









Install Prometheus and Grafana for Monitoring
This topic gives an overview of the Prometheus and Grafana packages, and how you can install them in Tanzu Kubernetes Grid (TKG) workload clusters to provide monitoring services for the cluster.
- Prometheus is an open-source systems monitoring and alerting toolkit. It can collect metrics from target clusters at specified intervals, evaluate rule expressions, display the results, and trigger alerts if certain conditions arise. For more information about Prometheus, see the Prometheus Overview. The Tanzu Kubernetes Grid implementation of Prometheus includes Alert Manager, which you can configure to notify you when certain events occur.
- Grafana is open-source visualization and analytics software. It allows you to query, visualize, alert on, and explore your metrics no matter where they are stored. In other words, Grafana provides you with tools to turn your time-series database (TSDB) data into high-quality graphs and visualizations. For more information about Grafana, see What is Grafana?.
Installation: Install Prometheus on a workload cluster in one of the following ways, based on its deployment option:
-
TKG on Supervisor:
-
Standalone management cluster: Install Prometheus in Workload Clusters Deployed by a Standalone Management Cluster
Install Grafana on a workload cluster in one of the following ways, based on its deployment option:
-
TKG on Supervisor:
-
Standalone management cluster: Install Grafana in Workload Clusters Deployed by a Standalone Management Cluster
NoteAs of v2.5, TKG does not support clusters on AWS or Azure. See the End of Support for TKG Management and Workload Clusters on AWS and Azure in the Tanzu Kubernetes Grid v2.5 Release Notes.
Prometheus, Alertmanager, and Grafana Components, Configuration, Data Values
Prometheus collects metrics from configured targets at given intervals, evaluates rule expressions, and displays the results.
Alertmanager triggers alerts if some condition is observed to be true.
Grafana lets you query, visualize, alert on, and explore your metrics no matter where they are stored.
The following diagram shows how the monitoring components on a cluster interact.
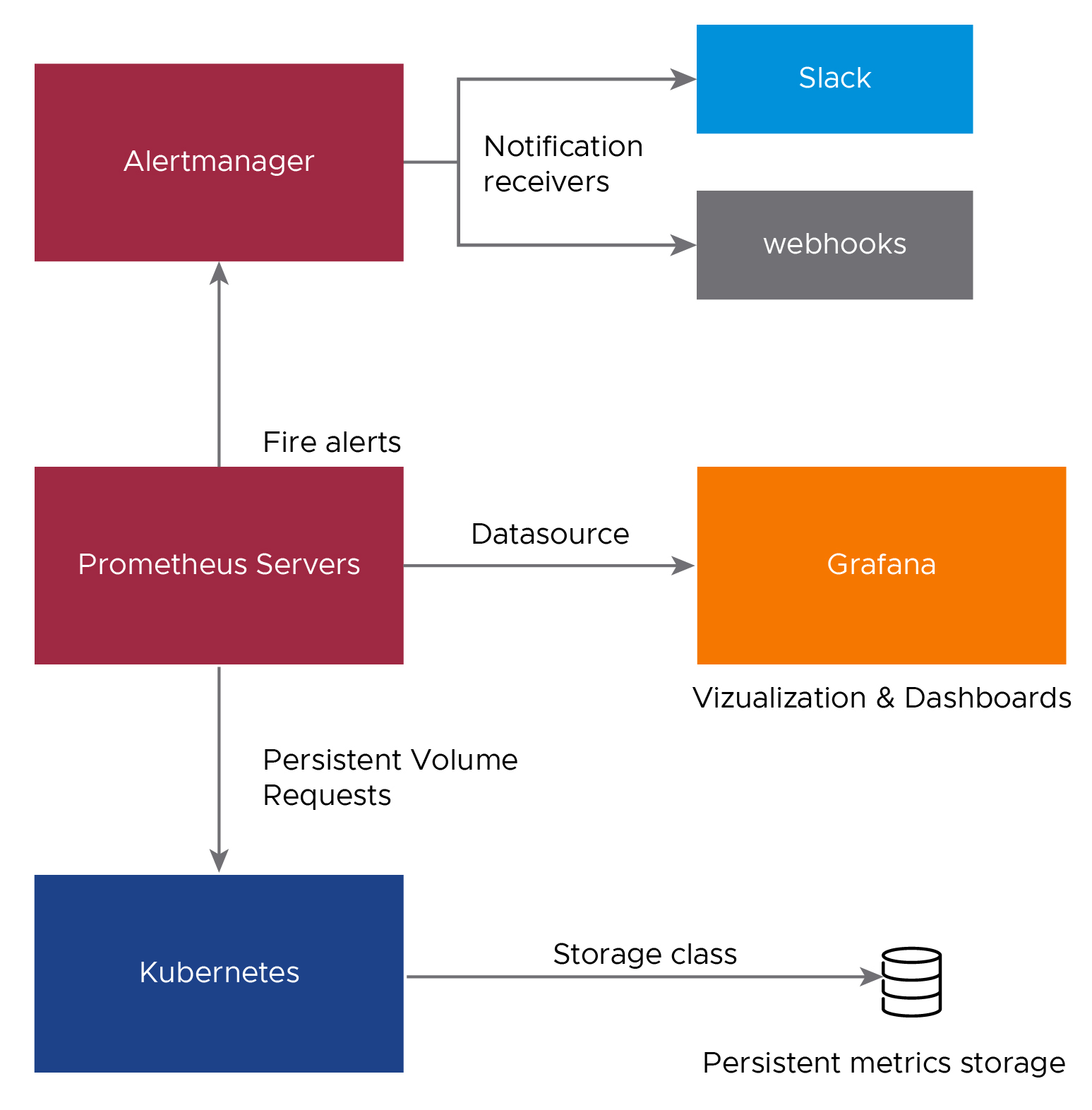
Prometheus Components
The Prometheus package installs on a TKG cluster the containers listed in the table. The package pulls the containers from the VMware public registry specified in Package Repository.
| Container | Resource Type | Replicas | Description |
|---|---|---|---|
prometheus-alertmanager |
Deployment | 1 | Handles alerts sent by client applications such as the Prometheus server. |
prometheus-cadvisor |
DaemonSet | 5 | Analyzes and exposes resource usage and performance data from running containers |
prometheus-kube-state-metrics |
Deployment | 1 | Monitors node status and capacity, replica-set compliance, pod, job, and cronjob status, resource requests and limits. |
prometheus-node-exporter |
DaemonSet | 5 | Exporter for hardware and OS metrics exposed by kernels. |
prometheus-pushgateway |
Deployment | 1 | Service that allows you to push metrics from jobs which cannot be scraped. |
prometheus-server |
Deployment | 1 | Provides core functionality, including scraping, rule processing, and alerting. |
Prometheus Data Values
Below is an example prometheus-data-values.yaml file.
Note the following:
- Ingress is enabled (ingress: enabled: true).
- Ingress is configured for URLs ending in /alertmanager/ (alertmanager_prefix:) and / (prometheus_prefix:).
- The FQDN for Prometheus is
prometheus.system.tanzu(virtual_host_fqdn:). - Supply your own custom certificate in the Ingress section (tls.crt, tls.key, ca.crt).
- The pvc for alertmanager is 2GiB. Supply the
storageClassNamefor the default storage policy. - The pvc for prometheus is 20GiB. Supply the
storageClassNamefor the vSphere storage policy.
namespace: prometheus-monitoring
alertmanager:
config:
alertmanager_yml: |
global: {}
receivers:
- name: default-receiver
templates:
- '/etc/alertmanager/templates/*.tmpl'
route:
group_interval: 5m
group_wait: 10s
receiver: default-receiver
repeat_interval: 3h
deployment:
replicas: 1
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
updateStrategy: Recreate
pvc:
accessMode: ReadWriteOnce
storage: 2Gi
storageClassName: default
service:
port: 80
targetPort: 9093
type: ClusterIP
ingress:
alertmanager_prefix: /alertmanager/
alertmanagerServicePort: 80
enabled: true
prometheus_prefix: /
prometheusServicePort: 80
tlsCertificate:
ca.crt: |
-----BEGIN CERTIFICATE-----
MIIFczCCA1ugAwIBAgIQTYJITQ3SZ4BBS9UzXfJIuTANBgkqhkiG9w0BAQsFADBM
...
w0oGuTTBfxSMKs767N3G1q5tz0mwFpIqIQtXUSmaJ+9p7IkpWcThLnyYYo1IpWm/
ZHtjzZMQVA==
-----END CERTIFICATE-----
tls.crt: |
-----BEGIN CERTIFICATE-----
MIIHxTCCBa2gAwIBAgITIgAAAAQnSpH7QfxTKAAAAAAABDANBgkqhkiG9w0BAQsF
...
