









If you’re having trouble bringing an existing cluster under Tanzu Mission Control management, there are a number of steps you can take to identify and fix the problem.
Problem
You might suspect you’re having trouble attaching a cluster if:
When attaching the cluster, you see the verify connection fail.
On the cluster detail page, your cluster is stuck in the pending status
 .
.In the CLI, you see the attach operation timeout and receive a message telling you the cluster didn’t achieve the desired state.
If you’re attaching a cluster using the API, you see the status stuck in pending for longer than 7 minutes.
Cause
There are a few common reasons for cluster attach issues. Follow the solution described to identify which of these causes is the issue and help you correct it.
You might need to rerun the cluster agent installation if it failed.
You might have a resource scheduling issue preventing the cluster agent from being installed.
-
You might have a problem with the cluster connectivity or proxy configuration.
You might be attaching a windows-only cluster, and Tanzu Mission Control only supports clusters that have at least some Linux-based nodes.
You might be attaching an ARM cluster, which is currently unsupported.
You might be attaching a cluster on an unsupported version of kubernetes.
You might be attaching a cluster that isn’t CNCF conformant, and Tanzu Mission Control only supports CNCF conformant clusters.
Solution
- Check if the problem is a cluster agent installation failure.
- Verify that the cluster agent installed successfully by checking if the vmware-system-tmc namespace exists.
kubectl get namespace vmware-system-tmc
NAME STATUS AGE vmware-system-tmc Active 1m
- If the namespace doesn’t exist, try reinstalling the agent.
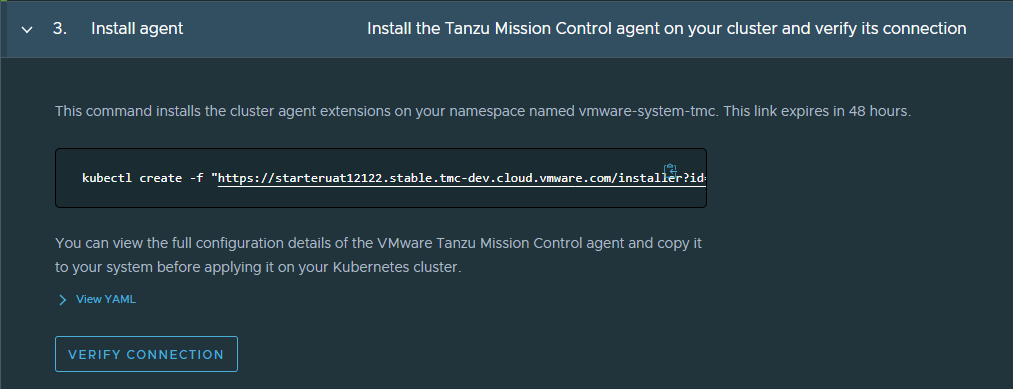
For example:
kubectl create -f "https://myorgname.tmc.cloud.vmware.com/installer?id=4...9&source=attach"
- Verify that the cluster agent installed successfully by checking if the vmware-system-tmc namespace exists.
Example
Application |
Log |
Solutions |
|---|---|---|
Extension-Updater |
failed to discover cluster metadata |
Make sure your cluster is CNCF conformant. You can check the CNCF site for a list of Platform Certified Kubernetes - Distribution Providers. |
Extension-Updater |
failed to set up manager:get Tanzu Mission Control connection |
|
Extension-Updater |
pre-flight checks failed |
Make sure your cluster is using a version of kubernetes that is supported by Tanzu Mission Control. |
What to do next
If you can’t solve the issue on your own, you can create a log bundle to share with support. Run the following commands against the cluster you’re trying to attach:
Print a report of components present in the cluster.
tmc cluster validate -hArchive the logs of all components in this cluster.
tmc cluster logs -h
See How to Get Support if you need more information about contacting them.
