to only be notified of failures, and no actions failed, no email is sent.
The following example shows that the Start GCP Compute Instance action executed successfully:
Build Policies for Specific Business Groups
Build a policy that notifies particular business groups when specific conditions are met
As you scale your cloud environment, stakeholders across your organization will want to analyze, measure, and report across a wide variety of infrastructure services, assets, and resources. A CFO may want to evaluate by departments or cost centers; the COO, by environments or products and services; and engineering, by functions. Tanzu CloudHealth Perspectives simplify this process by giving you a framework for categorizing assets in your cloud infrastructure based on business groups in your organization.
You can introduce perspectives in your policies by associating blocks with the business groups you defined using Tanzu CloudHealth Perspectives. In this way, you can develop policies that are relevant to specific business groups in your organization. The approach also ensures that each block in a policy is only evaluated once for a given cloud asset.
Find and Categorize Assets into Groups
- In Setup > Perspectives, click New Perspectives.
- Name your perspective and add a description. Click Create Perspective and Start Building.
- In the Perspective Editor, select an asset type from the Choose an Asset Type dropdown.
- Search for assets that you want to analyze and include in the perspective using the search or categorize method.
- From the search results, add one or more groups to your perspective.
Associate Policy Blocks with Groups
- In Setup > Governance > Policies, select New Policy > Standard Policy.
- Name your policy and write a brief description of what the policy monitors. Select a perspective that you want to associate with the policy.
- Add two blocks to the policy. Associate the first block with one of the groups in the perspective and create rules within the block. In this example, warnings with varied severity levels are sent out as notifications when CPU usage increases beyond specified thresholds in the production environment.
- Associate the second policy with another group in the same perspective. Then add rules to the block. In this example, a warning with critical severity is sent out as a notification when the total cost of a resource exceed
$500for at least a month. - Optional: Click Add Catch-all Block to match and cover any perspective groups that are not covered by the other blocks in the policy.
Build a Policy That Sends Slack Messages (Beta)
Build a policy that sends Slack messages to a workspace when specific conditions are met
This feature is in private beta. If you want to enable this feature, contact the support team [email protected].
Slack is a tool that provides a digital workspace to organizations. You can use Slack to communicate across teams, collaborate on projects, and automate workflows using bots. In the context of the Tanzu CloudHealth Platform, you can use Slack to drive and create workflows via Policy Actions.
- In the Tanzu CloudHealth platform, from the left menu, select Setup > Governance > Policies.
- Click New Policy > Standard Policy. Name the policy and write a brief description of what the policy monitors.
- From the Resource Type dropdown, select the resource that you want this block of rules to evaluate.
- Click Add Condition and build your condition.
- Define what happens when one or more conditions are met. Select Add Action > Send Slack Message.
- Fill out the fields in the action form. Then click Save Action. This image shows an example Slack action that sends messages to a channel and a user.
- Click Save Policy. When the corresponding policy condition associated with the Slack action evaluates to true, Tanzu CloudHealth sends a Slack message to the specified recipients.