YYsIjp7/f+Pk1DjzWx8JIAbzItKLucDreAmmDXqk+DrBP9LYqtmjB0n7nSErgK8G
sA3kGCJdOkI0kgF10gsinaouG2jVlwNOsw==
-----END CERTIFICATE-----
tls.key: |
-----BEGIN PRIVATE KEY-----
MIIJRAIBADANBgkqhkiG9w0BAQEFAASCCS4wggkqAgEAAoICAQDOGHT8I12KyQGS
...
l1NzswracGQIzo03zk/X3Z6P2YOea4BkZ0Iwh34wOHJnTkfEeSx6y+oSFMcFRthT
yfFCZUk/sVCc/C1a4VigczXftUGiRrTR
-----END PRIVATE KEY-----
virtual_host_fqdn: prometheus.system.tanzu
kube_state_metrics:
deployment:
replicas: 1
service:
port: 80
targetPort: 8080
telemetryPort: 81
telemetryTargetPort: 8081
type: ClusterIP
node_exporter:
daemonset:
hostNetwork: false
updatestrategy: RollingUpdate
service:
port: 9100
targetPort: 9100
type: ClusterIP
prometheus:
pspNames: "vmware-system-restricted"
config:
alerting_rules_yml: |
{}
alerts_yml: |
{}
prometheus_yml: |
global:
evaluation_interval: 1m
scrape_interval: 1m
scrape_timeout: 10s
rule_files:
- /etc/config/alerting_rules.yml
- /etc/config/recording_rules.yml
- /etc/config/alerts
- /etc/config/rules
scrape_configs:
- job_name: 'prometheus'
scrape_interval: 5s
static_configs:
- targets: ['localhost:9090']
- job_name: 'kube-state-metrics'
static_configs:
- targets: ['prometheus-kube-state-metrics.prometheus.svc.cluster.local:8080']
- job_name: 'node-exporter'
static_configs:
- targets: ['prometheus-node-exporter.prometheus.svc.cluster.local:9100']
- job_name: 'kubernetes-pods'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: kubernetes_pod_name
- job_name: kubernetes-nodes-cadvisor
kubernetes_sd_configs:
- role: node
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- replacement: kubernetes.default.svc:443
target_label: __address__
- regex: (.+)
replacement: /api/v1/nodes/$1/proxy/metrics/cadvisor
source_labels:
- __meta_kubernetes_node_name
target_label: __metrics_path__
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
- job_name: kubernetes-apiservers
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- action: keep
regex: default;kubernetes;https
source_labels:
- __meta_kubernetes_namespace
- __meta_kubernetes_service_name
- __meta_kubernetes_endpoint_port_name
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
alerting:
alertmanagers:
- scheme: http
static_configs:
- targets:
- alertmanager.prometheus.svc:80
- kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_namespace]
regex: default
action: keep
- source_labels: [__meta_kubernetes_pod_label_app]
regex: prometheus
action: keep
- source_labels: [__meta_kubernetes_pod_label_component]
regex: alertmanager
action: keep
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_probe]
regex: .*
action: keep
- source_labels: [__meta_kubernetes_pod_container_port_number]
regex:
action: drop
recording_rules_yml: |
groups:
- name: kube-apiserver.rules
interval: 3m
rules:
- expr: |2
(
(
sum(rate(apiserver_request_duration_seconds_count{job="kubernetes-apiservers",verb=~"LIST|GET"}[1d]))
-
(
(
sum(rate(apiserver_request_duration_seconds_bucket{job="kubernetes-apiservers",verb=~"LIST|GET",scope=~"resource|",le="0.1"}[1d]))
or
vector(0)
)
+
sum(rate(apiserver_request_duration_seconds_bucket{job="kubernetes-apiservers",verb=~"LIST|GET",scope="namespace",le="0.5"}[1d]))
+
sum(rate(apiserver_request_duration_seconds_bucket{job="kubernetes-apiservers",verb=~"LIST|GET",scope="cluster",le="5"}[1d]))
)
)
+
# errors
sum(rate(apiserver_request_total{job="kubernetes-apiservers",verb=~"LIST|GET",code=~"5.."}[1d]))
)
/
sum(rate(apiserver_request_total{job="kubernetes-apiservers",verb=~"LIST|GET"}[1d]))
labels:
verb: read
record: apiserver_request:burnrate1d
- expr: |2
(
(
# too slow
sum(rate(apiserver_request_duration_seconds_count{job="kubernetes-apiservers",verb=~"LIST|GET"}[1h]))
-
(
(
sum(rate(apiserver_request_duration_seconds_bucket{job="kubernetes-apiservers",verb=~"LIST|GET",scope=~"resource|",le="0.1"}[1h]))
or
vector(0)
)
+
sum(rate(apiserver_request_duration_seconds_bucket{job="kubernetes-apiservers",verb=~"LIST|GET",scope="namespace",le="0.5"}[1h]))
+
sum(rate(apiserver_request_duration_seconds_bucket{job="kubernetes-apiservers",verb=~"LIST|GET",scope="cluster",le="5"}[1h]))
)
)
+
# errors
sum(rate(apiserver_request_total{job="kubernetes-apiservers",verb=~"LIST|GET",code=~"5.."}[1h]))
)
/
sum(rate(apiserver_request_total{job="kubernetes-apiservers",verb=~"LIST|GET"}[1h]))
labels:
verb: read
record: apiserver_request:burnrate1h
- expr: |2
(
(
# too slow
sum(rate(apiserver_request_duration_seconds_count{job="kubernetes-apiservers",verb=~"LIST|GET"}[2h]))
-
(
(
sum(rate(apiserver_request_duration_seconds_bucket{job="kubernetes-apiservers",verb=~"LIST|GET",scope=~"resource|",le="0.1"}[2h]))
or
vector(0)
)
+
sum(rate(apiserver_request_duration_seconds_bucket{job="kubernetes-apiservers",verb=~"LIST|GET",scope="namespace",le="0.5"}[2h]))
+
sum(rate(apiserver_request_duration_seconds_bucket{job="kubernetes-apiservers",verb=~"LIST|GET",scope="cluster",le="5"}[2h]))
)
)
+
# errors
sum(rate(apiserver_request_total{job="kubernetes-apiservers",verb=~"LIST|GET",code=~"5.."}[2h]))
)
/
sum(rate(apiserver_request_total{job="kubernetes-apiservers",verb=~"LIST|GET"}[2h]))
labels:
verb: read
record: apiserver_request:burnrate2h
- expr: |2
(
(
# too slow
sum(rate(apiserver_request_duration_seconds_count{job="kubernetes-apiservers",verb=~"LIST|GET"}[30m]))
-
(
(
sum(rate(apiserver_request_duration_seconds_bucket{job="kubernetes-apiservers",verb=~"LIST|GET",scope=~"resource|",le="0.1"}[30m]))
or
vector(0)
)
+
sum(rate(apiserver_request_duration_seconds_bucket{job="kubernetes-apiservers",verb=~"LIST|GET",scope="namespace",le="0.5"}[30m]))
+
sum(rate(apiserver_request_duration_seconds_bucket{job="kubernetes-apiservers",verb=~"LIST|GET",scope="cluster",le="5"}[30m]))
)
)
+
# errors
sum(rate(apiserver_request_total{job="kubernetes-apiservers",verb=~"LIST|GET",code=~"5.."}[30m]))
)
/
sum(rate(apiserver_request_total{job="kubernetes-apiservers",verb=~"LIST|GET"}[30m]))
labels:
verb: read
record: apiserver_request:burnrate30m
- expr: |2
(
(
# too slow
sum(rate(apiserver_request_duration_seconds_count{job="kubernetes-apiservers",verb=~"LIST|GET"}[3d]))
-
(
(
sum(rate(apiserver_request_duration_seconds_bucket{job="kubernetes-apiservers",verb=~"LIST|GET",scope=~"resource|",le="0.1"}[3d]))
or
vector(0)
)
+
sum(rate(apiserver_request_duration_seconds_bucket{job="kubernetes-apiservers",verb=~"LIST|GET",scope="namespace",le="0.5"}[3d]))
+
sum(rate(apiserver_request_duration_seconds_bucket{job="kubernetes-apiservers",verb=~"LIST|GET",scope="cluster",le="5"}[3d]))
)
)
+
# errors
sum(rate(apiserver_request_total{job="kubernetes-apiservers",verb=~"LIST|GET",code=~"5.."}[3d]))
)
/
sum(rate(apiserver_request_total{job="kubernetes-apiservers",verb=~"LIST|GET"}[3d]))
labels:
verb: read
record: apiserver_request:burnrate3d
- expr: |2
(
(
# too slow
sum(rate(apiserver_request_duration_seconds_count{job="kubernetes-apiservers",verb=~"LIST|GET"}[5m]))
-
(
(
sum(rate(apiserver_request_duration_seconds_bucket{job="kubernetes-apiservers",verb=~"LIST|GET",scope=~"resource|",le="0.1"}[5m]))
or
vector(0)
)
+
sum(rate(apiserver_request_duration_seconds_bucket{job="kubernetes-apiservers",verb=~"LIST|GET",scope="namespace",le="0.5"}[5m]))
+
sum(rate(apiserver_request_duration_seconds_bucket{job="kubernetes-apiservers",verb=~"LIST|GET",scope="cluster",le="5"}[5m]))
)
)
+
# errors
sum(rate(apiserver_request_total{job="kubernetes-apiservers",verb=~"LIST|GET",code=~"5.."}[5m]))
)
/
sum(rate(apiserver_request_total{job="kubernetes-apiservers",verb=~"LIST|GET"}[5m]))
labels:
verb: read
record: apiserver_request:burnrate5m
- expr: |2
(
(
# too slow
sum(rate(apiserver_request_duration_seconds_count{job="kubernetes-apiservers",verb=~"LIST|GET"}[6h]))
