









Tanzu Application Engine conceptual overview
This topic gives you an overview of Tanzu Application Engine and how it is used in Tanzu Platform for Kubernetes.
Tanzu Application Engine enables a separation of concerns and responsibilities between the people responsible for building an application platform (often platform engineers) and people deploying and using the platform (often application developers). To do this, Tanzu Application Engine relies on several key concepts that, when combined, provide the power of Tanzu Application Engine.
Spaces – repeatable application runtimes
Spaces act as the focal point where contributions from all of the individuals responsible for building an application platform combine to enable users to run their applications efficiently and effectively. From the perspective of a Space user, Spaces appear to be the equivalent of a Kubernetes namespace. That is to say, a container where applications and other resources are deployed that ensures boundaries such as permissions and networking discoverability.
From the perspective of the application platform builders, Spaces take the namespace concept and make it much more powerful. Spaces become a way to control which APIs are available to users, where applications are deployed and their level of availability, and a way to guarantee consistent use of platform-provided Capabilities.
The concepts that follow are how Spaces achieve this curated platform power.
Capabilities – platform APIs and features
Capabilities describe the APIs and features available from the platform, such as service-binding, ingress, fluxcd-helm. Depending on where they are referenced, Capabilities are used to achieve different things.
To curate the APIs that are available to users, platform engineers install packages on clusters. These packages provide APIs or custom resource definitions (CRDs) and their respective controllers on the cluster, which enables functionality on the cluster.
When a package that includes the capability.tanzu.vmware.com/provides annotation is installed on a cluster, that cluster is considered to provide a given Capability. Platform engineers are required to explicitly choose which Capabilities to provide, based on which Capability-providing packages they install. This enables them to control the types of workloads that can be installed on different clusters.
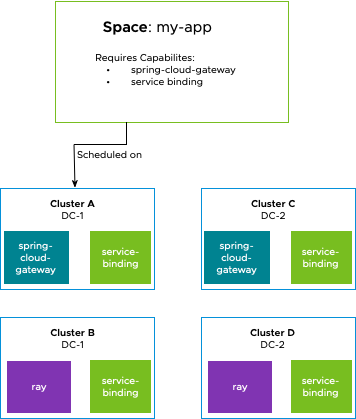
When an application operator creates a Space, the applications that are deployed to that Space can use the Capabilities that are provided by the platform. However, Spaces by default do not have access to any APIs, CRDs, or Capabilities on the platform. To make the Capabilities available to a Space, a Space author must require Capabilities. A Space with no required Capabilities means applications in it are not able to use any Capabilities.
A Space is scheduled on a cluster only if that cluster provides all of the Capabilities that the Space requires.
As an example, Spring Cloud Gateway is a Capability. A platform engineer at a company that uses Spring Cloud Gateway installs the Spring Cloud Gateway package on their clusters. The installation of this package installs various CRDs and controllers that can be used by other workloads on the cluster. The clusters have the ability to create Spring Cloud Gateways, by using the CRDs from the package, but no gateways are created yet.
Taking the example a bit further, if the platform engineer only installs the Spring Cloud Gateway on clusters designed for web application workloads and not their more expensive GPU clusters, they can ensure that web applications – which require Spring Cloud Gateway – will never land on their GPU clusters.
When a Space that requires the Spring Cloud Gateway Capability is created, the Space is scheduled only on a cluster that provides the Spring Cloud Gateway Capability. The Capability’s CRDs are exposed to workloads inside of the Space so that application developers that are pushing code to the Space can use the various CRDs for building gateways in the Space.
Cluster groups – consistent and reusable provided Capabilities
Cluster groups are groups of provided Capabilities and the clusters that they are installed on. With cluster groups, platform builders can manage all clusters, regardless of Kubernetes distribution, in a given cluster group in a consistent manner. Platform builders use cluster groups to manage their clusters at a fleet level, rather than on an individual basis. They are used to assign policies and install Capabilities.