-
(
(
sum(rate(apiserver_request_duration_seconds_bucket{job="kubernetes-apiservers",verb=~"LIST|GET",scope=~"resource|",le="0.1"}[6h]))
or
vector(0)
)
+
sum(rate(apiserver_request_duration_seconds_bucket{job="kubernetes-apiservers",verb=~"LIST|GET",scope="namespace",le="0.5"}[6h]))
+
sum(rate(apiserver_request_duration_seconds_bucket{job="kubernetes-apiservers",verb=~"LIST|GET",scope="cluster",le="5"}[6h]))
)
)
+
# errors
sum(rate(apiserver_request_total{job="kubernetes-apiservers",verb=~"LIST|GET",code=~"5.."}[6h]))
)
/
sum(rate(apiserver_request_total{job="kubernetes-apiservers",verb=~"LIST|GET"}[6h]))
labels:
verb: read
record: apiserver_request:burnrate6h
- expr: |2
(
(
# too slow
sum(rate(apiserver_request_duration_seconds_count{job="kubernetes-apiservers",verb=~"POST|PUT|PATCH|DELETE"}[1d]))
-
sum(rate(apiserver_request_duration_seconds_bucket{job="kubernetes-apiservers",verb=~"POST|PUT|PATCH|DELETE",le="1"}[1d]))
)
+
sum(rate(apiserver_request_total{job="kubernetes-apiservers",verb=~"POST|PUT|PATCH|DELETE",code=~"5.."}[1d]))
)
/
sum(rate(apiserver_request_total{job="kubernetes-apiservers",verb=~"POST|PUT|PATCH|DELETE"}[1d]))
labels:
verb: write
record: apiserver_request:burnrate1d
- expr: |2
(
(
# too slow
sum(rate(apiserver_request_duration_seconds_count{job="kubernetes-apiservers",verb=~"POST|PUT|PATCH|DELETE"}[1h]))
-
sum(rate(apiserver_request_duration_seconds_bucket{job="kubernetes-apiservers",verb=~"POST|PUT|PATCH|DELETE",le="1"}[1h]))
)
+
sum(rate(apiserver_request_total{job="kubernetes-apiservers",verb=~"POST|PUT|PATCH|DELETE",code=~"5.."}[1h]))
)
/
sum(rate(apiserver_request_total{job="kubernetes-apiservers",verb=~"POST|PUT|PATCH|DELETE"}[1h]))
labels:
verb: write
record: apiserver_request:burnrate1h
- expr: |2
(
(
# too slow
sum(rate(apiserver_request_duration_seconds_count{job="kubernetes-apiservers",verb=~"POST|PUT|PATCH|DELETE"}[2h]))
-
sum(rate(apiserver_request_duration_seconds_bucket{job="kubernetes-apiservers",verb=~"POST|PUT|PATCH|DELETE",le="1"}[2h]))
)
+
sum(rate(apiserver_request_total{job="kubernetes-apiservers",verb=~"POST|PUT|PATCH|DELETE",code=~"5.."}[2h]))
)
/
sum(rate(apiserver_request_total{job="kubernetes-apiservers",verb=~"POST|PUT|PATCH|DELETE"}[2h]))
labels:
verb: write
record: apiserver_request:burnrate2h
- expr: |2
(
(
# too slow
sum(rate(apiserver_request_duration_seconds_count{job="kubernetes-apiservers",verb=~"POST|PUT|PATCH|DELETE"}[30m]))
-
sum(rate(apiserver_request_duration_seconds_bucket{job="kubernetes-apiservers",verb=~"POST|PUT|PATCH|DELETE",le="1"}[30m]))
)
+
sum(rate(apiserver_request_total{job="kubernetes-apiservers",verb=~"POST|PUT|PATCH|DELETE",code=~"5.."}[30m]))
)
/
sum(rate(apiserver_request_total{job="kubernetes-apiservers",verb=~"POST|PUT|PATCH|DELETE"}[30m]))
labels:
verb: write
record: apiserver_request:burnrate30m
- expr: |2
(
(
# too slow
sum(rate(apiserver_request_duration_seconds_count{job="kubernetes-apiservers",verb=~"POST|PUT|PATCH|DELETE"}[3d]))
-
sum(rate(apiserver_request_duration_seconds_bucket{job="kubernetes-apiservers",verb=~"POST|PUT|PATCH|DELETE",le="1"}[3d]))
)
+
sum(rate(apiserver_request_total{job="kubernetes-apiservers",verb=~"POST|PUT|PATCH|DELETE",code=~"5.."}[3d]))
)
/
sum(rate(apiserver_request_total{job="kubernetes-apiservers",verb=~"POST|PUT|PATCH|DELETE"}[3d]))
labels:
verb: write
record: apiserver_request:burnrate3d
- expr: |2
(
(
# too slow
sum(rate(apiserver_request_duration_seconds_count{job="kubernetes-apiservers",verb=~"POST|PUT|PATCH|DELETE"}[5m]))
-
sum(rate(apiserver_request_duration_seconds_bucket{job="kubernetes-apiservers",verb=~"POST|PUT|PATCH|DELETE",le="1"}[5m]))
)
+
sum(rate(apiserver_request_total{job="kubernetes-apiservers",verb=~"POST|PUT|PATCH|DELETE",code=~"5.."}[5m]))
)
/
sum(rate(apiserver_request_total{job="kubernetes-apiservers",verb=~"POST|PUT|PATCH|DELETE"}[5m]))
labels:
verb: write
record: apiserver_request:burnrate5m
- expr: |2
(
(
# too slow
sum(rate(apiserver_request_duration_seconds_count{job="kubernetes-apiservers",verb=~"POST|PUT|PATCH|DELETE"}[6h]))
-
sum(rate(apiserver_request_duration_seconds_bucket{job="kubernetes-apiservers",verb=~"POST|PUT|PATCH|DELETE",le="1"}[6h]))
)
+
sum(rate(apiserver_request_total{job="kubernetes-apiservers",verb=~"POST|PUT|PATCH|DELETE",code=~"5.."}[6h]))
)
/
sum(rate(apiserver_request_total{job="kubernetes-apiservers",verb=~"POST|PUT|PATCH|DELETE"}[6h]))
labels:
verb: write
record: apiserver_request:burnrate6h
- expr: |
sum by (code,resource) (rate(apiserver_request_total{job="kubernetes-apiservers",verb=~"LIST|GET"}[5m]))
labels:
verb: read
record: code_resource:apiserver_request_total:rate5m
- expr: |
sum by (code,resource) (rate(apiserver_request_total{job="kubernetes-apiservers",verb=~"POST|PUT|PATCH|DELETE"}[5m]))
labels:
verb: write
record: code_resource:apiserver_request_total:rate5m
- expr: |
histogram_quantile(0.99, sum by (le, resource) (rate(apiserver_request_duration_seconds_bucket{job="kubernetes-apiservers",verb=~"LIST|GET"}[5m]))) > 0
labels:
quantile: "0.99"
verb: read
record: cluster_quantile:apiserver_request_duration_seconds:histogram_quantile
- expr: |
histogram_quantile(0.99, sum by (le, resource) (rate(apiserver_request_duration_seconds_bucket{job="kubernetes-apiservers",verb=~"POST|PUT|PATCH|DELETE"}[5m]))) > 0
labels:
quantile: "0.99"
verb: write
record: cluster_quantile:apiserver_request_duration_seconds:histogram_quantile
- expr: |2
sum(rate(apiserver_request_duration_seconds_sum{subresource!="log",verb!~"LIST|WATCH|WATCHLIST|DELETECOLLECTION|PROXY|CONNECT"}[5m])) without(instance, pod)
/
sum(rate(apiserver_request_duration_seconds_count{subresource!="log",verb!~"LIST|WATCH|WATCHLIST|DELETECOLLECTION|PROXY|CONNECT"}[5m])) without(instance, pod)
record: cluster:apiserver_request_duration_seconds:mean5m
- expr: |
histogram_quantile(0.99, sum(rate(apiserver_request_duration_seconds_bucket{job="kubernetes-apiservers",subresource!="log",verb!~"LIST|WATCH|WATCHLIST|DELETECOLLECTION|PROXY|CONNECT"}[5m])) without(instance, pod))
labels:
quantile: "0.99"
record: cluster_quantile:apiserver_request_duration_seconds:histogram_quantile
- expr: |
histogram_quantile(0.9, sum(rate(apiserver_request_duration_seconds_bucket{job="kubernetes-apiservers",subresource!="log",verb!~"LIST|WATCH|WATCHLIST|DELETECOLLECTION|PROXY|CONNECT"}[5m])) without(instance, pod))
labels:
quantile: "0.9"
record: cluster_quantile:apiserver_request_duration_seconds:histogram_quantile
- expr: |
histogram_quantile(0.5, sum(rate(apiserver_request_duration_seconds_bucket{job="kubernetes-apiservers",subresource!="log",verb!~"LIST|WATCH|WATCHLIST|DELETECOLLECTION|PROXY|CONNECT"}[5m])) without(instance, pod))
labels:
quantile: "0.5"
record: cluster_quantile:apiserver_request_duration_seconds:histogram_quantile
- interval: 3m
name: kube-apiserver-availability.rules
rules:
- expr: |2
1 - (
(
# write too slow
sum(increase(apiserver_request_duration_seconds_count{verb=~"POST|PUT|PATCH|DELETE"}[30d]))
-
sum(increase(apiserver_request_duration_seconds_bucket{verb=~"POST|PUT|PATCH|DELETE",le="1"}[30d]))
) +
(
# read too slow
sum(increase(apiserver_request_duration_seconds_count{verb=~"LIST|GET"}[30d]))
-
(
(
sum(increase(apiserver_request_duration_seconds_bucket{verb=~"LIST|GET",scope=~"resource|",le="0.1"}[30d]))
or
vector(0)
)
+
sum(increase(apiserver_request_duration_seconds_bucket{verb=~"LIST|GET",scope="namespace",le="0.5"}[30d]))
+
sum(increase(apiserver_request_duration_seconds_bucket{verb=~"LIST|GET",scope="cluster",le="5"}[30d]))
)
) +
# errors
sum(code:apiserver_request_total:increase30d{code=~"5.."} or vector(0))
)
/
sum(code:apiserver_request_total:increase30d)