Cluster groups install packages to provide Capabilities on clusters. More specifically, packages that have the capability.tanzu.vmware.com/provides annotation are Capability-providing packages. By using cluster groups to install Capability-providing packages, all clusters in a given cluster group provide the same Capabilities.
For example, a platform builder that is knowledgeable on how to deploy web applications might provide the spring-cloud-gateway and service-binding Capabilities in a web application cluster group. They are then able to add clusters across multiple cloud providers and regions, with clusters varying in both size and configuration. They do this knowing that all of these clusters will then have the same consistent set of packages installed on them and that they will all provide the same Capabilities for Spaces.
Cluster groups are intended to include many clusters. In the example above, the team building the platform is attempting to standardize the way that their organization configures clusters to support web applications. Therefore a TKG cluster and an EKS cluster should be in the same cluster group to ensure that they provide the same set of Capabilities.
This consistency enables teams to update the packages installed on their clusters (for example, to respond to a security vulnerability) and be confident that the updates are rolled out to all clusters in the cluster group.
Availability Targets – fault domains and locality
Availability Targets are groupings of clusters that allow developers to define where their application are scheduled. They can generally be thought of as named physical locations, but they are not limited to that.
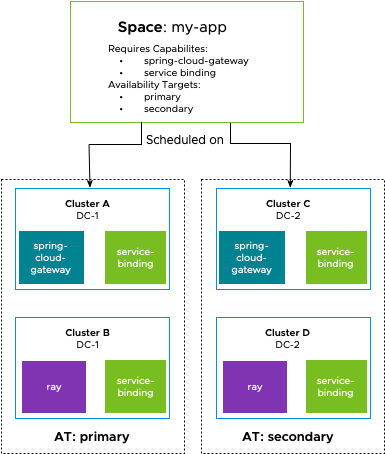
Spaces specify Availability Targets to describe where they should be scheduled. By including Availability Targets, rather than clusters, platform engineers can group clusters into logical groups that together provide Kubernetes capacity to run workloads. As a result, a Space creator can schedule a Space to a specific data center, site, or anything beyond, without ever needing to know which specific cluster it is running on.
For example, a common pattern is for customers to have several data centers in different cities, such as Las Vegas and Charlotte, to provide redundancy in case of a disaster. A platform builder who wants to easily enable application operators to run applications in their data centers might collect all clusters in their Las Vegas data center into a primary Availability Target and all clusters in their Charlotte data center into a secondary Availability Target.
An application team, that is unaware of the details of how their cloud footprint is structured and what they would need to do to be reliable, can include the primary and secondary Availability Targets for their Space and be assured that the platform is running their application on clusters in both data centers for them.
It is possible that no cluster exists in an Availability Target chosen by a Space. This is by design so that platform builders can prevent workloads, that the platform might not be prepared for, from running in these locations. To remedy this situation, the platform builder creates a new cluster for the appropriate Availability Target, adding it to the pool to be scheduled on.
Space scheduling
Tanzu Application Engine schedules Spaces onto clusters similar to how Kubernetes schedules pods onto nodes within a cluster. Because the platform is constantly watching for changes to clusters being created and deleted, which Capabilities are provided by those clusters, and what each Space’s configuration looks like, Application Engine is constantly recalculating and updating, if necessary, where a Space is scheduled.