labels:
verb: all
record: apiserver_request:availability30d
- expr: |2
1 - (
sum(increase(apiserver_request_duration_seconds_count{job="kubernetes-apiservers",verb=~"LIST|GET"}[30d]))
-
(
# too slow
(
sum(increase(apiserver_request_duration_seconds_bucket{job="kubernetes-apiservers",verb=~"LIST|GET",scope=~"resource|",le="0.1"}[30d]))
or
vector(0)
)
+
sum(increase(apiserver_request_duration_seconds_bucket{job="kubernetes-apiservers",verb=~"LIST|GET",scope="namespace",le="0.5"}[30d]))
+
sum(increase(apiserver_request_duration_seconds_bucket{job="kubernetes-apiservers",verb=~"LIST|GET",scope="cluster",le="5"}[30d]))
)
+
# errors
sum(code:apiserver_request_total:increase30d{verb="read",code=~"5.."} or vector(0))
)
/
sum(code:apiserver_request_total:increase30d{verb="read"})
labels:
verb: read
record: apiserver_request:availability30d
- expr: |2
1 - (
(
# too slow
sum(increase(apiserver_request_duration_seconds_count{verb=~"POST|PUT|PATCH|DELETE"}[30d]))
-
sum(increase(apiserver_request_duration_seconds_bucket{verb=~"POST|PUT|PATCH|DELETE",le="1"}[30d]))
)
+
# errors
sum(code:apiserver_request_total:increase30d{verb="write",code=~"5.."} or vector(0))
)
/
sum(code:apiserver_request_total:increase30d{verb="write"})
labels:
verb: write
record: apiserver_request:availability30d
- expr: |
sum by (code, verb) (increase(apiserver_request_total{job="kubernetes-apiservers",verb="LIST",code=~"2.."}[30d]))
record: code_verb:apiserver_request_total:increase30d
- expr: |
sum by (code, verb) (increase(apiserver_request_total{job="kubernetes-apiservers",verb="GET",code=~"2.."}[30d]))
record: code_verb:apiserver_request_total:increase30d
- expr: |
sum by (code, verb) (increase(apiserver_request_total{job="kubernetes-apiservers",verb="POST",code=~"2.."}[30d]))
record: code_verb:apiserver_request_total:increase30d
- expr: |
sum by (code, verb) (increase(apiserver_request_total{job="kubernetes-apiservers",verb="PUT",code=~"2.."}[30d]))
record: code_verb:apiserver_request_total:increase30d
- expr: |
sum by (code, verb) (increase(apiserver_request_total{job="kubernetes-apiservers",verb="PATCH",code=~"2.."}[30d]))
record: code_verb:apiserver_request_total:increase30d
- expr: |
sum by (code, verb) (increase(apiserver_request_total{job="kubernetes-apiservers",verb="DELETE",code=~"2.."}[30d]))
record: code_verb:apiserver_request_total:increase30d
- expr: |
sum by (code, verb) (increase(apiserver_request_total{job="kubernetes-apiservers",verb="LIST",code=~"3.."}[30d]))
record: code_verb:apiserver_request_total:increase30d
- expr: |
sum by (code, verb) (increase(apiserver_request_total{job="kubernetes-apiservers",verb="GET",code=~"3.."}[30d]))
record: code_verb:apiserver_request_total:increase30d
- expr: |
sum by (code, verb) (increase(apiserver_request_total{job="kubernetes-apiservers",verb="POST",code=~"3.."}[30d]))
record: code_verb:apiserver_request_total:increase30d
- expr: |
sum by (code, verb) (increase(apiserver_request_total{job="kubernetes-apiservers",verb="PUT",code=~"3.."}[30d]))
record: code_verb:apiserver_request_total:increase30d
- expr: |
sum by (code, verb) (increase(apiserver_request_total{job="kubernetes-apiservers",verb="PATCH",code=~"3.."}[30d]))
record: code_verb:apiserver_request_total:increase30d
- expr: |
sum by (code, verb) (increase(apiserver_request_total{job="kubernetes-apiservers",verb="DELETE",code=~"3.."}[30d]))
record: code_verb:apiserver_request_total:increase30d
- expr: |
sum by (code, verb) (increase(apiserver_request_total{job="kubernetes-apiservers",verb="LIST",code=~"4.."}[30d]))
record: code_verb:apiserver_request_total:increase30d
- expr: |
sum by (code, verb) (increase(apiserver_request_total{job="kubernetes-apiservers",verb="GET",code=~"4.."}[30d]))
record: code_verb:apiserver_request_total:increase30d
- expr: |
sum by (code, verb) (increase(apiserver_request_total{job="kubernetes-apiservers",verb="POST",code=~"4.."}[30d]))
record: code_verb:apiserver_request_total:increase30d
- expr: |
sum by (code, verb) (increase(apiserver_request_total{job="kubernetes-apiservers",verb="PUT",code=~"4.."}[30d]))
record: code_verb:apiserver_request_total:increase30d
- expr: |
sum by (code, verb) (increase(apiserver_request_total{job="kubernetes-apiservers",verb="PATCH",code=~"4.."}[30d]))
record: code_verb:apiserver_request_total:increase30d
- expr: |
sum by (code, verb) (increase(apiserver_request_total{job="kubernetes-apiservers",verb="DELETE",code=~"4.."}[30d]))
record: code_verb:apiserver_request_total:increase30d
- expr: |
sum by (code, verb) (increase(apiserver_request_total{job="kubernetes-apiservers",verb="LIST",code=~"5.."}[30d]))
record: code_verb:apiserver_request_total:increase30d
- expr: |
sum by (code, verb) (increase(apiserver_request_total{job="kubernetes-apiservers",verb="GET",code=~"5.."}[30d]))
record: code_verb:apiserver_request_total:increase30d
- expr: |
sum by (code, verb) (increase(apiserver_request_total{job="kubernetes-apiservers",verb="POST",code=~"5.."}[30d]))
record: code_verb:apiserver_request_total:increase30d
- expr: |
sum by (code, verb) (increase(apiserver_request_total{job="kubernetes-apiservers",verb="PUT",code=~"5.."}[30d]))
record: code_verb:apiserver_request_total:increase30d
- expr: |
sum by (code, verb) (increase(apiserver_request_total{job="kubernetes-apiservers",verb="PATCH",code=~"5.."}[30d]))
record: code_verb:apiserver_request_total:increase30d
- expr: |
sum by (code, verb) (increase(apiserver_request_total{job="kubernetes-apiservers",verb="DELETE",code=~"5.."}[30d]))
record: code_verb:apiserver_request_total:increase30d
- expr: |
sum by (code) (code_verb:apiserver_request_total:increase30d{verb=~"LIST|GET"})
labels:
verb: read
record: code:apiserver_request_total:increase30d
- expr: |
sum by (code) (code_verb:apiserver_request_total:increase30d{verb=~"POST|PUT|PATCH|DELETE"})
labels:
verb: write
record: code:apiserver_request_total:increase30d
rules_yml: |
{}
deployment:
configmapReload:
containers:
args:
- --volume-dir=/etc/config
- --webhook-url=http://127.0.0.1:9090/-/reload
containers:
args:
- --storage.tsdb.retention.time=42d
- --config.file=/etc/config/prometheus.yml
- --storage.tsdb.path=/data
- --web.console.libraries=/etc/prometheus/console_libraries
- --web.console.templates=/etc/prometheus/consoles
- --web.enable-lifecycle
replicas: 1
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
updateStrategy: Recreate
pvc:
accessMode: ReadWriteOnce
storage: 20Gi
storageClassName: default
service:
port: 80
targetPort: 9090
type: ClusterIP
pushgateway:
deployment:
replicas: 1
service:
port: 9091
targetPort: 9091
type: ClusterIP
Prometheus Configuration Parameters (TKG on Supervisor)
The Prometheus configuration is set in the prometheus-data-values.yaml file. The table lists and describes the available parameters.
| Parameter | Description | Type | Default |
|---|---|---|---|
| monitoring.namespace | Namespace where Prometheus will be deployed | string | tanzu-system-monitoring |
| monitoring.create_namespace | The flag indicates whether to create the namespace specified by monitoring.namespace | boolean | false |
| monitoring.prometheus_server.config.prometheus_yaml | Kubernetes cluster monitor config details to be passed to Prometheus | yaml file | prometheus.yaml |
| monitoring.prometheus_server.config.alerting_rules_yaml | Detailed alert rules defined in Prometheus | yaml file | alerting_rules.yaml |
| monitoring.prometheus_server.config.recording_rules_yaml | Detailed record rules defined in Prometheus | yaml file | recording_rules.yaml |
| monitoring.prometheus_server.service.type | Type of service to expose Prometheus. Supported Values: ClusterIP | string | ClusterIP |