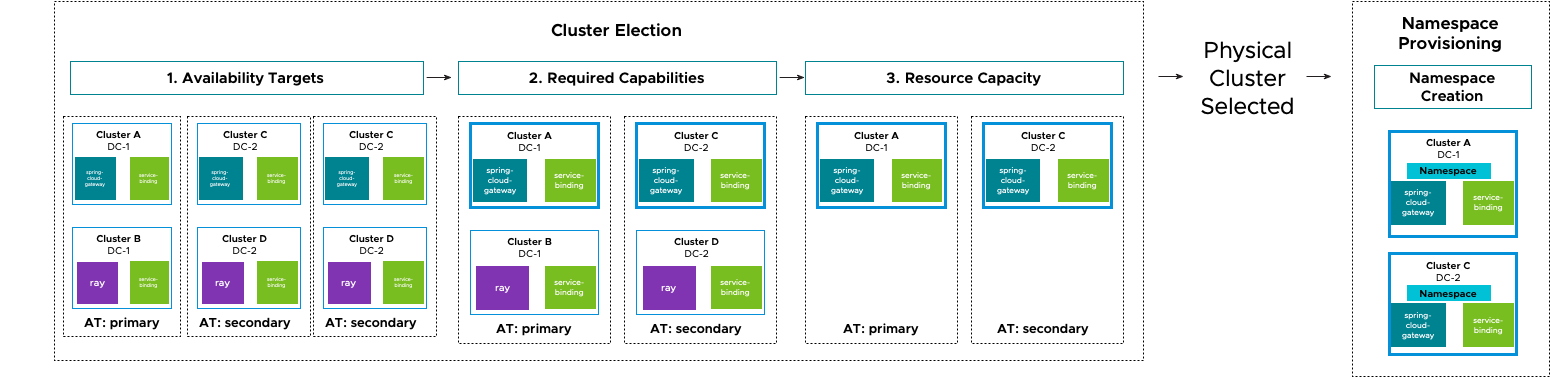
The required Capability and Availability Target metadata defined by each Space are passed through a multitier filtering algorithm to determine which clusters will host the Space’s contents. The algorithm looks roughly like this:
- For each requested Availability Target, select all clusters.
- Filter that list of clusters to only ones that provide all Capabilities required by the Space.
- Filter that list of clusters to only ones that have sufficient resource capacity (for example, CPU and RAM) to host the Space.
- From that list, select a cluster and assign it to the Space for use.
- Note that the selection process is a stable algorithm. When a cluster is selected, the same cluster will be selected unless it fails to meet one of the criteria above.
- Create a namespace on the assigned cluster and begin continuously syncing Space content.
Continuing the examples from above, when a Space creator creates a Space that includes the primary and secondary Availability Targets, and requires the Certificate Manager Capability, Tanzu Application Engine does the following:
- For the primary Availability Target find all of its clusters, which are Cluster A and Cluster B.
- Filter clusters that provide all of the Space’s required Capabilities, which is only Cluster A.
- Filter clusters with sufficient resource capacity for the Space. Because the Space did not set resource limits, Cluster A has enough capacity.
- Select a matching cluster from the above steps. In this case, Cluster A is the only matching cluster, but if there were more then Tanzu would select one from the list.
- Create a namespace on Cluster A and sync content from Tanzu to the cluster.
- Repeat the above steps for the secondary Availability Target.
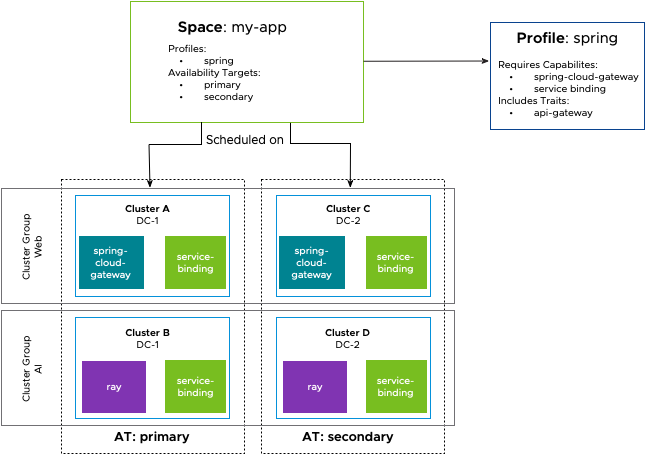
Profiles – consistent and reusable required Capabilities
Profiles are groups of required Capabilities. They are intended to be reusable building blocks for defining application environment characteristics. By creating custom Profiles, platform builders can curate the types of workloads that their platform supports while platform users can reference them to understand the APIs that are available on the platform.