| monitoring.prometheus_server.enable_alerts.kubernetes_api | Enable SLO alerting for the Kubernetes API in Prometheus | boolean | true |
| monitoring.prometheus_server.sc.aws_type | AWS type defined for storageclass on AWS | string | gp2 |
| monitoring.prometheus_server.sc.aws_fsType | AWS file system type defined for storageclass on AWS | string | ext4 |
| monitoring.prometheus_server.sc.allowVolumeExpansion | Define if volume expansion allowed for storageclass on AWS | boolean | true |
| monitoring.prometheus_server.pvc.annotations | Storage class annotations | map | {} |
| monitoring.prometheus_server.pvc.storage_class | Storage class to use for persistent volume claim. By default this is null and default provisioner is used | string | null |
| monitoring.prometheus_server.pvc.accessMode | Define access mode for persistent volume claim. Supported values: ReadWriteOnce, ReadOnlyMany, ReadWriteMany | string | ReadWriteOnce |
| monitoring.prometheus_server.pvc.storage | Define storage size for persistent volume claim | string | 8Gi |
| monitoring.prometheus_server.deployment.replicas | Number of prometheus replicas | integer | 1 |
| monitoring.prometheus_server.image.repository | Location of the repository with the Prometheus image. The default is the public VMware registry. Change this value if you are using a private repository (e.g., air-gapped environment). | string | projects.registry.vmware.com/tkg/prometheus |
| monitoring.prometheus_server.image.name | Name of Prometheus image | string | prometheus |
| monitoring.prometheus_server.image.tag | Prometheus image tag. This value may need to be updated if you are upgrading the version. | string | v2.17.1_vmware.1 |
| monitoring.prometheus_server.image.pullPolicy | Prometheus image pull policy | string | IfNotPresent |
| monitoring.alertmanager.config.slack_demo | Slack notification configuration for Alertmanager | string |
slack_demo:
name: slack_demo
slack_configs:
- api_url: https://hooks.slack.com
channel: '#alertmanager-test' |
| monitoring.alertmanager.config.email_receiver | Email notification configuration for Alertmanager | string | email_receiver: name: email-receiver email_configs: - to: [email protected] send_resolved: false from: [email protected] smarthost: smtp.eample.com:25 require_tls: false |
| monitoring.alertmanager.service.type | Type of service to expose Alertmanager. Supported Values: ClusterIP | string | ClusterIP |
| monitoring.alertmanager.image.repository | Location of the repository with the Alertmanager image. The default is the public VMware registry. Change this value if you are using a private repository (e.g., air-gapped environment). | string | projects.registry.vmware.com/tkg/prometheus |
| monitoring.alertmanager.image.name | Name of Alertmanager image | string | alertmanager |
| monitoring.alertmanager.image.tag | Alertmanager image tag. This value may need to be updated if you are upgrading the version. | string | v0.20.0_vmware.1 |
| monitoring.alertmanager.image.pullPolicy | Alertmanager image pull policy | string | IfNotPresent |
| monitoring.alertmanager.pvc.annotations | Storage class annotations | map | {} |
| monitoring.alertmanager.pvc.storage_class | Storage class to use for persistent volume claim. By default this is null and default provisioner is used. | string | null |
| monitoring.alertmanager.pvc.accessMode | Define access mode for persistent volume claim. Supported values: ReadWriteOnce, ReadOnlyMany, ReadWriteMany | string | ReadWriteOnce |
| monitoring.alertmanager.pvc.storage | Define storage size for persistent volume claim | string | 2Gi |
| monitoring.alertmanager.deployment.replicas | Number of alertmanager replicas | integer | 1 |
| monitoring.kube_state_metrics.image.repository | Repository containing kube-state-metircs image. The default is the public VMware registry. Change this value if you are using a private repository (e.g., air-gapped environment). | string | projects.registry.vmware.com/tkg/prometheus |
| monitoring.kube_state_metrics.image.name | Name of kube-state-metircs image | string | kube-state-metrics |
| monitoring.kube_state_metrics.image.tag | kube-state-metircs image tag. This value may need to be updated if you are upgrading the version. | string | v1.9.5_vmware.1 |
| monitoring.kube_state_metrics.image.pullPolicy | kube-state-metircs image pull policy | string | IfNotPresent |
| monitoring.kube_state_metrics.deployment.replicas | Number of kube-state-metrics replicas | integer | 1 |
| monitoring.node_exporter.image.repository | Repository containing node-exporter image. The default is the public VMware registry. Change this value if you are using a private repository (e.g., air-gapped environment). | string | projects.registry.vmware.com/tkg/prometheus |
| monitoring.node_exporter.image.name | Name of node-exporter image | string | node-exporter |
| monitoring.node_exporter.image.tag | node-exporter image tag. This value may need to be updated if you are upgrading the version. | string | v0.18.1_vmware.1 |
| monitoring.node_exporter.image.pullPolicy | node-exporter image pull policy | string | IfNotPresent |
| monitoring.node_exporter.hostNetwork | If set to `hostNetwork: true`, the pod can use the network namespace and network resources of the node. | boolean | false |
| monitoring.node_exporter.deployment.replicas | Number of node-exporter replicas | integer | 1 |
| monitoring.pushgateway.image.repository | Repository containing pushgateway image. The default is the public VMware registry. Change this value if you are using a private repository (e.g., air-gapped environment). | string | projects.registry.vmware.com/tkg/prometheus |
| monitoring.pushgateway.image.name | Name of pushgateway image | string | pushgateway |
| monitoring.pushgateway.image.tag | pushgateway image tag. This value may need to be updated if you are upgrading the version. | string | v1.2.0_vmware.1 |
| monitoring.pushgateway.image.pullPolicy | pushgateway image pull policy | string | IfNotPresent |
| monitoring.pushgateway.deployment.replicas | Number of pushgateway replicas | integer | 1 |
| monitoring.cadvisor.image.repository | Repository containing cadvisor image. The default is the public VMware registry. Change this value if you are using a private repository (e.g., air-gapped environment). | string | projects.registry.vmware.com/tkg/prometheus |
| monitoring.cadvisor.image.name | Name of cadvisor image | string | cadvisor |
| monitoring.cadvisor.image.tag | cadvisor image tag. This value may need to be updated if you are upgrading the version. | string | v0.36.0_vmware.1 |
| monitoring.cadvisor.image.pullPolicy | cadvisor image pull policy | string | IfNotPresent |
| monitoring.cadvisor.deployment.replicas | Number of cadvisor replicas | integer | 1 |
| monitoring.ingress.enabled | Enable/disable ingress for prometheus and alertmanager | boolean | false To use ingress, set this field to true and deploy [Contour](#). To access Prometheus, update your local /etc/hosts with an entry that maps prometheus.system.tanzu to a worker node IP address. |
| monitoring.ingress.virtual_host_fqdn | Hostname for accessing Prometheus and Alertmanager | string | prometheus.system.tanzu |
| monitoring.ingress.prometheus_prefix | Path prefix for prometheus | string | / |
| monitoring.ingress.alertmanager_prefix | Path prefix for alertmanager | string | /alertmanager/ |
| monitoring.ingress.tlsCertificate.tls.crt | Optional cert for ingress if you want to use your own TLS cert. A self signed cert is generated by default | string | Generated cert |
| monitoring.ingress.tlsCertificate.tls.key | Optional cert private key for ingress if you want to use your own TLS cert. | string | Generated cert key |
Prometheus Configuration Parameters (Standalone MC)
The following table lists configuration parameters of the Prometheus package and describes their default values.
You can set the following configuration values in your prometheus-data-values.yaml file.
To review and edit the Prometheus package’s current configuration parameters and values, retrieve its values schema:
tanzu package available get prometheus.tanzu.vmware.com/2.45.0+vmware.1-tkg.1 -n AVAILABLE-PACKAGE-NAMESPACE --values-schema
| Parameter | Description | Type | Default |
|---|---|---|---|
namespace |
Namespace where Prometheus will be deployed. | String | tanzu-system-monitoring |
prometheus.deployment.replicas |
Number of Prometheus replicas. | String | 1 |
prometheus.deployment.containers.args |
Prometheus container arguments. You can configure this parameter to change retention time. For information about configuring Prometheus storage parameters, see the Prometheus documentation. Note Longer retention times require more storage capacity than shorter retention times. It might be necessary to increase the persistent volume claim size if you are significantly increasing the retention time. | List | n/a |
prometheus.deployment.containers.resources |
Prometheus container resource requests and limits. | Map | {} |
prometheus.deployment.podAnnotations |
The Prometheus deployments pod annotations. | Map | {} |
prometheus.deployment.podLabels |
The Prometheus deployments pod labels. | Map | {} |
prometheus.deployment.configMapReload.containers.args |
Configmap-reload container arguments. | List | n/a |
prometheus.deployment.configMapReload.containers.resources |
Configmap-reload container resource requests and limits. | Map | {} |
prometheus.service.type |
Type of service to expose Prometheus. Supported Values: ClusterIP. |
String | ClusterIP |
prometheus.service.port |
Prometheus service port. | Integer | 80 |
prometheus.service.targetPort |
Prometheus service target port. | Integer | 9090 |
prometheus.service.labels |
Prometheus service labels. | Map | {} |
prometheus.service.annotations |
Prometheus service annotations. | Map | {} |
prometheus.pvc.annotations |
Storage class annotations. | Map | {} |
prometheus.pvc.storageClassName |
Storage class to use for persistent volume claim. By default this is null and default provisioner is used. | String | null |
prometheus.pvc.accessMode |
Define access mode for persistent volume claim. Supported values: ReadWriteOnce, ReadOnlyMany, ReadWriteMany. |
String | ReadWriteOnce |
prometheus.pvc.storage |
Define storage size for persistent volume claim. | String | 150Gi |
prometheus.config.prometheus_yml |
For information about the global Prometheus configuration, see the Prometheus documentation. | YAML file | prometheus.yaml |
prometheus.config.alerting_rules_yml |
For information about the Prometheus alerting rules, see the Prometheus documentation. | YAML file | alerting_rules.yaml |
prometheus.config.recording_rules_yml |
For information about the Prometheus recording rules, see the Prometheus documentation. | YAML file | recording_rules.yaml |
prometheus.config.alerts_yml |
Additional prometheus alerting rules are configured here. | YAML file | alerts_yml.yaml |
prometheus.config.rules_yml |
Additional prometheus recording rules are configured here. | YAML file | rules_yml.yaml |
alertmanager.deployment.replicas |
Number of alertmanager replicas. | Integer | 1 |
alertmanager.deployment.containers.resources |
Alertmanager container resource requests and limits. | Map | {} |
alertmanager.deployment.podAnnotations |
The Alertmanager deployments pod annotations. | Map | {} |
alertmanager.deployment.podLabels |
The Alertmanager deployments pod labels. | Map | {} |
alertmanager.service.type |
Type of service to expose Alertmanager. Supported Values: ClusterIP. |
String | ClusterIP |
alertmanager.service.port |
Alertmanager service port. | Integer | 80 |
alertmanager.service.targetPort |
Alertmanager service target port. | Integer | 9093 |
alertmanager.service.labels |
Alertmanager service labels. | Map | {} |
alertmanager.service.annotations |
Alertmanager service annotations. | Map | {} |
alertmanager.pvc.annotations |
Storage class annotations. | Map | {} |
alertmanager.pvc.storageClassName |
Storage class to use for persistent volume claim. By default this is null and default provisioner is used. | String | null |
alertmanager.pvc.accessMode |
Define access mode for persistent volume claim. Supported values: ReadWriteOnce, ReadOnlyMany, ReadWriteMany. |
String | ReadWriteOnce |
alertmanager.pvc.storage |
Define storage size for persistent volume claim. | String | 2Gi |
alertmanager.config.alertmanager_yml |
For information about the global YAML configuration for Alert Manager, see the Prometheus documentation. | YAML file | alertmanager_yml |
kube_state_metrics.deployment.replicas |
Number of kube-state-metrics replicas. | Integer | 1 |
kube_state_metrics.deployment.containers.resources |
kube-state-metrics container resource requests and limits. | Map | {} |
kube_state_metrics.deployment.podAnnotations |
The kube-state-metrics deployments pod annotations. | Map | {} |
kube_state_metrics.deployment.podLabels |
The kube-state-metrics deployments pod labels. | Map | {} |
kube_state_metrics.service.type |
Type of service to expose kube-state-metrics. Supported Values: ClusterIP. |
String | ClusterIP |
kube_state_metrics.service.port |
kube-state-metrics service port. | Integer | 80 |
kube_state_metrics.service.targetPort |
kube-state-metrics service target port. | Integer | 8080 |
kube_state_metrics.service.telemetryPort |
kube-state-metrics service telemetry port. | Integer | 81 |
kube_state_metrics.service.telemetryTargetPort |
kube-state-metrics service target telemetry port. | Integer | 8081 |
kube_state_metrics.service.labels |
kube-state-metrics service labels. | Map | {} |
kube_state_metrics.service.annotations |
kube-state-metrics service annotations. | Map | {} |
node_exporter.daemonset.replicas |
Number of node-exporter replicas. | Integer | 1 |
node_exporter.daemonset.containers.resources |
node-exporter container resource requests and limits. | Map | {} |
node_exporter.daemonset.hostNetwork |
Host networking requested for this pod. | boolean | false |
node_exporter.daemonset.podAnnotations |
The node-exporter deployments pod annotations. | Map | {} |
node_exporter.daemonset.podLabels |
The node-exporter deployments pod labels. | Map | {} |
node_exporter.service.type |
Type of service to expose node-exporter. Supported Values: ClusterIP. |
String | ClusterIP |
node_exporter.service.port |
node-exporter service port. | Integer | 9100 |
node_exporter.service.targetPort |
node-exporter service target port. | Integer | 9100 |
node_exporter.service.labels |
node-exporter service labels. | Map | {} |
node_exporter.service.annotations |
node-exporter service annotations. | Map | {} |
pushgateway.deployment.replicas |
Number of pushgateway replicas. | Integer | 1 |
pushgateway.deployment.containers.resources |
pushgateway container resource requests and limits. | Map | {} |
pushgateway.deployment.podAnnotations |
The pushgateway deployments pod annotations. | Map | {} |
pushgateway.deployment.podLabels |
The pushgateway deployments pod labels. | Map | {} |
pushgateway.service.type |
Type of service to expose pushgateway. Supported Values: ClusterIP. |
String | ClusterIP |
pushgateway.service.port |
pushgateway service port. | Integer | 9091 |
pushgateway.service.targetPort |