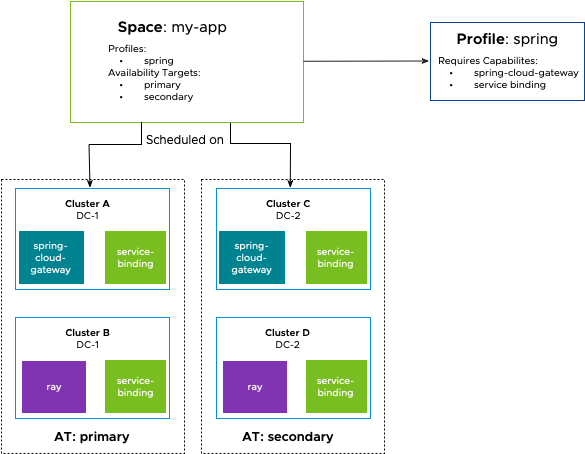
Spaces include Profiles to describe the APIs and CRDs (in the form of Capabilities) available in the Space. Spaces transitively require all Capabilities that are required by any Profiles a Space includes. A Space is scheduled only on a cluster that provides the required Capabilities of every Profile in by the Space.
For example, a platform builder who knows how to deploy Spring applications might require the spring-cloud-gateway and service-binding Capabilities in a Spring Profile. The Spring Profile provides a reusable way to create environments for running Spring applications.
A Spring application team can easily use the Spring Profile to create a Space in a way that is company-approved and guaranteed to be supported by the platform. The application team that needs a gateway in front of their application can use the Spring Cloud Gateway CRDs to create their own gateway.
Profiles are intended to be reused across Spaces. In the example above, the team building the platform is attempting to standardize the way that their organization runs Spring applications. Therefore, every Spring application should be running in a Space with the same Spring Profile. It is a common pattern for organizations to curate a limited set of Profiles that represent commonly used patterns and use cases.
Traits – consistent and reusable functionality
Traits are collections of Kubernetes resources that are deployed into Spaces when they are created. They deliver required, pre-configured, and consistent content to Spaces.
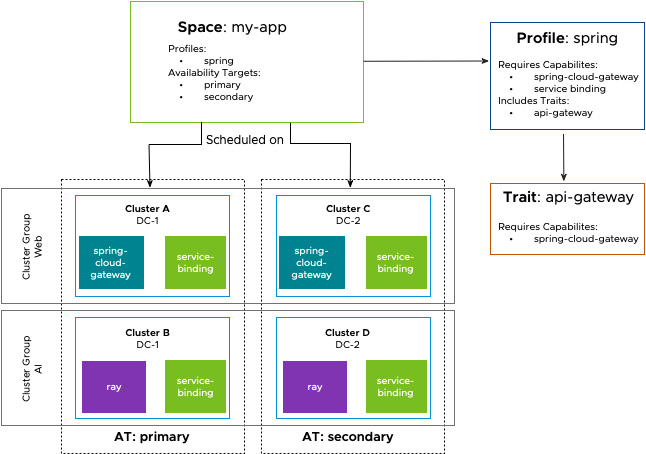
Profiles include Traits to easily create reusable content in Spaces when they are scheduled. This gives platform builders a way to simplify the configuration and creation of Kubernetes resources for their developers.
Continuing the example from above, the platform team notices that each team that uses the Spring Profile is re-implementing a way to create a Spring Cloud Gateway. They realize that this is not only inefficient, but also insecure as many teams do not send their network traffic through the company’s central audit tool.
To streamline developer flows and ensure the platform adheres to company security policy, a platform builder creates a Trait that contains a SpringCloudGateway resource with preconfigured connections to their auditing systems. They include the Trait in the Spring Profile that was previously created and used by various application teams. That change has now enabled every Space that uses the Spring Profile to use the newly created and company-approved Spring Cloud Gateway definition.
Traits are not intended to be the primary way to require Capabilities or to deliver Kubernetes resources into Spaces. In most cases, the content, like application-specific code being delivered into a Space, is unique enough that it should be delivered directly to the Space by running tanzu deploy.
For example, while many applications might use a database, few of them are connected to exactly the same database. In this case, the ServiceBinding for each database should be created and applied to the Space by running tanzu service create, and not as a templated reusable Trait. Most organizations have very few Traits that represent a small number of truly identical deliverables.