pushgateway service target port. | Integer | 9091 |
pushgateway.service.labels |
pushgateway service labels. | Map | {} |
pushgateway.service.annotations |
pushgateway service annotations. | Map | {} |
cadvisor.daemonset.replicas |
Number of cadvisor replicas. | Integer | 1 |
cadvisor.daemonset.containers.resources |
cadvisor container resource requests and limits. | Map | {} |
cadvisor.daemonset.podAnnotations |
The cadvisor deployments pod annotations. | Map | {} |
cadvisor.daemonset.podLabels |
The cadvisor deployments pod labels. | Map | {} |
ingress.enabled |
Activate/Deactivate ingress for prometheus and alertmanager. | Boolean | false |
ingress.virtual_host_fqdn |
Hostname for accessing promethues and alertmanager. | String | prometheus.system.tanzu |
ingress.prometheus_prefix |
Path prefix for prometheus. | String | / |
ingress.alertmanager_prefix |
Path prefix for alertmanager. | String | /alertmanager/ |
ingress.prometheusServicePort |
Prometheus service port to proxy traffic to. | Integer | 80 |
ingress.alertmanagerServicePort |
Alertmanager service port to proxy traffic to. | Integer | 80 |
ingress.tlsCertificate.tls.crt |
Optional certificate for ingress if you want to use your own TLS certificate. A self signed certificate is generated by default. Note tls.crt is a key and not nested. |
String | Generated cert |
ingress.tlsCertificate.tls.key |
Optional certificate private key for ingress if you want to use your own TLS certificate. Note tls.key is a key and not nested. |
String | Generated cert key |
ingress.tlsCertificate.ca.crt |
Optional CA certificate. Note ca.crt is a key and not nested. |
String | CA certificate |
Prometheus Server Configuration Parameters
You can set the following fields in the Prometheus Server ConfigMap.
| Parameter | Description | Type | Default |
|---|---|---|---|
| evaluation_interval | frequency to evaluate rules | duration | 1m |
| scrape_interval | frequency to scrape targets | duration | 1m |
| scrape_timeout | How long until a scrape request times out | duration | 10s |
| rule_files | Rule files specifies a list of globs. Rules and alerts are read from all matching files | yaml file | |
| scrape_configs | A list of scrape configurations. | list | |
| job_name | The job name assigned to scraped metrics by default | string | |
| kubernetes_sd_configs | List of Kubernetes service discovery configurations. | list | |
| relabel_configs | List of target relabel configurations. | list | |
| action | Action to perform based on regex matching. | string | |
| regex | Regular expression against which the extracted value is matched. | string | |
| source_labels | The source labels select values from existing labels. | string | |
| scheme | Configures the protocol scheme used for requests. | string | |
| tls_config | Configures the scrape request’s TLS settings. | string | |
| ca_file | CA certificate to validate API server certificate with. | filename | |
| insecure_skip_verify | Disable validation of the server certificate. | boolean | |
| bearer_token_file | Optional bearer token file authentication information. | filename | |
| replacement | Replacement value against which a regex replace is performed if the regular expression matches. | string | |
| target_label | Label to which the resulting value is written in a replace action. | string |
Alert Manager Configuration Parameters
You can set the following fields in the Alert Manager ConfigMap.
| Parameter | Description | Type | Default |
|---|---|---|---|
| resolve_timeout | ResolveTimeout is the default value used by alertmanager if the alert does not include EndsAt | duration | 5m |
| smtp_smarthost | The SMTP host through which emails are sent. | duration | 1m |
| slack_api_url | The Slack webhook URL. | string | global.slack_api_url |
| pagerduty_url | The pagerduty URL to send API requests to. | string | global.pagerduty_url |
| templates | Files from which custom notification template definitions are read | file path | |
| group_by | group the alerts by label | string | |
| group_interval | set time to wait before sending a notification about new alerts that are added to a group | duration | 5m |
| group_wait | How long to initially wait to send a notification for a group of alerts | duration | 30s |
| repeat_interval | How long to wait before sending a notification again if it has already been sent successfully for an alert | duration | 4h |
| receivers | A list of notification receivers. | list | |
| severity | Severity of the incident. | string | |
| channel | The channel or user to send notifications to. | string | |
| html | The HTML body of the email notification. | string | |
| text | The text body of the email notification. | string | |
| send_resolved | Whether or not to notify about resolved alerts. | filename | |
| email_configs | Configurations for email integration | boolean |
Prometheus Pod Annotations
Annotations on pods allow a fine control of the scraping process. These annotations must be part of the pod metadata. They will have no effect if set on other objects such as Services or DaemonSets.
| Pod Annotation | Description |
|---|---|
prometheus.io/scrape |
The default configuration will scrape all pods and, if set to false, this annotation will exclude the pod from the scraping process. |
prometheus.io/path |
If the metrics path is not /metrics, define it with this annotation. |
prometheus.io/port |
Scrape the pod on the indicated port instead of the pod’s declared ports (default is a port-free target if none are declared). |
The DaemonSet manifest below will instruct Prometheus to scrape all of its pods on port 9102.
apiVersion: apps/v1beta2 # for versions before 1.8.0 use extensions/v1beta1
kind: DaemonSet
metadata:
name: fluentd-elasticsearch
namespace: weave
labels:
app: fluentd-logging
spec:
selector:
matchLabels:
name: fluentd-elasticsearch
template:
metadata:
labels:
name: fluentd-elasticsearch
annotations:
prometheus.io/scrape: 'true'
prometheus.io/port: '9102'
spec:
containers:
- name: fluentd-elasticsearch
image: gcr.io/google-containers/fluentd-elasticsearch:1.20
Grafana Components
The Grafana package installs on the cluster the container listed in the table. For more information, see https://grafana.com/. The Grafana package pulls the container from the VMware public registry specified in Package Repository.
| Container | Resource Type | Replicas | Description |
|---|---|---|---|
| Grafana | Deployment | 2 | Data visualization |
Grafana Data Values
Below is an example grafana-data-values.yaml file with the following customizations:
- ingress is enabled (ingress: enabled: true)
- ingress is configured for URLs ending in / (prefix:)
- The FQDN for Grafana is grafana.system.tanzu (virtual_host_fqdn:)
- The pvc for grafana is 2GB and will be created under the default vSphere storageClass
- The secret: admin_user and admin_password are for the Grafana UI and both values must be base64 encoded (in the example, “admin” is used for each and base64 encoded; you should use secure credentials for your installation)
namespace: grafana-dashboard
grafana:
pspNames: "vmware-system-restricted"
deployment:
replicas: 1
updateStrategy: Recreate
pvc:
accessMode: ReadWriteOnce
storage: 2Gi
storageClassName: default
secret:
admin_user: YWRtaW4=
admin_password: YWRtaW4=
type: Opaque
service:
port: 80
targetPort: 3000
type: LoadBalancer
ingress:
enabled: true
prefix: /
servicePort: 80
virtual_host_fqdn: grafana.system.tanzu
Grafana Configuration Parameters (TKG on Supervisor)
The Grafana configuration is set in grafana-data-values.yaml. The table lists and describes the available parameters.
| Parameter | Description | Type | Default |
|---|---|---|---|
| monitoring.namespace | Namespace where Prometheus will be deployed | string | tanzu-system-monitoring |
| monitoring.create_namespace | The flag indicates whether to create the namespace specified by monitoring.namespace | boolean | false |
| monitoring.grafana.cluster_role.apiGroups | api group defined for grafana clusterrole | list | [""] |
| monitoring.grafana.cluster_role.resources | resources defined for grafana clusterrole | list | [“configmaps”, “secrets”] |
| monitoring.grafana.cluster_role.verbs | access permission defined for clusterrole | list | [“get”, “watch”, “list”] |
| monitoring.grafana.config.grafana_ini | Grafana configuration file details | config file | grafana.ini In this file, grafana_net URL is used to integrate with Grafana, for example, to import the dashboard directly from Grafana.com. |
| monitoring.grafana.config.datasource.type | Grafana datasource type | string | prometheus |
| monitoring.grafana.config.datasource.access | access mode. proxy or direct (Server or Browser in the UI) | string | proxy |
| monitoring.grafana.config.datasource.isDefault | mark as default Grafana datasource | boolean | true |
| monitoring.grafana.config.provider_yaml | Config file to define grafana dashboard provider | yaml file | provider.yaml |
| monitoring.grafana.service.type | Type of service to expose Grafana. Supported Values: ClusterIP, NodePort, LoadBalancer | string | vSphere: NodePort, aws/azure: LoadBalancer |
| monitoring.grafana.pvc.storage_class | Define access mode for persistent volume claim. Supported values: ReadWriteOnce, ReadOnlyMany, ReadWriteMany | string | ReadWriteOnce |
| monitoring.grafana.pvc.storage | Define storage size for persistent volume claim | string | 2Gi |
| monitoring.grafana.deployment.replicas | Number of grafana replicas | integer | 1 |
| monitoring.grafana.image.repository | Location of the repository with the Grafana image. The default is the public VMware registry. Change this value if you are using a private repository (e.g., air-gapped environment). | string | projects.registry.vmware.com/tkg/grafana |
| monitoring.grafana.image.name | Name of Grafana image | string | grafana |
| monitoring.grafana.image.tag | Grafana image tag. This value may need to be updated if you are upgrading the version. | string | v7.3.5_vmware.1 |
| monitoring.grafana.image.pullPolicy | Grafana image pull policy | string | IfNotPresent |
| monitoring.grafana.secret.type | Secret type defined for Grafana dashboard | string | Opaque |
| monitoring.grafana.secret.admin_user | username to access Grafana dashboard | string | YWRtaW4=Value is base64 encoded; to decode: echo "xxxxxx" | base64 --decode |
| monitoring.grafana.secret.admin_password | password to access Grafana dashboard | string | null |
| monitoring.grafana.secret.ldap_toml | If using ldap auth, ldap configuration file path | string | "" |
| monitoring.grafana_init_container.image.repository | Repository containing grafana init container image. The default is the public VMware registry. Change this value if you are using a private repository (e.g., air-gapped environment). | string | projects.registry.vmware.com/tkg/grafana |
| monitoring.grafana_init_container.image.name | Name of grafana init container image | string | k8s-sidecar |
| monitoring.grafana_init_container.image.tag | Grafana init container image tag. This value may need to be updated if you are upgrading the version. | string | 0.1.99 |
| monitoring.grafana_init_container.image.pullPolicy | grafana init container image pull policy | string | IfNotPresent |
| monitoring.grafana_sc_dashboard.image.repository | Repository containing the Grafana dashboard image. The default is the public VMware registry. Change this value if you are using a private repository (e.g., air-gapped environment). | string | projects.registry.vmware.com/tkg/grafana |
| monitoring.grafana_sc_dashboard.image.name | Name of grafana dashboard image | string | k8s-sidecar |
| monitoring.grafana_sc_dashboard.image.tag | Grafana dashboard image tag. This value may need to be updated if you are upgrading the version. | string | 0.1.99 |
| monitoring.grafana_sc_dashboard.image.pullPolicy | grafana dashboard image pull policy | string | IfNotPresent |
| monitoring.grafana.ingress.enabled | Enable/disable ingress for grafana | boolean | true |
| monitoring.grafana.ingress.virtual_host_fqdn | Hostname for accessing grafana | string | grafana.system.tanzu |
| monitoring.grafana.ingress.prefix | Path prefix for grafana | string | / |
| monitoring.grafana.ingress.tlsCertificate.tls.crt | Optional cert for ingress if you want to use your own TLS cert. A self signed cert is generated by default | string | Generated cert |
| monitoring.grafana.ingress.tlsCertificate.tls.key | Optional cert private key for ingress if you want to use your own TLS cert. | string | Generated cert key |
Grafana Configuration Parameters (Standalone MC)
The following table lists configuration parameters of the Grafana package and describes their default values.
You can set the following configuration values in your grafana-data-values.yaml file.
To review and edit the Grafana package’s current configuration parameters and values, retrieve its values schema:
tanzu package available get grafana.tanzu.vmware.com/10.0.1+vmware.1-tkg.1 -n AVAILABLE-PACKAGE-NAMESPACE --values-schema
| Parameter | Description | Type | Default |
|---|---|---|---|
| namespace | Namespace where Grafana will be deployed. | String | tanzu-system-dashboards |
| grafana.deployment.replicas | Number of Grafana replicas. | Integer | 1 |
| grafana.deployment.containers.resources | Grafana container resource requests and limits. | Map | {} |
| grafana.deployment.k8sSidecar.containers.resources | k8s-sidecar container resource requests and limits. | Map | {} |
| grafana.deployment.podAnnotations | The Grafana deployments pod annotations. | Map | {} |
| grafana.deployment.podLabels | The Grafana deployments pod labels. | Map | {} |
| grafana.service.type | Type of service to expose Grafana. Supported Values: ClusterIP, NodePort, LoadBalancer. (For vSphere set this to NodePort) |
String | LoadBalancer |
| grafana.service.port | Grafana service port. | Integer | 80 |
| grafana.service.targetPort | Grafana service target port. | Integer | 9093 |
| grafana.service.labels | Grafana service labels. | Map | {} |
| grafana.service.annotations | Grafana service annotations. | Map | {} |
| grafana.config.grafana_ini | For information about Grafana configuration, see Grafana Configuration Defaults in GitHub. | Config file | grafana.ini |
| grafana.config.datasource_yaml | For information about datasource config, see the Grafana documentation. | String | prometheus |
| grafana.config.dashboardProvider_yaml | For information about dashboard provider config, see the Grafana documentation. | YAML file | provider.yaml |
| grafana.pvc.annotations | Storage class to use for persistent volume claim. By default this is null and default provisioner is used. | String | null |
| grafana.pvc.storageClassName | Storage class to use for persistent volume claim. By default this is null and default provisioner is used. | String | null |
| grafana.pvc.accessMode | Define access mode for persistent volume claim. Supported values: ReadWriteOnce, ReadOnlyMany, ReadWriteMany. |
String | ReadWriteOnce |
| grafana.pvc.storage | Define storage size for persistent volume claim. | String | 2Gi |
| grafana.secret.type | Secret type defined for Grafana dashboard. | String | Opaque |
| grafana.secret.admin_user | Base64-encoded username to access Grafana dashboard. Defaults to YWRtaW4=, which is equivalent to admin in plain text. |
String | YWRtaW4= |
| grafana.secret.admin_password | Base64-encoded password to access Grafana dashboard. Defaults to YWRtaW4=, which is equivalent to admin in plain text. |
String | YWRtaW4= |
| ingress.enabled | Activate/Deactivate ingress for grafana. | Boolean | true |
| ingress.virtual_host_fqdn | Hostname for accessing grafana. | String | grafana.system.tanzu |
| ingress.prefix | Path prefix for grafana. | String | / |
| ingress.servicePort | Grafana service port to proxy traffic to. | Integer | 80 |
| ingress.tlsCertificate.tls.crt | Optional certificate for ingress if you want to use your own TLS cert. A self signed certificate is generated by default. Note tls.crt is a key and not nested. |
String | Generated cert |
| ingress.tlsCertificate.tls.key | Optional certificate private key for ingress if you want to use your own TLS certificate. Note tls.key is a key and not nested. |
String | Generated cert private key |
| ingress.tlsCertificate.ca.crt | Optional CA certificate. Note ca.crt is a key and not nested. |
String | CA certificate |
